Can LLM Graph Reasoning Generalize beyond Pattern Memorization?

0

Sign in to get full access
Overview
- This paper investigates whether large language models (LLMs) can perform structured graph reasoning beyond simply memorizing patterns in the training data.
- The researchers developed the NLGift benchmark to evaluate LLMs' ability to reason about graphs and solve graph-based tasks.
- The findings suggest that while LLMs can perform well on some graph reasoning tasks, they struggle to generalize beyond the specific patterns seen during training, indicating limitations in their reasoning capabilities.
Plain English Explanation
The paper looks at whether large language models (LLMs) like GPT-3 can truly reason about and understand graphs, or if they are just memorizing patterns they've seen before. Graphs are a way of representing relationships between different things, like how people are connected in a social network.
The researchers created a new benchmark called NLGift to test LLMs' graph reasoning abilities. They gave the models different graph-based tasks, like answering questions about the relationships between nodes in the graph. The key was to see if the models could apply their reasoning skills to new graphs they hadn't seen before, rather than just recalling patterns from their training data.
The results suggest that while LLMs can do reasonably well on some graph tasks, they struggle to truly generalize their reasoning beyond the specific examples they've been trained on. They seem to be relying more on memorization than genuine understanding of the underlying graph structures and relationships.
This indicates that current LLMs have limitations when it comes to structured, logical reasoning, and may not be able to handle complex real-world problems that require that kind of deep understanding. The researchers argue that to advance AI systems, we need to find ways to enhance their reasoning capabilities beyond just pattern matching.
Technical Explanation
The paper investigates the ability of large language models (LLMs) to perform structured graph reasoning beyond simply memorizing patterns in the training data. The researchers developed the NLGift benchmark to evaluate LLMs' capacity for graph reasoning.
NLGift consists of a suite of graph-based tasks that require models to understand and reason about the relationships between nodes in a graph. The tasks include answering questions about graph properties, generating explanations for graph relationships, and solving graph-based logical inference problems.
The researchers tested several state-of-the-art LLMs, including GPT-3, on the NLGift benchmark. The results showed that while the models performed reasonably well on some tasks, they struggled to generalize their reasoning beyond the specific patterns they had encountered during training. This suggests that current LLMs may be relying more on pattern memorization than genuine understanding of the underlying graph structures and relationships.
The paper highlights the limitations of LLMs in performing structured, logical reasoning, which is a crucial capability for handling complex real-world problems. The authors argue that to advance AI systems, we need to find ways to enhance their reasoning abilities beyond just pattern matching, such as through the development of enhanced prompt-based reasoning schemes or the integration of graph machine learning techniques with LLMs.
Critical Analysis
The paper provides a thoughtful and well-designed study of the limitations of LLMs in performing structured graph reasoning. The researchers' development of the NLGift benchmark is a valuable contribution, as it offers a standardized way to evaluate the reasoning capabilities of LLMs beyond simple pattern recognition.
However, the paper also acknowledges several caveats and areas for further research. For example, the authors note that the NLGift tasks may not capture the full range of reasoning skills required in real-world applications, and that more diverse and challenging benchmarks may be needed to truly push the boundaries of LLM reasoning.
Additionally, the paper does not delve deeply into the underlying mechanisms or architectural choices that may be contributing to the observed limitations in LLM graph reasoning. Exploring the reasoning capabilities of LLMs in the wild or enhancing their reasoning through prompt-based schemes could provide valuable insights into how to address these limitations.
Overall, the paper offers a thought-provoking and well-executed examination of the current state of LLM reasoning abilities, and it serves as a call to action for the AI research community to continue exploring ways to enhance the reasoning capabilities of large language models.
Conclusion
This paper highlights the limitations of current large language models (LLMs) in performing structured graph reasoning beyond simply memorizing patterns in the training data. The researchers developed the NLGift benchmark to assess LLMs' capacity for graph-based reasoning, and the results suggest that while LLMs can perform reasonably well on some tasks, they struggle to generalize their reasoning to new graph structures.
These findings underscore the need for continued research to enhance the reasoning capabilities of LLMs, moving beyond pattern matching towards genuine understanding of underlying relationships and logical structures. Exploring techniques like enhanced prompt-based reasoning schemes and integrating graph machine learning with LLMs may be promising avenues for advancing the state of the art in AI reasoning and problem-solving.
As the field of large language models and their reasoning capabilities continues to evolve, this paper serves as an important benchmark and a call to action for the research community to push the boundaries of what these models can achieve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can LLM Graph Reasoning Generalize beyond Pattern Memorization?
Yizhuo Zhang, Heng Wang, Shangbin Feng, Zhaoxuan Tan, Xiaochuang Han, Tianxing He, Yulia Tsvetkov
Large language models (LLMs) demonstrate great potential for problems with implicit graphical structures, while recent works seek to enhance the graph reasoning capabilities of LLMs through specialized instruction tuning. The resulting 'graph LLMs' are evaluated with in-distribution settings only, thus it remains underexplored whether LLMs are learning generalizable graph reasoning skills or merely memorizing patterns in the synthetic training data. To this end, we propose the NLGift benchmark, an evaluation suite of LLM graph reasoning generalization: whether LLMs could go beyond semantic, numeric, structural, reasoning patterns in the synthetic training data and improve utility on real-world graph-based tasks. Extensive experiments with two LLMs across four graph reasoning tasks demonstrate that while generalization on simple patterns (semantic, numeric) is somewhat satisfactory, LLMs struggle to generalize across reasoning and real-world patterns, casting doubt on the benefit of synthetic graph tuning for real-world tasks with underlying network structures. We explore three strategies to improve LLM graph reasoning generalization, and we find that while post-training alignment is most promising for real-world tasks, empowering LLM graph reasoning to go beyond pattern memorization remains an open research question.
Read more6/26/2024
0
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
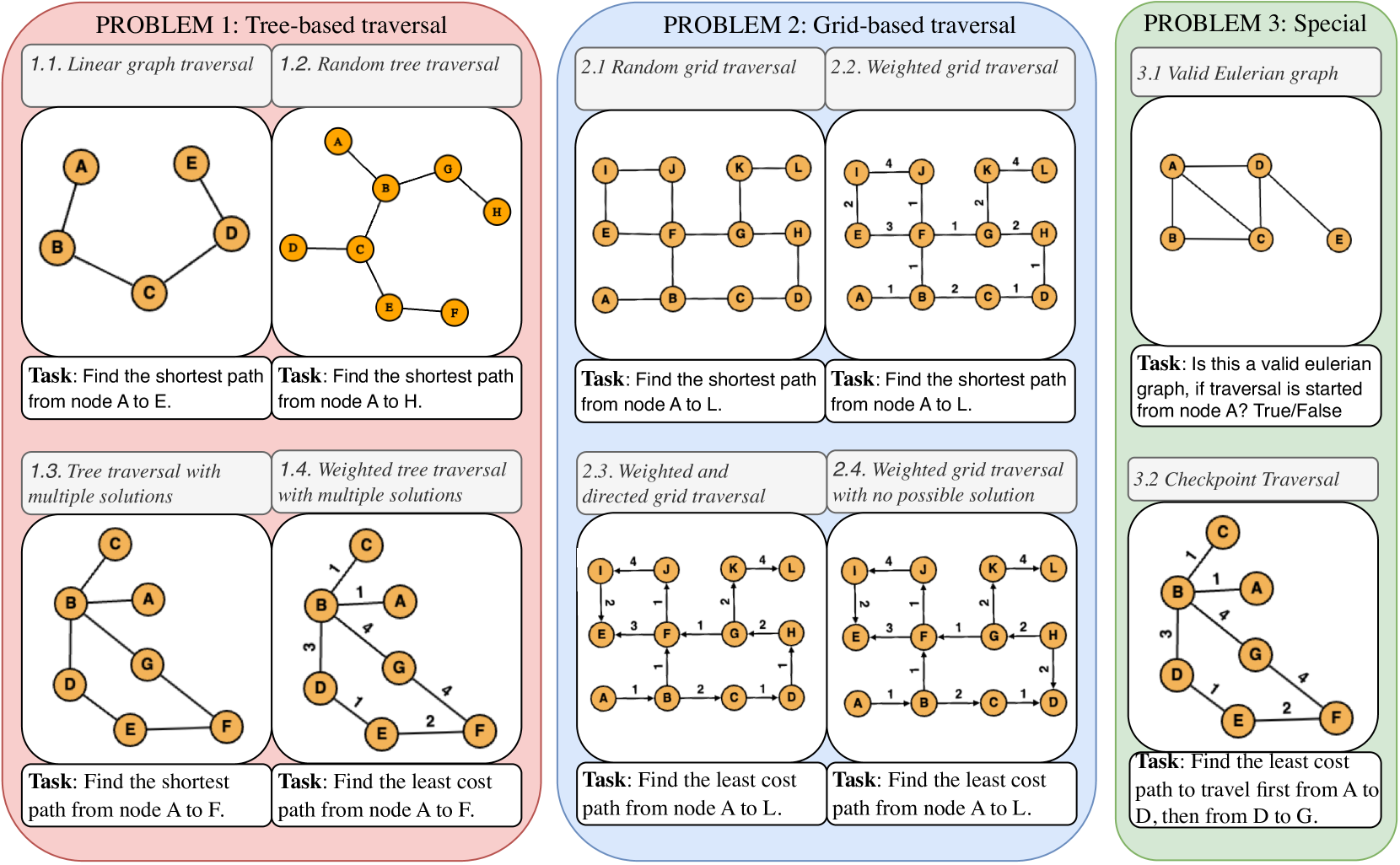
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
Read more8/30/2024
💬
0
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
Read more4/23/2024
💬
0
Graph Machine Learning in the Era of Large Language Models (LLMs)
Wenqi Fan, Shijie Wang, Jiani Huang, Zhikai Chen, Yu Song, Wenzhuo Tang, Haitao Mao, Hui Liu, Xiaorui Liu, Dawei Yin, Qing Li
Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. With the advent of deep learning, Graph Neural Networks (GNNs) have emerged as a cornerstone in Graph Machine Learning (Graph ML), facilitating the representation and processing of graph structures. Recently, LLMs have demonstrated unprecedented capabilities in language tasks and are widely adopted in a variety of applications such as computer vision and recommender systems. This remarkable success has also attracted interest in applying LLMs to the graph domain. Increasing efforts have been made to explore the potential of LLMs in advancing Graph ML's generalization, transferability, and few-shot learning ability. Meanwhile, graphs, especially knowledge graphs, are rich in reliable factual knowledge, which can be utilized to enhance the reasoning capabilities of LLMs and potentially alleviate their limitations such as hallucinations and the lack of explainability. Given the rapid progress of this research direction, a systematic review summarizing the latest advancements for Graph ML in the era of LLMs is necessary to provide an in-depth understanding to researchers and practitioners. Therefore, in this survey, we first review the recent developments in Graph ML. We then explore how LLMs can be utilized to enhance the quality of graph features, alleviate the reliance on labeled data, and address challenges such as graph heterogeneity and out-of-distribution (OOD) generalization. Afterward, we delve into how graphs can enhance LLMs, highlighting their abilities to enhance LLM pre-training and inference. Furthermore, we investigate various applications and discuss the potential future directions in this promising field.
Read more6/5/2024