Genetic Quantization-Aware Approximation for Non-Linear Operations in Transformers
2403.19591
0
0
Abstract
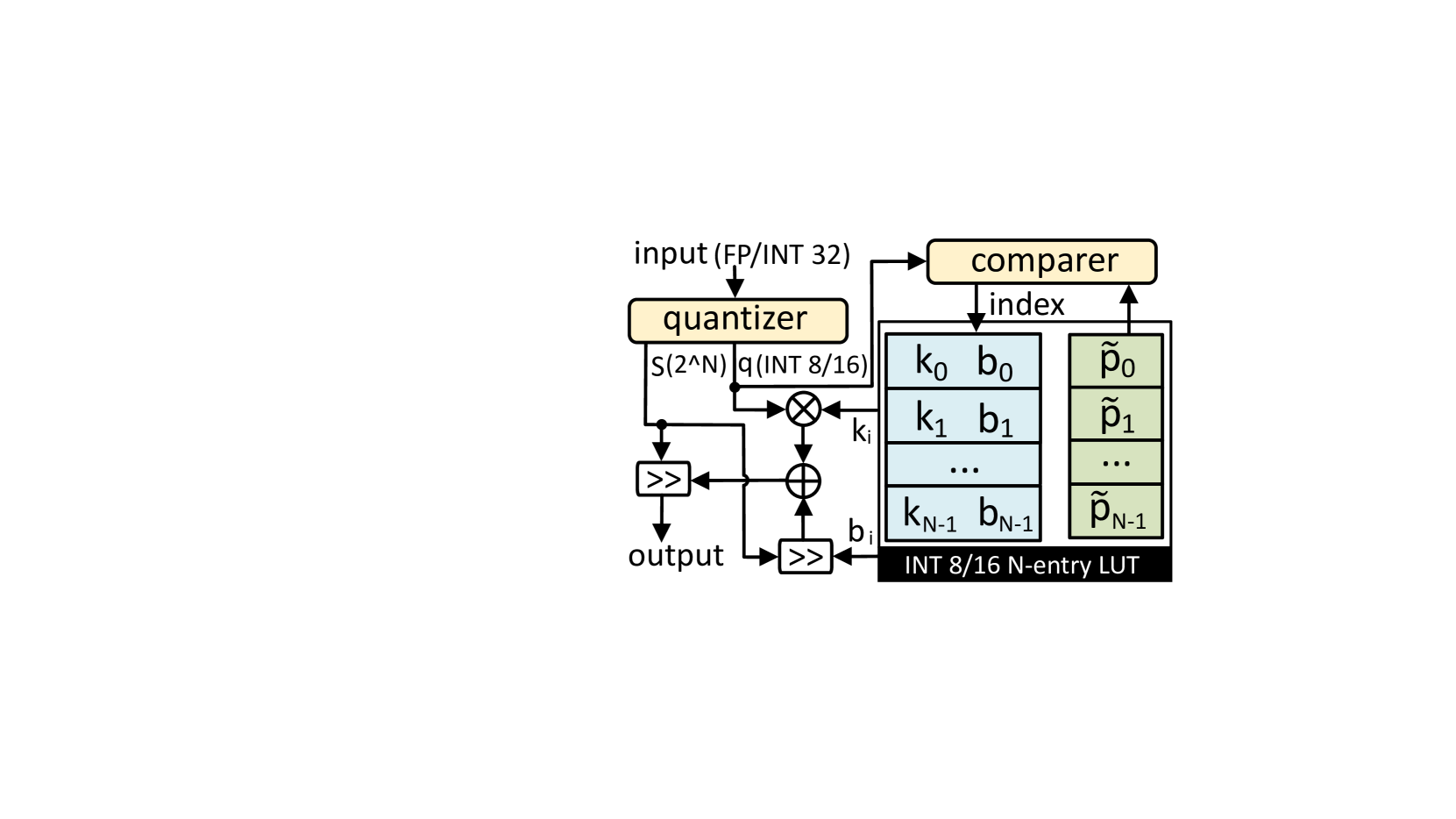
Non-linear functions are prevalent in Transformers and their lightweight variants, incurring substantial and frequently underestimated hardware costs. Previous state-of-the-art works optimize these operations by piece-wise linear approximation and store the parameters in look-up tables (LUT), but most of them require unfriendly high-precision arithmetics such as FP/INT 32 and lack consideration of integer-only INT quantization. This paper proposed a genetic LUT-Approximation algorithm namely GQA-LUT that can automatically determine the parameters with quantization awareness. The results demonstrate that GQA-LUT achieves negligible degradation on the challenging semantic segmentation task for both vanilla and linear Transformer models. Besides, proposed GQA-LUT enables the employment of INT8-based LUT-Approximation that achieves an area savings of 81.3~81.7% and a power reduction of 79.3~80.2% compared to the high-precision FP/INT 32 alternatives. Code is available at https:// github.com/PingchengDong/GQA-LUT.
Create account to get full access
Overview
- This paper presents a novel approach for approximating non-linear operations in Transformer models using a genetic algorithm-based quantization technique.
- The proposed method, called "Genetic Quantization-Aware Approximation" (GQAA), aims to reduce the computational cost and memory footprint of Transformer models while maintaining high performance.
- GQAA leverages a genetic algorithm to optimize the quantization parameters for non-linear operations, enabling the use of efficient integer-only arithmetic during inference.
Plain English Explanation
The paper focuses on improving the efficiency of Transformer models, which are a type of deep learning architecture commonly used for tasks like natural language processing and machine translation. Transformer models often rely on non-linear operations, such as activation functions, which can be computationally expensive and require a lot of memory.
The researchers developed a technique called "Genetic Quantization-Aware Approximation" (GQAA) to address this issue. GQAA uses a genetic algorithm to find the best way to represent these non-linear operations using a smaller, more efficient number format called quantization. By optimizing the quantization parameters, the researchers were able to create a version of the Transformer model that can perform these non-linear operations using only integer arithmetic, which is much faster and requires less memory than the standard floating-point arithmetic.
The key idea behind GQAA is to use a genetic algorithm to search for the optimal quantization parameters that can approximate the original non-linear operations with minimal loss in accuracy. This allows the model to run more efficiently on hardware, which is particularly important for deploying these models on resource-constrained devices, such as smartphones or edge computing devices.
Technical Explanation
The paper introduces the "Genetic Quantization-Aware Approximation" (GQAA) method for approximating non-linear operations in Transformer models. GQAA leverages a genetic algorithm to optimize the quantization parameters, enabling the use of efficient integer-only arithmetic during inference.
The authors first provide an overview of related work, including techniques for efficient large language models, mitigating the impact of outlier channels in model quantization, and exploring the potential of product quantization for deep neural networks.
The GQAA method works as follows:
- The non-linear operations in the Transformer model (e.g., activation functions) are replaced with look-up tables that approximate the original functions.
- A genetic algorithm is used to optimize the quantization parameters of these look-up tables, allowing the model to be represented using efficient integer-only arithmetic.
- During training, the quantization-aware approximation is incorporated into the model, enabling end-to-end optimization of the Transformer model and the approximation.
The authors evaluate GQAA on various Transformer-based tasks, including language modeling and machine translation. The results show that GQAA can achieve significant reductions in computational cost and memory footprint while maintaining high model performance.
Critical Analysis
The paper presents a novel and promising approach for improving the efficiency of Transformer models by approximating non-linear operations using a genetic algorithm-based quantization technique. The authors have carefully designed the GQAA method and provided thorough experimental evaluations to demonstrate its effectiveness.
One potential limitation of the GQAA approach is the reliance on a genetic algorithm, which can be computationally intensive and may require careful tuning of hyperparameters. The authors mention that the genetic algorithm optimization is performed during the training phase, which could add significant overhead to the training process. It would be interesting to see if there are any ways to further streamline the optimization process or to explore alternative optimization techniques that could be applied in a more efficient manner.
Additionally, the paper does not provide much insight into the interpretability or explainability of the GQAA-based approximations. It would be valuable to understand how the genetic algorithm-derived quantization parameters relate to the original non-linear operations and whether there are any insights that can be gained from this process.
Furthermore, the paper could benefit from a more in-depth discussion of the limitations and potential drawbacks of the GQAA approach. For example, the authors could explore scenarios where the approximations may not work well, such as when dealing with particularly complex or highly non-linear operations, or when the required precision is very high.
Despite these minor concerns, the paper presents a significant contribution to the field of efficient deep learning, particularly in the context of Transformer models. The GQAA method demonstrates the potential of leveraging genetic algorithms and quantization-aware training to optimize the computational and memory requirements of non-linear operations, which is a crucial aspect of modern deep learning architectures.
Conclusion
The "Genetic Quantization-Aware Approximation" (GQAA) method proposed in this paper is a promising approach for improving the efficiency of Transformer models by approximating non-linear operations using a genetic algorithm-based quantization technique. By optimizing the quantization parameters, the researchers were able to create a more compact and computationally efficient version of the Transformer model that can perform non-linear operations using only integer arithmetic.
The key significance of this work is the potential it holds for deploying large Transformer-based models on resource-constrained devices, such as smartphones or edge computing platforms. The ability to maintain high performance while significantly reducing the computational and memory requirements of these models could have far-reaching implications for a wide range of real-world applications, from natural language processing to machine translation.
Overall, the GQAA method represents an important step forward in the ongoing efforts to efficiently distill large language models for edge applications and mitigate the impact of outlier channels in model quantization. The authors have demonstrated the potential of exploring the potential of product quantization for deep neural networks and developing efficient large language models through compact representations, paving the way for further advancements in the field of efficient deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Low-Rank Quantization-Aware Training for LLMs
Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel
0
0
Large language models (LLMs) are omnipresent, however their practical deployment is challenging due to their ever increasing computational and memory demands. Quantization is one of the most effective ways to make them more compute and memory efficient. Quantization-aware training (QAT) methods, generally produce the best quantized performance, however it comes at the cost of potentially long training time and excessive memory usage, making it impractical when applying for LLMs. Inspired by parameter-efficient fine-tuning (PEFT) and low-rank adaptation (LoRA) literature, we propose LR-QAT -- a lightweight and memory-efficient QAT algorithm for LLMs. LR-QAT employs several components to save memory without sacrificing predictive performance: (a) low-rank auxiliary weights that are aware of the quantization grid; (b) a downcasting operator using fixed-point or double-packed integers and (c) checkpointing. Unlike most related work, our method (i) is inference-efficient, leading to no additional overhead compared to traditional PTQ; (ii) can be seen as a general extended pretraining framework, meaning that the resulting model can still be utilized for any downstream task afterwards; (iii) can be applied across a wide range of quantization settings, such as different choices quantization granularity, activation quantization, and seamlessly combined with many PTQ techniques. We apply LR-QAT to LLaMA-2/3 and Mistral model families and validate its effectiveness on several downstream tasks. Our method outperforms common post-training quantization (PTQ) approaches and reaches the same model performance as full-model QAT at the fraction of its memory usage. Specifically, we can train a 7B LLM on a single consumer grade GPU with 24GB of memory.
6/21/2024
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
0
0
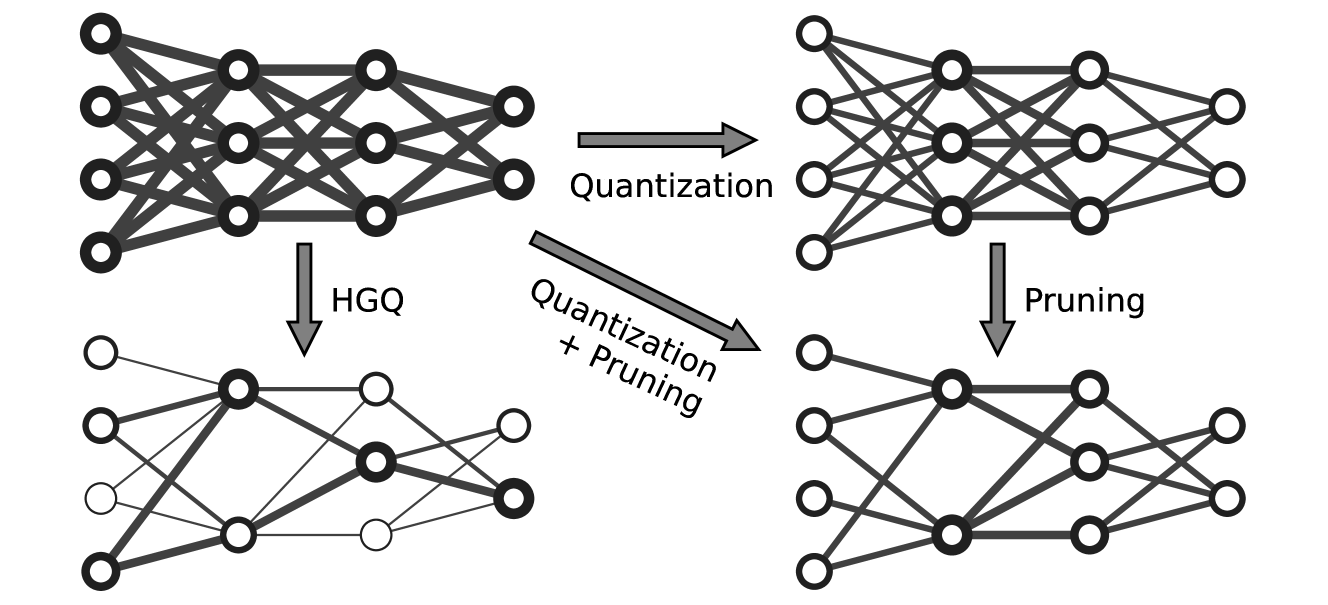
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
5/2/2024
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024
🤯
I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models
Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou
0
0
Post-training quantization (PTQ) serves as a potent technique to accelerate the inference of large language models (LLMs). Nonetheless, existing works still necessitate a considerable number of floating-point (FP) operations during inference, including additional quantization and de-quantization, as well as non-linear operators such as RMSNorm and Softmax. This limitation hinders the deployment of LLMs on the edge and cloud devices. In this paper, we identify the primary obstacle to integer-only quantization for LLMs lies in the large fluctuation of activations across channels and tokens in both linear and non-linear operations. To address this issue, we propose I-LLM, a novel integer-only fully-quantized PTQ framework tailored for LLMs. Specifically, (1) we develop Fully-Smooth Block-Reconstruction (FSBR) to aggressively smooth inter-channel variations of all activations and weights. (2) to alleviate degradation caused by inter-token variations, we introduce a novel approach called Dynamic Integer-only MatMul (DI-MatMul). This method enables dynamic quantization in full-integer matrix multiplication by dynamically quantizing the input and outputs with integer-only operations. (3) we design DI-ClippedSoftmax, DI-Exp, and DI-Normalization, which utilize bit shift to execute non-linear operators efficiently while maintaining accuracy. The experiment shows that our I-LLM achieves comparable accuracy to the FP baseline and outperforms non-integer quantization methods. For example, I-LLM can operate at W4A4 with negligible loss of accuracy. To our knowledge, we are the first to bridge the gap between integer-only quantization and LLMs. We've published our code on anonymous.4open.science, aiming to contribute to the advancement of this field.
6/6/2024