Geometry-guided Feature Learning and Fusion for Indoor Scene Reconstruction

0

Sign in to get full access
Overview
- The paper proposes a geometry-guided feature learning and fusion approach for indoor scene reconstruction.
- It aims to capture fine-grained details and achieve generalization across different environments.
- The method leverages both global and local geometric cues to learn robust features for scene reconstruction.
Plain English Explanation
The researchers developed a new technique for reconstructing the 3D environment inside buildings. Geometry-guided Feature Learning and Fusion for Indoor Scene Reconstruction focuses on capturing intricate details and being able to work well across different indoor spaces.
Their approach uses both broad, high-level geometric information as well as more localized geometric clues to learn effective visual features. This allows the system to build an accurate 3D model of the scene, including fine details like furniture and decorations. The key idea is that using this multi-scale geometric guidance helps the system learn representations that generalize better to new environments, rather than just memorizing the specific training data.
Technical Explanation
The paper presents a geometry-guided feature learning and fusion approach for indoor scene reconstruction. It leverages both global and local geometric cues to learn robust visual features that can capture fine-grained details and generalize well to new environments.
The proposed architecture consists of a geometric feature encoder that extracts features at multiple scales, and a fusion module that integrates these multi-scale features to produce the final 3D reconstruction. The geometric feature encoder uses a series of convolutional layers to extract both global and local geometric information from the input data.
The key insight is that this multi-scale geometric guidance helps the system learn more generalizable visual representations, compared to approaches that only use local or global cues. Through extensive experiments on indoor scene reconstruction benchmarks, the authors demonstrate that their method outperforms prior state-of-the-art techniques in terms of reconstruction quality and generalization ability.
Critical Analysis
The paper makes a convincing case for the benefits of integrating multi-scale geometric information for indoor scene reconstruction. The authors acknowledge that their approach still has limitations in handling highly cluttered or occluded scenes, and they suggest that incorporating additional cues like semantics or better handling of occlusions could further improve performance.
One potential area for future research would be exploring how this geometry-guided feature learning strategy could be extended to other 3D reconstruction tasks, such as outdoor scenes or object-level modeling. Additionally, investigating more efficient or lightweight architectural designs could make the approach more practical for real-world deployment.
Overall, this work presents a well-designed and empirically validated technique that advances the state-of-the-art in indoor scene reconstruction. The careful integration of multi-scale geometric information is a promising direction for building more robust and generalizable 3D perception systems.
Conclusion
The Geometry-guided Feature Learning and Fusion for Indoor Scene Reconstruction paper introduces an effective approach for reconstructing detailed 3D models of indoor environments. By leveraging both global and local geometric cues, the proposed method can learn visual features that capture fine-grained details and generalize well to new scenes.
This research represents an important step forward in building 3D perception systems that can reliably operate in complex, real-world indoor settings. The insights gained from this work could also inspire future developments in other 3D reconstruction and scene understanding tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Geometry-guided Feature Learning and Fusion for Indoor Scene Reconstruction
Ruihong Yin, Sezer Karaoglu, Theo Gevers
In addition to color and textural information, geometry provides important cues for 3D scene reconstruction. However, current reconstruction methods only include geometry at the feature level thus not fully exploiting the geometric information. In contrast, this paper proposes a novel geometry integration mechanism for 3D scene reconstruction. Our approach incorporates 3D geometry at three levels, i.e. feature learning, feature fusion, and network supervision. First, geometry-guided feature learning encodes geometric priors to contain view-dependent information. Second, a geometry-guided adaptive feature fusion is introduced which utilizes the geometric priors as a guidance to adaptively generate weights for multiple views. Third, at the supervision level, taking the consistency between 2D and 3D normals into account, a consistent 3D normal loss is designed to add local constraints. Large-scale experiments are conducted on the ScanNet dataset, showing that volumetric methods with our geometry integration mechanism outperform state-of-the-art methods quantitatively as well as qualitatively. Volumetric methods with ours also show good generalization on the 7-Scenes and TUM RGB-D datasets.
Read more8/29/2024
🧠
0
Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
Tianqi Liu, Xinyi Ye, Min Shi, Zihao Huang, Zhiyu Pan, Zhan Peng, Zhiguo Cao
Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
Read more4/29/2024

0
Geometry-aware Feature Matching for Large-Scale Structure from Motion
Gonglin Chen, Jinsen Wu, Haiwei Chen, Wenbin Teng, Zhiyuan Gao, Andrew Feng, Rongjun Qin, Yajie Zhao
Establishing consistent and dense correspondences across multiple images is crucial for Structure from Motion (SfM) systems. Significant view changes, such as air-to-ground with very sparse view overlap, pose an even greater challenge to the correspondence solvers. We present a novel optimization-based approach that significantly enhances existing feature matching methods by introducing geometry cues in addition to color cues. This helps fill gaps when there is less overlap in large-scale scenarios. Our method formulates geometric verification as an optimization problem, guiding feature matching within detector-free methods and using sparse correspondences from detector-based methods as anchor points. By enforcing geometric constraints via the Sampson Distance, our approach ensures that the denser correspondences from detector-free methods are geometrically consistent and more accurate. This hybrid strategy significantly improves correspondence density and accuracy, mitigates multi-view inconsistencies, and leads to notable advancements in camera pose accuracy and point cloud density. It outperforms state-of-the-art feature matching methods on benchmark datasets and enables feature matching in challenging extreme large-scale settings.
Read more9/14/2024
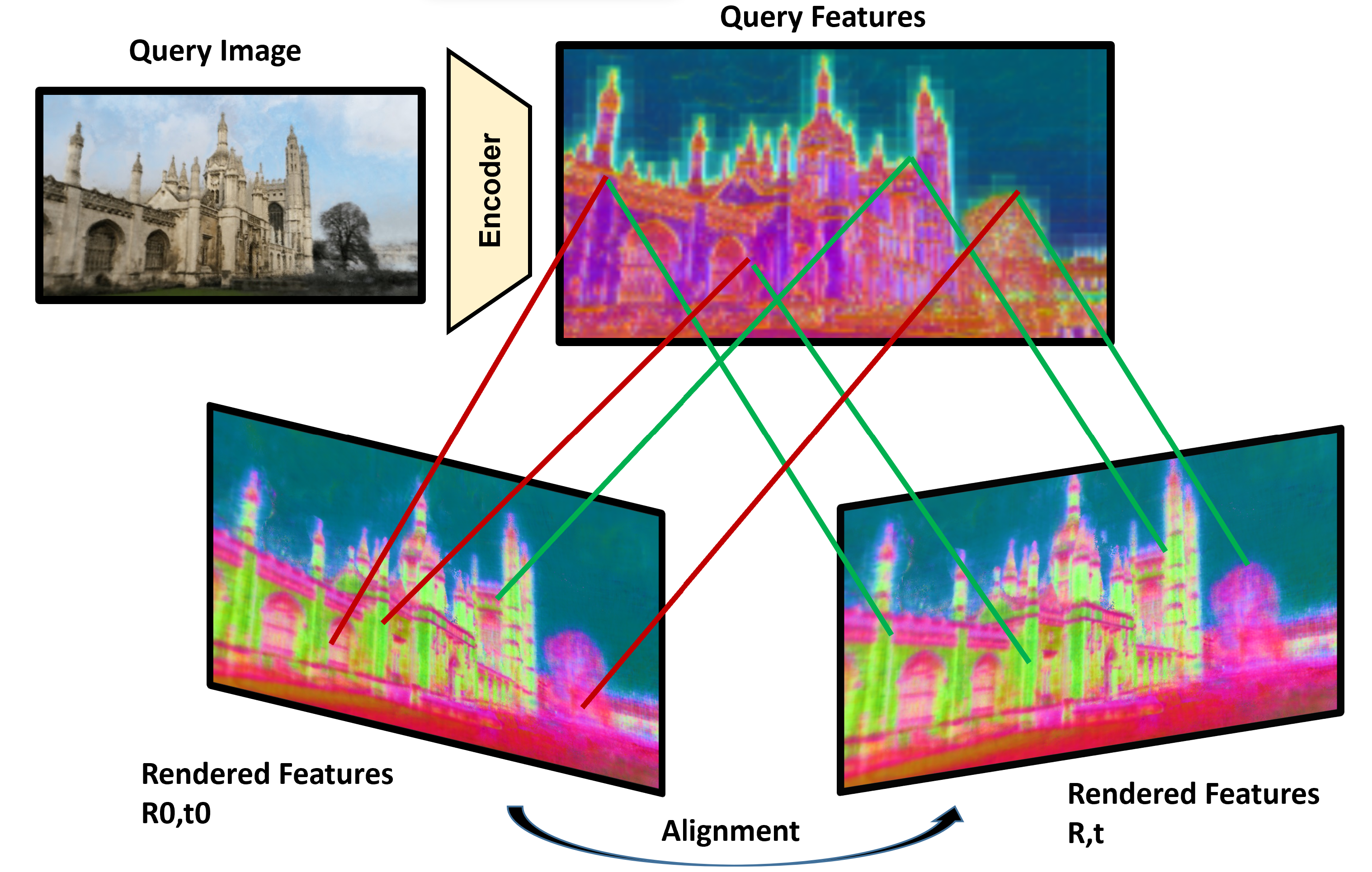
0
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
Read more6/13/2024