Generalization Error Bounds for Learning under Censored Feedback
2404.09247
0
0

Abstract
Generalization error bounds from learning theory provide statistical guarantees on how well an algorithm will perform on previously unseen data. In this paper, we characterize the impacts of data non-IIDness due to censored feedback (a.k.a. selective labeling bias) on such bounds. We first derive an extension of the well-known Dvoretzky-Kiefer-Wolfowitz (DKW) inequality, which characterizes the gap between empirical and theoretical CDFs given IID data, to problems with non-IID data due to censored feedback. We then use this CDF error bound to provide a bound on the generalization error guarantees of a classifier trained on such non-IID data. We show that existing generalization error bounds (which do not account for censored feedback) fail to correctly capture the model's generalization guarantees, verifying the need for our bounds. We further analyze the effectiveness of (pure and bounded) exploration techniques, proposed by recent literature as a way to alleviate censored feedback, on improving our error bounds. Together, our findings illustrate how a decision maker should account for the trade-off between strengthening the generalization guarantees of an algorithm and the costs incurred in data collection when future data availability is limited by censored feedback.
Create account to get full access
Overview
- This paper presents a theoretical analysis of the error bounds on cumulative distribution function (CDF) estimates, which are important for various applications in statistics and machine learning.
- The authors derive non-asymptotic error bounds for CDF estimates under different assumptions, including bounds for learning under graph dependence and bounds for classification and regression with inhomogeneous data.
- The results provide insights into the factors that influence the accuracy of CDF estimates, such as the sample size, the complexity of the underlying distribution, and the dependence structure of the data.
Plain English Explanation
The paper focuses on understanding the accuracy of cumulative distribution function (CDF) estimates, which are commonly used in statistics and machine learning. CDFs describe the probability that a random variable will be less than or equal to a certain value.
The authors derive mathematical formulas to quantify how much error or uncertainty we can expect in CDF estimates, based on factors like the number of data points, the complexity of the underlying distribution, and how the data points are related to each other.
For example, the results show that if the data points are independent of each other, we can get more accurate CDF estimates with fewer data points compared to when the data points are heavily dependent, like in graph-structured data. The paper also explores how the performance of CDF estimation is affected when the data has an inhomogeneous or uneven distribution.
Overall, this work provides a better theoretical understanding of the factors that influence the accuracy of CDF estimates, which is important for applications that rely on estimating probabilities from data, such as risk assessment and causal inference.
Technical Explanation
The paper derives non-asymptotic error bounds for cumulative distribution function (CDF) estimates under different assumptions. The authors consider both the case of independent data points and the case of data points with graph-structured dependence.
For independent data, the authors show that the error in the CDF estimate decreases as the square root of the sample size. They also provide bounds that depend on the complexity of the underlying distribution, as measured by its Lipschitz constant.
In the case of graph-structured dependence, the authors derive error bounds that depend on the graph structure, in addition to the sample size and distribution complexity. The results show that the error can be larger when the data points are highly dependent, compared to the independent case.
The paper also explores CDF estimation for classification and regression problems with inhomogeneous data. Here, the authors provide error bounds that take into account the uneven distribution of the data points in the feature space.
The theoretical results provide insights into the key factors that influence the accuracy of CDF estimates, which is important for applications such as risk assessment and causal inference.
Critical Analysis
The paper provides a thorough theoretical analysis of CDF estimation errors, considering various data dependence structures and distribution characteristics. The derived error bounds offer valuable insights into the practical challenges of accurate CDF estimation.
One potential limitation of the study is that the analysis relies on certain assumptions, such as the Lipschitz continuity of the underlying distribution. In real-world scenarios, the distribution may not always satisfy such strict assumptions, and it would be interesting to explore the robustness of the results to deviations from these assumptions.
Additionally, the paper focuses on non-asymptotic error bounds, which provide finite-sample guarantees. While this is an important perspective, it would also be helpful to understand the asymptotic behavior of the CDF estimators and how the error bounds scale as the sample size grows to infinity.
Furthermore, the authors do not provide any empirical validation of the theoretical results, which could strengthen the practical relevance of the work. Applying the derived bounds to real-world datasets and comparing the predicted errors with the actual performance would help bridge the gap between theory and practice.
Nevertheless, the theoretical insights presented in this paper are valuable and can inform the design of more accurate CDF estimation methods, particularly in applications where the data structure and distribution characteristics are well-understood.
Conclusion
This paper provides a rigorous theoretical analysis of the error bounds on cumulative distribution function (CDF) estimates, which are fundamental for a wide range of statistical and machine learning applications. The authors derive non-asymptotic error bounds under various assumptions, including independent data, graph-structured dependence, and inhomogeneous data distributions.
The results offer important insights into the key factors that influence the accuracy of CDF estimates, such as the sample size, the complexity of the underlying distribution, and the dependence structure of the data. These insights can guide the development of more robust and reliable CDF estimation techniques, with potential applications in areas like risk assessment, causal inference, and decision-making under uncertainty.
While the paper presents a comprehensive theoretical framework, further research could explore the empirical validation of the results, as well as the robustness of the error bounds to deviations from the assumed conditions. Nonetheless, this work contributes to a better understanding of the fundamental limits and trade-offs in CDF estimation, with implications for a wide range of fields that rely on accurate probabilistic modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Generalization Bounds for Causal Regression: Insights, Guarantees and Sensitivity Analysis
Daniel Csillag, Claudio Jos'e Struchiner, Guilherme Tegoni Goedert
0
0
Many algorithms have been recently proposed for causal machine learning. Yet, there is little to no theory on their quality, especially considering finite samples. In this work, we propose a theory based on generalization bounds that provides such guarantees. By introducing a novel change-of-measure inequality, we are able to tightly bound the model loss in terms of the deviation of the treatment propensities over the population, which we show can be empirically limited. Our theory is fully rigorous and holds even in the face of hidden confounding and violations of positivity. We demonstrate our bounds on semi-synthetic and real data, showcasing their remarkable tightness and practical utility.
5/16/2024
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
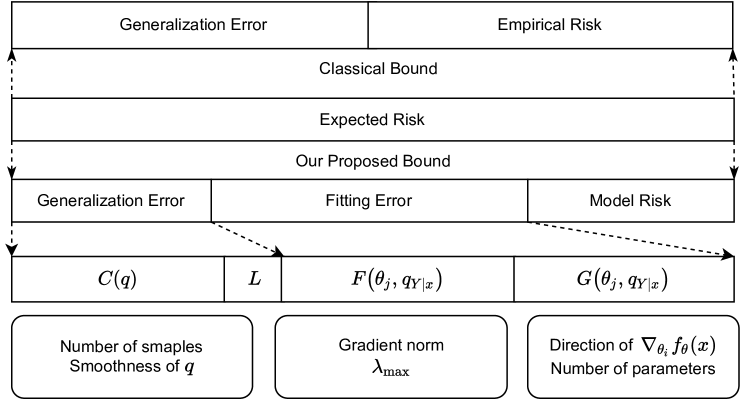
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
📊
Generalization Bounds for Dependent Data using Online-to-Batch Conversion
Sagnik Chatterjee, Manuj Mukherjee, Alhad Sethi
0
0
In this work, we give generalization bounds of statistical learning algorithms trained on samples drawn from a dependent data source, both in expectation and with high probability, using the Online-to-Batch conversion paradigm. We show that the generalization error of statistical learners in the dependent data setting is equivalent to the generalization error of statistical learners in the i.i.d. setting up to a term that depends on the decay rate of the underlying mixing stochastic process and is independent of the complexity of the statistical learner. Our proof techniques involve defining a new notion of stability of online learning algorithms based on Wasserstein distances and employing near-martingale concentration bounds for dependent random variables to arrive at appropriate upper bounds for the generalization error of statistical learners trained on dependent data.
5/24/2024

Information-Theoretic Generalization Bounds for Deep Neural Networks
Haiyun He, Christina Lee Yu, Ziv Goldfeld
0
0
Deep neural networks (DNNs) exhibit an exceptional capacity for generalization in practical applications. This work aims to capture the effect and benefits of depth for supervised learning via information-theoretic generalization bounds. We first derive two hierarchical bounds on the generalization error in terms of the Kullback-Leibler (KL) divergence or the 1-Wasserstein distance between the train and test distributions of the network internal representations. The KL divergence bound shrinks as the layer index increases, while the Wasserstein bound implies the existence of a layer that serves as a generalization funnel, which attains a minimal 1-Wasserstein distance. Analytic expressions for both bounds are derived under the setting of binary Gaussian classification with linear DNNs. To quantify the contraction of the relevant information measures when moving deeper into the network, we analyze the strong data processing inequality (SDPI) coefficient between consecutive layers of three regularized DNN models: Dropout, DropConnect, and Gaussian noise injection. This enables refining our generalization bounds to capture the contraction as a function of the network architecture parameters. Specializing our results to DNNs with a finite parameter space and the Gibbs algorithm reveals that deeper yet narrower network architectures generalize better in those examples, although how broadly this statement applies remains a question.
4/5/2024