Generative Powers of Ten
2312.02149
0
0
🗣️
Abstract
We present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content.
Create account to get full access
Overview
- This research proposes a method to generate consistent content across multiple image scales using a text-to-image model.
- The method enables "extreme semantic zooms" into a scene, from a wide-angle landscape view to a macro shot of a small object.
- It achieves this through a joint multi-scale diffusion sampling approach that maintains consistency across scales while preserving the integrity of each individual sampling process.
- Since each generated scale is guided by a different text prompt, the method can create deeper levels of zoom compared to traditional super-resolution techniques.
- The authors compare their method qualitatively with alternative image super-resolution and outpainting techniques, and claim their method is most effective at generating consistent multi-scale content.
Plain English Explanation
The researchers have developed a way to take a text description and generate a series of images that show the scene at different levels of zoom, from a wide landscape view all the way down to a close-up of a small detail. For example, you could start with a description of a forest, and the method would produce a series of images that first show the whole forest, then zoom in on a tree, then zoom in further to show an insect on one of the branches.
Typically, techniques that try to zoom in on an image and generate more detail struggle to maintain the overall context and consistency of the scene. But this new method uses a special "multi-scale diffusion" approach to keep the different zoom levels coherent and natural-looking, even as it generates completely new content at each scale based on the text prompts.
The key insight is that by having the text prompt guide the generation at each zoom level, the model can create richer and more plausible details than classic super-resolution methods, which are more limited in what new content they can add. The authors show through examples that this multi-scale text-to-image approach produces more consistent and realistic results compared to other state-of-the-art techniques.
Technical Explanation
The core of this research is a text-to-image generation method that can produce consistent content across multiple scales of a scene. The authors achieve this through a joint multi-scale diffusion sampling approach.
Specifically, the model takes a text prompt as input and generates a series of images at different scales, where each scale is guided by a different text prompt. For example, the initial prompt might describe a forest landscape, and the subsequent prompts would zoom in on specific elements like a tree or an insect.
The key innovation is that the model encourages consistency across these different scales by jointly optimizing the sampling process, rather than generating each scale independently. This helps preserve the overall integrity and coherence of the scene, even as new details are introduced at higher zoom levels.
The authors compare their approach to alternative techniques in image super-resolution and outpainting, and show that their method outperforms these baselines at generating consistent multi-scale content. This is because their text-guided generation process can create richer and more plausible details than classic super-resolution, which is more limited in the new content it can add.
Critical Analysis
The authors acknowledge that their method has some limitations. For example, they note that the multi-scale consistency is heavily dependent on the quality and coherence of the text prompts used to guide the generation at each scale. If the prompts are not carefully crafted, the final result may still lack seamless continuity.
Additionally, the authors do not provide a quantitative evaluation of their method's performance, relying instead on qualitative comparisons. While the visual examples are compelling, more rigorous benchmarking against other state-of-the-art techniques would help better assess the method's strengths and weaknesses.
Another potential concern is the computational complexity of the joint multi-scale diffusion sampling approach. Generating high-quality images at multiple scales simultaneously may be resource-intensive, which could limit the practical applicability of the method, especially for real-time or interactive use cases.
Despite these limitations, the research presents an intriguing and promising direction for generating illustrated instructions or other multi-scale visual content that requires consistent semantics across different levels of detail. Further refinement and validation of the approach could lead to valuable applications in fields like computer-aided design, scientific visualization, and interactive media.
Conclusion
This research proposes a novel text-to-image generation method that can produce consistent content across multiple scales of a scene, enabling "extreme semantic zooms" from wide-angle views to macro-level details. By using a joint multi-scale diffusion sampling approach guided by text prompts, the method can create richer and more plausible details than traditional super-resolution techniques.
While the approach has some limitations, such as its dependence on prompt quality and computational complexity, the research presents an exciting step forward in the field of multi-scale visual content generation. Further development and evaluation of this technique could lead to significant advancements in applications that require seamless zooming and consistent semantic understanding across different levels of detail.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Images Across Scales Using Adversarial Training
Krzysztof Wolski, Adarsh Djeacoumar, Alireza Javanmardi, Hans-Peter Seidel, Christian Theobalt, Guillaume Cordonnier, Karol Myszkowski, George Drettakis, Xingang Pan, Thomas Leimkuhler
0
0
The real world exhibits rich structure and detail across many scales of observation. It is difficult, however, to capture and represent a broad spectrum of scales using ordinary images. We devise a novel paradigm for learning a representation that captures an orders-of-magnitude variety of scales from an unstructured collection of ordinary images. We treat this collection as a distribution of scale-space slices to be learned using adversarial training, and additionally enforce coherency across slices. Our approach relies on a multiscale generator with carefully injected procedural frequency content, which allows to interactively explore the emerging continuous scale space. Training across vastly different scales poses challenges regarding stability, which we tackle using a supervision scheme that involves careful sampling of scales. We show that our generator can be used as a multiscale generative model, and for reconstructions of scale spaces from unstructured patches. Significantly outperforming the state of the art, we demonstrate zoom-in factors of up to 256x at high quality and scale consistency.
6/14/2024
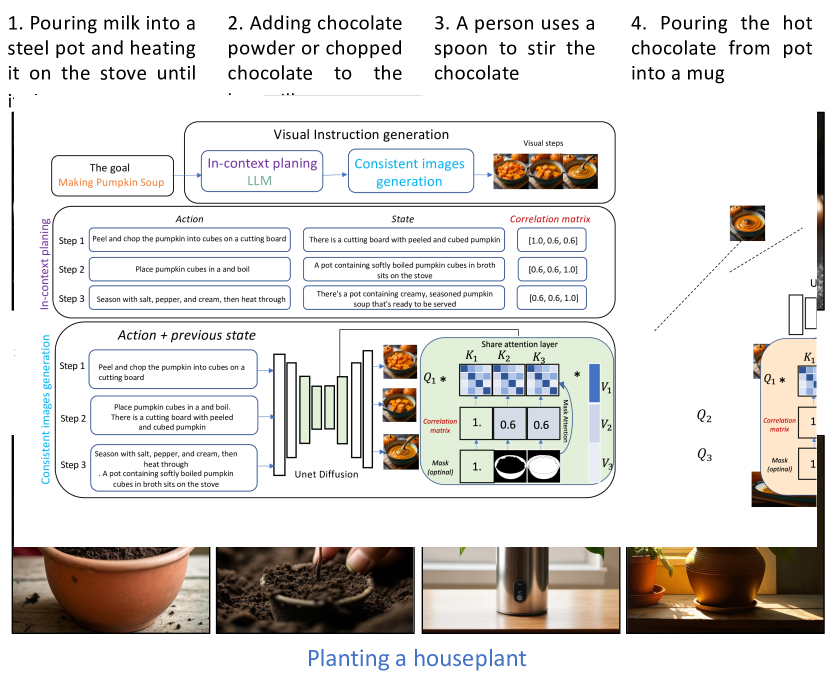
Coherent Zero-Shot Visual Instruction Generation
Quynh Phung, Songwei Ge, Jia-Bin Huang
0
0
Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
6/11/2024

Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
Cristina N. Vasconcelos, Abdullah Rashwan Austin Waters, Trevor Walker, Keyang Xu, Jimmy Yan, Rui Qian, Shixin Luo, Zarana Parekh, Andrew Bunner, Hongliang Fei, Roopal Garg, Mandy Guo, Ivana Kajic, Yeqing Li, Henna Nandwani, Jordi Pont-Tuset, Yasumasa Onoe, Sarah Rosston, Su Wang, Wenlei Zhou, Kevin Swersky, David J. Fleet, Jason M. Baldridge, Oliver Wang
0
0
We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
5/28/2024

Unified Text-to-Image Generation and Retrieval
Leigang Qu, Haochuan Li, Tan Wang, Wenjie Wang, Yongqi Li, Liqiang Nie, Tat-Seng Chua
0
0
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
6/11/2024