Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias

0
📊
Sign in to get full access
Overview
- This study introduces a new benchmark framework called Cross-Care to assess biases and real-world knowledge in large language models (LLMs) regarding the representation of disease prevalence across diverse demographic groups.
- The researchers systematically evaluate how demographic biases embedded in pre-training corpora like The Pile influence the outputs of LLMs.
- The study exposes and quantifies discrepancies between LLM representation of disease prevalence and actual disease prevalence rates across different demographic subgroups in the U.S.
- The findings highlight substantial misalignment between LLM representation and real-world disease prevalence, indicating a risk of bias propagation and lack of grounding for medical applications of LLMs.
- The researchers make all data and a data visualization tool available for further exploration and analysis.
Plain English Explanation
Large language models (LLMs) are powerful tools for processing natural language, but they can also reflect biases and inaccuracies present in the data used to train them. This study focuses on how LLMs represent the prevalence of diseases across different demographic groups, such as age, gender, and race.
The researchers developed a new benchmark framework called Cross-Care to assess these biases and the real-world knowledge of LLMs. They compared the disease prevalence represented in the LLM outputs to actual disease prevalence data for various demographic groups in the United States.
The results showed significant discrepancies between the LLM representations and the real-world disease prevalence data. For example, the LLMs might overestimate the prevalence of a certain disease among one demographic group and underestimate it for another group, even though the actual prevalence rates are different.
This mismatch between the LLM representations and reality could lead to biased and inaccurate outputs, especially in medical applications where LLMs are used. The researchers warn that this lack of real-world grounding poses a significant risk of propagating biases and misinformation.
To help address these issues, the researchers have made all the data and a data visualization tool available for further exploration and analysis. This can help researchers, developers, and the public better understand and mitigate the biases in LLMs, particularly when they are used in sensitive domains like healthcare.
Technical Explanation
The researchers introduce the Cross-Care benchmark framework to assess the representation of disease prevalence across diverse demographic groups in large language models (LLMs). They systematically evaluate how demographic biases embedded in pre-training corpora like The Pile influence the outputs of LLMs.
The study leverages actual disease prevalence data from various U.S. demographic groups to expose and quantify discrepancies between the LLM representations and real-world prevalence rates. The researchers observe substantial misalignment, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs.
Furthermore, the researchers explore the impact of various alignment methods, such as demographic debiasing and medical-specific fine-tuning, on the models' representation of disease prevalence across different languages. However, they find that these methods only minimally resolve the inconsistencies.
The researchers make all data and a data visualization tool available at www.crosscare.net for further exploration and analysis.
Critical Analysis
The study's findings highlight a significant concern regarding the use of LLMs in healthcare applications. The substantial misalignment between the LLM representations of disease prevalence and the actual real-world prevalence rates across demographic subgroups suggests a fundamental lack of real-world grounding in these models.
This issue poses a serious risk of bias propagation, where the biases and inaccuracies present in the LLM outputs could be amplified and lead to potentially harmful consequences, especially in medical decision-making processes.
While the researchers explored various alignment methods, such as demographic debiasing and medical-specific fine-tuning, the limited impact of these approaches underscores the complexity of the problem. Addressing these biases may require more comprehensive strategies that go beyond just adjusting the training data or fine-tuning the models.
Additionally, the researchers focused on disease prevalence, but there may be other areas where LLMs exhibit biases that could also have significant implications for their use in healthcare and other sensitive domains. Further research is needed to explore the breadth and depth of these biases and develop more robust solutions to mitigate them.
Conclusion
This study highlights a crucial issue with the use of large language models (LLMs) in healthcare applications: the substantial misalignment between the LLM representations of disease prevalence and the actual real-world prevalence rates across demographic subgroups.
The findings expose the risk of bias propagation and the lack of real-world grounding in these models, which could have serious consequences when they are deployed in sensitive domains like medical decision-making. The limited impact of the explored alignment methods underscores the complexity of the problem and the need for more comprehensive strategies to address these biases.
The researchers' introduction of the Cross-Care benchmark framework and the availability of their data and visualization tools provide valuable resources for further exploration and analysis of these issues. Addressing the biases and inaccuracies in LLMs is crucial for ensuring their safe and ethical deployment, particularly in healthcare and other high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias
Shan Chen, Jack Gallifant, Mingye Gao, Pedro Moreira, Nikolaj Munch, Ajay Muthukkumar, Arvind Rajan, Jaya Kolluri, Amelia Fiske, Janna Hastings, Hugo Aerts, Brian Anthony, Leo Anthony Celi, William G. La Cava, Danielle S. Bitterman
Large language models (LLMs) are increasingly essential in processing natural languages, yet their application is frequently compromised by biases and inaccuracies originating in their training data. In this study, we introduce Cross-Care, the first benchmark framework dedicated to assessing biases and real world knowledge in LLMs, specifically focusing on the representation of disease prevalence across diverse demographic groups. We systematically evaluate how demographic biases embedded in pre-training corpora like $ThePile$ influence the outputs of LLMs. We expose and quantify discrepancies by juxtaposing these biases against actual disease prevalences in various U.S. demographic groups. Our results highlight substantial misalignment between LLM representation of disease prevalence and real disease prevalence rates across demographic subgroups, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs. Furthermore, we observe that various alignment methods minimally resolve inconsistencies in the models' representation of disease prevalence across different languages. For further exploration and analysis, we make all data and a data visualization tool available at: www.crosscare.net.
Read more5/10/2024
🌀
0
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Read more4/24/2024

0
GenderCARE: A Comprehensive Framework for Assessing and Reducing Gender Bias in Large Language Models
Kunsheng Tang, Wenbo Zhou, Jie Zhang, Aishan Liu, Gelei Deng, Shuai Li, Peigui Qi, Weiming Zhang, Tianwei Zhang, Nenghai Yu
Large language models (LLMs) have exhibited remarkable capabilities in natural language generation, but they have also been observed to magnify societal biases, particularly those related to gender. In response to this issue, several benchmarks have been proposed to assess gender bias in LLMs. However, these benchmarks often lack practical flexibility or inadvertently introduce biases. To address these shortcomings, we introduce GenderCARE, a comprehensive framework that encompasses innovative Criteria, bias Assessment, Reduction techniques, and Evaluation metrics for quantifying and mitigating gender bias in LLMs. To begin, we establish pioneering criteria for gender equality benchmarks, spanning dimensions such as inclusivity, diversity, explainability, objectivity, robustness, and realisticity. Guided by these criteria, we construct GenderPair, a novel pair-based benchmark designed to assess gender bias in LLMs comprehensively. Our benchmark provides standardized and realistic evaluations, including previously overlooked gender groups such as transgender and non-binary individuals. Furthermore, we develop effective debiasing techniques that incorporate counterfactual data augmentation and specialized fine-tuning strategies to reduce gender bias in LLMs without compromising their overall performance. Extensive experiments demonstrate a significant reduction in various gender bias benchmarks, with reductions peaking at over 90% and averaging above 35% across 17 different LLMs. Importantly, these reductions come with minimal variability in mainstream language tasks, remaining below 2%. By offering a realistic assessment and tailored reduction of gender biases, we hope that our GenderCARE can represent a significant step towards achieving fairness and equity in LLMs. More details are available at https://github.com/kstanghere/GenderCARE-ccs24.
Read more8/23/2024
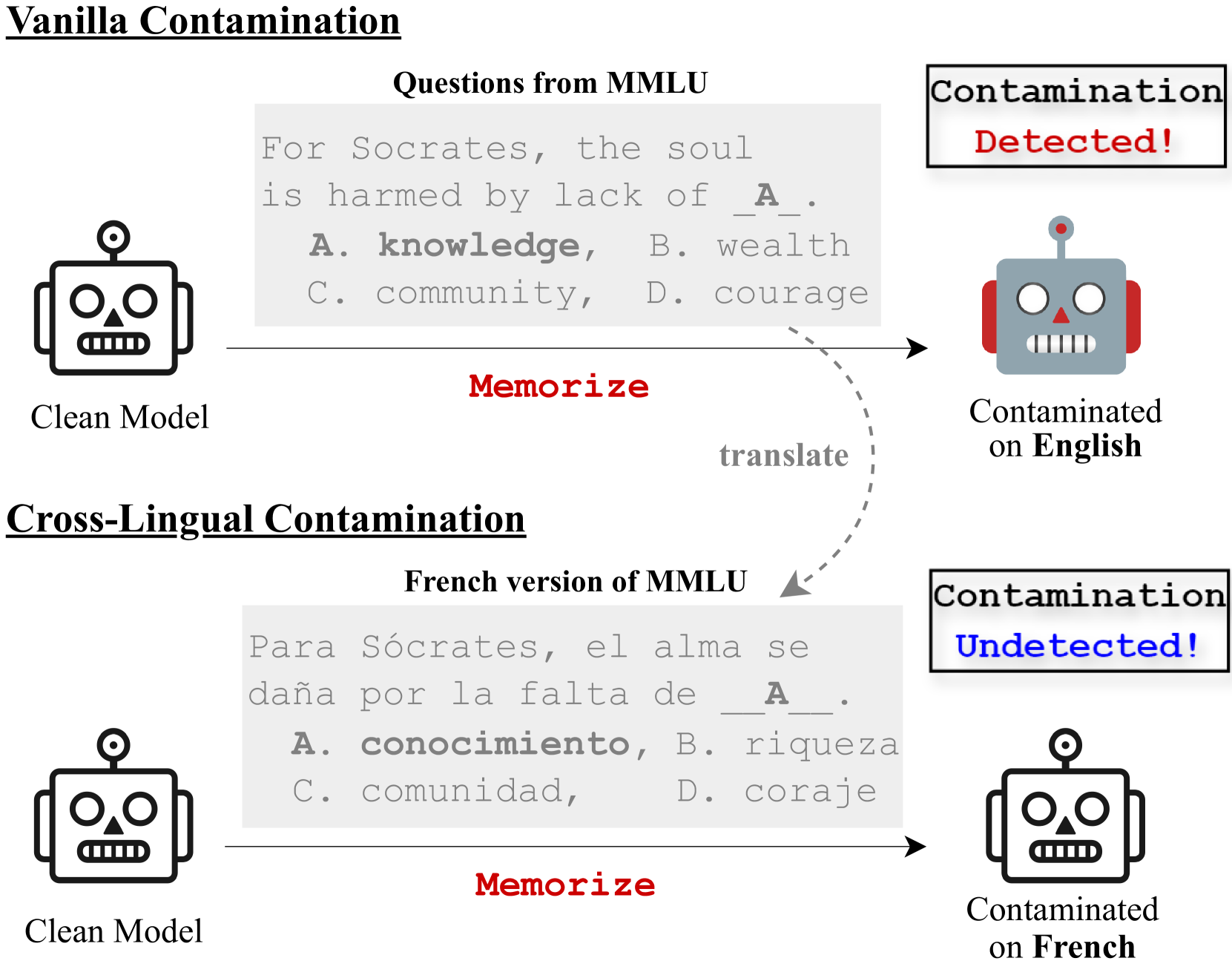
0
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
Read more6/21/2024