GenSafe: A Generalizable Safety Enhancer for Safe Reinforcement Learning Algorithms Based on Reduced Order Markov Decision Process Model

0

Sign in to get full access
Overview
- This paper presents GenSafe, a generalized framework for enhancing the safety of reinforcement learning (RL) algorithms.
- GenSafe uses a reduced-order Markov Decision Process (MDP) model to efficiently capture the safety constraints of the environment.
- The approach is designed to be compatible with a wide range of existing RL algorithms, making it a flexible and broadly applicable safety enhancement.
Plain English Explanation
GenSafe: A Generalizable Safety Enhancer for Safe Reinforcement Learning Algorithms Based on Reduced Order Markov Decision Process Model is a framework that aims to make reinforcement learning (RL) algorithms safer and more reliable. RL is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties.
The key idea behind GenSafe is to use a simplified, reduced-order model of the environment, called a Markov Decision Process (MDP), to identify and enforce safety constraints. This MDP model captures the essential dynamics of the environment in a more efficient way than the full, complex model. By incorporating this reduced-order MDP into the RL algorithm, GenSafe can help the agent learn to navigate the environment safely, without violating important constraints or causing unintended harm.
The beauty of GenSafe is that it is designed to be compatible with a wide range of existing RL algorithms. This means that researchers and developers can easily integrate GenSafe into their existing RL systems, without having to completely redesign or rewrite their code. This makes GenSafe a flexible and broadly applicable safety enhancement that can be used in a variety of real-world applications, such as robotics, autonomous vehicles, or healthcare.
Technical Explanation
The core of GenSafe is a reduced-order MDP model that captures the essential safety constraints of the environment. This reduced-order MDP is learned from data and used to guide the RL agent's decision-making process, ensuring that it avoids unsafe actions and stays within the bounds of the safety constraints.
The key steps in the GenSafe framework are:
- Construct a reduced-order MDP model of the environment using data collected from the full, complex MDP.
- Integrate the reduced-order MDP into the RL algorithm, using it to identify and enforce safety constraints during the learning process.
- Continuously update the reduced-order MDP model as the RL agent explores the environment, ensuring that the safety constraints remain up-to-date and relevant.
The authors demonstrate the effectiveness of GenSafe through experiments on various benchmark tasks, showing that it can significantly improve the safety and reliability of RL algorithms compared to traditional approaches. They also discuss how GenSafe can be combined with other safe RL techniques to further enhance the safety and performance of the overall system.
Critical Analysis
The GenSafe framework presents a promising approach to enhancing the safety of RL algorithms, but there are a few potential limitations and areas for further research:
-
The accuracy and reliability of the reduced-order MDP model are critical to the performance of GenSafe. If the model fails to capture important safety constraints or dynamics, it could lead to unsafe behaviors by the RL agent. More research is needed to understand the conditions under which the reduced-order model can be reliably learned and updated.
-
The paper does not explore the scalability of GenSafe to large-scale, high-dimensional environments. As the complexity of the environment increases, the challenges of constructing and maintaining an accurate reduced-order MDP model may become more pronounced.
-
While GenSafe is designed to be compatible with a wide range of RL algorithms, the authors do not provide a comprehensive evaluation of its performance across different RL approaches. Additional research is needed to understand how GenSafe interacts with and complements various RL techniques.
Overall, the GenSafe framework represents an important step forward in the pursuit of safe and reliable reinforcement learning. By leveraging a reduced-order MDP model, it offers a flexible and generalizable approach to enhancing the safety of RL systems. Further research and development in this area could lead to significant advancements in the real-world deployment of RL-based solutions.
Conclusion
The GenSafe framework presented in this paper offers a promising solution for enhancing the safety of reinforcement learning algorithms. By using a reduced-order Markov Decision Process model to capture the essential safety constraints of the environment, GenSafe can be easily integrated with a wide range of existing RL approaches to improve their reliability and safety.
The key strength of GenSafe is its generalizability, which allows it to be applied across various domains and applications, from robotics and autonomous vehicles to healthcare and beyond. As the use of RL continues to grow, frameworks like GenSafe will become increasingly important in ensuring that these powerful algorithms can be deployed safely and responsibly in the real world.
While the paper identifies some potential limitations and areas for further research, the overall approach of GenSafe represents an important advancement in the field of safe reinforcement learning. By combining flexible safety enhancements with existing RL techniques, this framework paves the way for more robust and trustworthy AI systems that can navigate complex environments while prioritizing safety and reliability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GenSafe: A Generalizable Safety Enhancer for Safe Reinforcement Learning Algorithms Based on Reduced Order Markov Decision Process Model
Zhehua Zhou, Xuan Xie, Jiayang Song, Zhan Shu, Lei Ma
Although deep reinforcement learning has demonstrated impressive achievements in controlling various autonomous systems, e.g., autonomous vehicles or humanoid robots, its inherent reliance on random exploration raises safety concerns in their real-world applications. To improve system safety during the learning process, a variety of Safe Reinforcement Learning (SRL) algorithms have been proposed, which usually incorporate safety constraints within the Constrained Markov Decision Process (CMDP) framework. However, the efficacy of these SRL algorithms often relies on accurate function approximations, a task that is notably challenging to accomplish in the early learning stages due to data insufficiency. To address this problem, we introduce a Genralizable Safety enhancer (GenSafe) in this work. Leveraging model order reduction techniques, we first construct a Reduced Order Markov Decision Process (ROMDP) as a low-dimensional proxy for the original cost function in CMDP. Then, by solving ROMDP-based constraints that are reformulated from the original cost constraints, the proposed GenSafe refines the actions taken by the agent to enhance the possibility of constraint satisfaction. Essentially, GenSafe acts as an additional safety layer for SRL algorithms, offering broad compatibility across diverse SRL approaches. The performance of GenSafe is examined on multiple SRL benchmark problems. The results show that, it is not only able to improve the safety performance, especially in the early learning phases, but also to maintain the task performance at a satisfactory level.
Read more6/7/2024

0
Reinforcement Learning in a Safety-Embedded MDP with Trajectory Optimization
Fan Yang, Wenxuan Zhou, Zuxin Liu, Ding Zhao, David Held
Safe Reinforcement Learning (RL) plays an important role in applying RL algorithms to safety-critical real-world applications, addressing the trade-off between maximizing rewards and adhering to safety constraints. This work introduces a novel approach that combines RL with trajectory optimization to manage this trade-off effectively. Our approach embeds safety constraints within the action space of a modified Markov Decision Process (MDP). The RL agent produces a sequence of actions that are transformed into safe trajectories by a trajectory optimizer, thereby effectively ensuring safety and increasing training stability. This novel approach excels in its performance on challenging Safety Gym tasks, achieving significantly higher rewards and near-zero safety violations during inference. The method's real-world applicability is demonstrated through a safe and effective deployment in a real robot task of box-pushing around obstacles.
Read more7/16/2024
🛠️
0
Learn With Imagination: Safe Set Guided State-wise Constrained Policy Optimization
Feihan Li, Yifan Sun, Weiye Zhao, Rui Chen, Tianhao Wei, Changliu Liu
Deep reinforcement learning (RL) excels in various control tasks, yet the absence of safety guarantees hampers its real-world applicability. In particular, explorations during learning usually results in safety violations, while the RL agent learns from those mistakes. On the other hand, safe control techniques ensure persistent safety satisfaction but demand strong priors on system dynamics, which is usually hard to obtain in practice. To address these problems, we present Safe Set Guided State-wise Constrained Policy Optimization (S-3PO), a pioneering algorithm generating state-wise safe optimal policies with zero training violations, i.e., learning without mistakes. S-3PO first employs a safety-oriented monitor with black-box dynamics to ensure safe exploration. It then enforces an imaginary cost for the RL agent to converge to optimal behaviors within safety constraints. S-3PO outperforms existing methods in high-dimensional robotics tasks, managing state-wise constraints with zero training violation. This innovation marks a significant stride towards real-world safe RL deployment.
Read more10/2/2024
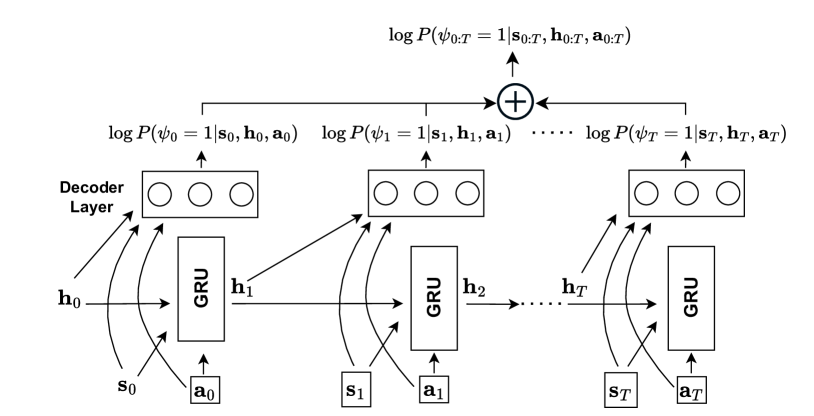
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024