Reinforcement Learning in a Safety-Embedded MDP with Trajectory Optimization

0

Sign in to get full access
Overview
- This paper proposes a novel reinforcement learning approach that integrates safety constraints into the Markov Decision Process (MDP) framework.
- The authors develop a "safety-embedded MDP" that explicitly models safety considerations during the learning process, allowing the agent to balance reward maximization with safety.
- The paper also presents a trajectory optimization algorithm to solve the safety-embedded MDP and generate safe and high-performing policies.
Plain English Explanation
In this research, the authors are exploring ways to make reinforcement learning systems more reliable and safe. Reinforcement learning is a type of machine learning where an agent (like a robot or software system) learns to make decisions by trial and error, trying to maximize some kind of reward signal. The challenge is that as the agent explores its environment and tries new actions, it can sometimes end up in unsafe or undesirable situations.
To address this, the researchers have proposed a new way of formulating the reinforcement learning problem, which they call a "safety-embedded MDP". The key idea is to explicitly model the safety considerations, alongside the traditional reward maximization objective, right within the Markov Decision Process (MDP) framework that underlies most reinforcement learning systems. This allows the agent to learn policies that balance the pursuit of rewards with the need to stay safe and avoid hazardous situations.
In addition, the paper presents a new trajectory optimization algorithm that can efficiently solve this safety-embedded MDP and generate policies that are both high-performing and safe. Trajectory optimization is a technique for finding the optimal sequence of actions (or "trajectory") that an agent should take to achieve its goals.
By combining this safety-embedded MDP formulation with the trajectory optimization algorithm, the researchers have developed a reinforcement learning system that can learn to make decisions that are not only rewarding, but also mindful of safety constraints. This could have important applications in areas like robotics, autonomous systems, and other high-stakes domains where the consequences of unsafe actions can be severe.
Technical Explanation
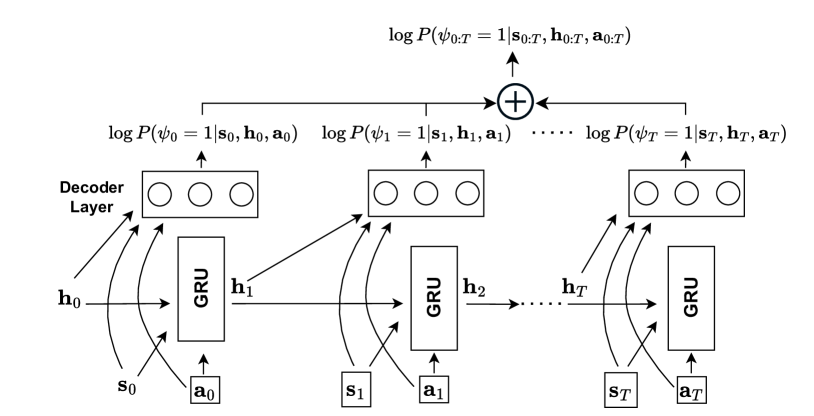
The key technical contribution of this paper is the formulation of a "safety-embedded Markov Decision Process (MDP)" that integrates safety considerations directly into the reinforcement learning framework. Traditionally, MDPs only model the reward or value function that the agent is trying to maximize. In the safety-embedded MDP proposed here, the authors introduce an additional "safety function" that encodes the safety or risk associated with each state and action.
This safety function is learned from data or specified by domain experts, and it is used to constrain the agent's exploration and decision-making. The agent is then trained to find policies that maximize the reward function while simultaneously satisfying the safety constraints imposed by the safety function.
To solve this safety-embedded MDP, the authors present a trajectory optimization algorithm that iteratively refines the agent's policy. The algorithm starts with an initial, potentially unsafe policy, and then uses a combination of reinforcement learning and constrained optimization techniques to gradually improve the policy while ensuring that safety constraints are met.
The authors evaluate their approach on several benchmark reinforcement learning tasks, including a challenging simulated quadrotor control problem. The results show that the safety-embedded MDP formulation and trajectory optimization algorithm can indeed learn policies that achieve high rewards while maintaining a high degree of safety, outperforming standard reinforcement learning baselines.
Critical Analysis
The key strength of this research is the principled way in which it integrates safety considerations into the reinforcement learning framework. By explicitly modeling safety as a first-class objective, alongside reward maximization, the authors have developed a flexible and generalizable approach that can be applied to a wide range of domains where safety is a critical concern.
However, one potential limitation of the proposed approach is the reliance on a pre-defined "safety function" that encodes the safety or risk of each state and action. In practice, accurately specifying or learning this safety function may be a significant challenge, especially in complex, high-dimensional environments. The authors acknowledge this issue and suggest that future work could explore ways to learn the safety function in a more data-driven manner.
Additionally, while the trajectory optimization algorithm presented in the paper is effective, it may not scale well to large, high-dimensional problems. The authors note that the computational complexity of the algorithm can be prohibitive, and further research may be needed to develop more efficient optimization techniques for solving the safety-embedded MDP.
Overall, this paper represents an important step forward in the field of safe reinforcement learning, building on related work in balancing reward and safety optimization, constrained multi-objective reinforcement learning, and safe reinforcement learning theory and applications. The safety-embedded MDP formulation and trajectory optimization algorithm presented here offer a promising approach for developing more reliable and trustworthy reinforcement learning systems, which will be crucial as these technologies are deployed in real-world, high-stakes applications.
Conclusion
This paper introduces a novel reinforcement learning framework that explicitly models safety considerations, alongside the traditional reward maximization objective, within the Markov Decision Process (MDP) formulation. The authors develop a "safety-embedded MDP" and present a trajectory optimization algorithm to solve this problem and generate safe and high-performing policies.
By integrating safety into the core of the reinforcement learning process, this research represents an important step towards more reliable and trustworthy autonomous systems. The results demonstrate the potential of this approach to balance reward maximization with safety constraints, which could have significant implications for a wide range of applications, from robotics and autonomous vehicles to healthcare and finance.
While the proposed techniques show promise, there are still challenges to be addressed, such as the accurate specification of the safety function and the scalability of the optimization algorithm. Nonetheless, this paper lays the groundwork for further advancements in the field of safe reinforcement learning, which will be crucial as these powerful AI systems are deployed in increasingly high-stakes and safety-critical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reinforcement Learning in a Safety-Embedded MDP with Trajectory Optimization
Fan Yang, Wenxuan Zhou, Zuxin Liu, Ding Zhao, David Held
Safe Reinforcement Learning (RL) plays an important role in applying RL algorithms to safety-critical real-world applications, addressing the trade-off between maximizing rewards and adhering to safety constraints. This work introduces a novel approach that combines RL with trajectory optimization to manage this trade-off effectively. Our approach embeds safety constraints within the action space of a modified Markov Decision Process (MDP). The RL agent produces a sequence of actions that are transformed into safe trajectories by a trajectory optimizer, thereby effectively ensuring safety and increasing training stability. This novel approach excels in its performance on challenging Safety Gym tasks, achieving significantly higher rewards and near-zero safety violations during inference. The method's real-world applicability is demonstrated through a safe and effective deployment in a real robot task of box-pushing around obstacles.
Read more7/16/2024
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024

0
Balance Reward and Safety Optimization for Safe Reinforcement Learning: A Perspective of Gradient Manipulation
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Ming Jin, Alois Knoll
Ensuring the safety of Reinforcement Learning (RL) is crucial for its deployment in real-world applications. Nevertheless, managing the trade-off between reward and safety during exploration presents a significant challenge. Improving reward performance through policy adjustments may adversely affect safety performance. In this study, we aim to address this conflicting relation by leveraging the theory of gradient manipulation. Initially, we analyze the conflict between reward and safety gradients. Subsequently, we tackle the balance between reward and safety optimization by proposing a soft switching policy optimization method, for which we provide convergence analysis. Based on our theoretical examination, we provide a safe RL framework to overcome the aforementioned challenge, and we develop a Safety-MuJoCo Benchmark to assess the performance of safe RL algorithms. Finally, we evaluate the effectiveness of our method on the Safety-MuJoCo Benchmark and a popular safe RL benchmark, Omnisafe. Experimental results demonstrate that our algorithms outperform several state-of-the-art baselines in terms of balancing reward and safety optimization.
Read more6/10/2024
🏅
0
Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Jonas Gunster, Puze Liu, Jan Peters, Davide Tateo
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
Read more9/24/2024