GeoReasoner: Reasoning On Geospatially Grounded Context For Natural Language Understanding

0
Sign in to get full access
Overview
- The paper presents GeoReasoner, a novel approach for natural language understanding that leverages geospatial context.
- GeoReasoner aims to improve language models' ability to reason about the world by grounding their understanding in spatial information.
- The system combines large language models with geospatial data and reasoning capabilities to enhance natural language processing.
Plain English Explanation
The paper introduces GeoReasoner, a new way to help computers better understand natural language by using information about locations and geography. Large language models, which are powerful AI systems trained on a vast amount of text, can sometimes struggle to fully grasp the real-world meaning behind the words people use.
By incorporating geospatial data and reasoning techniques, GeoReasoner seeks to ground the language models' understanding in the physical world. This could allow the models to better comprehend the spatial context and implications of what people are saying, leading to more accurate and meaningful natural language processing.
For example, if someone mentions "the park down the street," GeoReasoner could use information about the local area's geography to identify the specific park they are referring to, rather than relying solely on the textual description. This type of geospatial reasoning can be helpful for a wide range of language understanding tasks, such as question answering, dialogue systems, and content summarization.
Technical Explanation
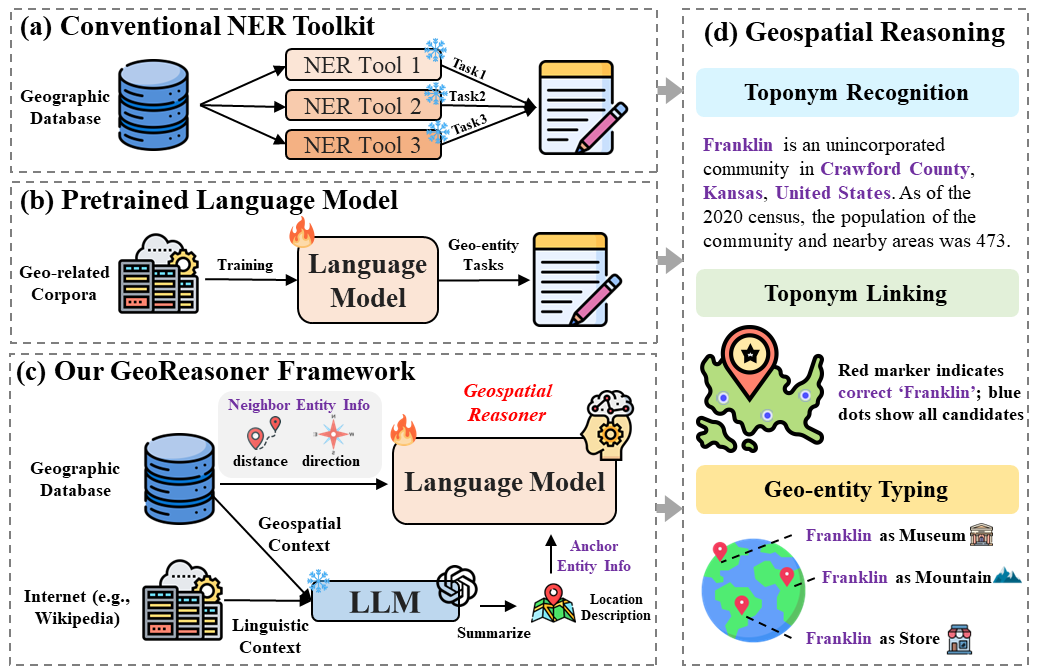
The paper introduces GeoReasoner, a system that combines large language models with geospatial data and reasoning capabilities to enhance natural language understanding. The key components of GeoReasoner include:
-
Geospatial Knowledge Base: GeoReasoner leverages a comprehensive geospatial knowledge base that stores information about locations, landmarks, routes, and other geographic entities.
-
Spatial Reasoning Module: This module uses the geospatial knowledge base to reason about the spatial context and implications of the language being processed. It can perform tasks like identifying referenced locations, inferring spatial relationships, and understanding the implications of spatial descriptions.
-
Language Model Integration: GeoReasoner integrates the spatial reasoning capabilities with a large language model, such as GPT-3, to enable the model to better understand the real-world significance of the language it processes.
The authors demonstrate the effectiveness of GeoReasoner on a range of natural language understanding tasks, including question answering, spatial inference, and language grounding. Their results show that the system can significantly improve the performance of language models on tasks that require geospatial reasoning and understanding.
Critical Analysis
The paper acknowledges that GeoReasoner has some limitations. For instance, the geospatial knowledge base may not be comprehensive or up-to-date in all areas, which could limit the system's ability to reason about certain locations.
Additionally, the authors note that integrating the spatial reasoning capabilities with language models can be technically challenging and may require careful tuning and optimization to achieve optimal performance.
Further research could explore ways to make the geospatial knowledge base more dynamic and adaptable, as well as investigate methods for more seamlessly blending spatial reasoning with language understanding. Expanding the range of tasks and applications evaluated could also help validate the broader utility of the GeoReasoner approach.
Conclusion
In summary, the GeoReasoner paper presents a novel approach to enhancing natural language understanding by incorporating geospatial context and reasoning. By combining large language models with a spatial reasoning module and a comprehensive geospatial knowledge base, the system aims to improve the ability of AI systems to comprehend the real-world implications of the language they process.
The results demonstrate the potential of this approach, and the authors highlight areas for further research and development. As language models continue to advance, techniques like GeoReasoner may play an important role in ensuring that these systems can truly understand and reason about the world in a more grounded and meaningful way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GeoReasoner: Reasoning On Geospatially Grounded Context For Natural Language Understanding
Yibo Yan, Joey Lee
In human reading and communication, individuals tend to engage in geospatial reasoning, which involves recognizing geographic entities and making informed inferences about their interrelationships. To mimic such cognitive process, current methods either utilize conventional natural language understanding toolkits, or directly apply models pretrained on geo-related natural language corpora. However, these methods face two significant challenges: i) they do not generalize well to unseen geospatial scenarios, and ii) they overlook the importance of integrating geospatial context from geographical databases with linguistic information from the Internet. To handle these challenges, we propose GeoReasoner, a language model capable of reasoning on geospatially grounded natural language. Specifically, it first leverages Large Language Models (LLMs) to generate a comprehensive location description based on linguistic and geospatial information. It also encodes direction and distance information into spatial embedding via treating them as pseudo-sentences. Consequently, the model is trained on both anchor-level and neighbor-level inputs to learn geo-entity representation. Extensive experimental results demonstrate GeoReasoner's superiority in three tasks: toponym recognition, toponym linking, and geo-entity typing, compared to the state-of-the-art baselines.
Read more8/22/2024
0
GeoReasoner: Geo-localization with Reasoning in Street Views using a Large Vision-Language Model
Ling Li, Yu Ye, Bingchuan Jiang, Wei Zeng
This work tackles the problem of geo-localization with a new paradigm using a large vision-language model (LVLM) augmented with human inference knowledge. A primary challenge here is the scarcity of data for training the LVLM - existing street-view datasets often contain numerous low-quality images lacking visual clues, and lack any reasoning inference. To address the data-quality issue, we devise a CLIP-based network to quantify the degree of street-view images being locatable, leading to the creation of a new dataset comprising highly locatable street views. To enhance reasoning inference, we integrate external knowledge obtained from real geo-localization games, tapping into valuable human inference capabilities. The data are utilized to train GeoReasoner, which undergoes fine-tuning through dedicated reasoning and location-tuning stages. Qualitative and quantitative evaluations illustrate that GeoReasoner outperforms counterpart LVLMs by more than 25% at country-level and 38% at city-level geo-localization tasks, and surpasses StreetCLIP performance while requiring fewer training resources. The data and code are available at https://github.com/lingli1996/GeoReasoner.
Read more6/28/2024

0
Geode: A Zero-shot Geospatial Question-Answering Agent with Explicit Reasoning and Precise Spatio-Temporal Retrieval
Devashish Vikas Gupta, Azeez Syed Ali Ishaqui, Divya Kiran Kadiyala
Large language models (LLMs) have shown promising results in learning and contextualizing information from different forms of data. Recent advancements in foundational models, particularly those employing self-attention mechanisms, have significantly enhanced our ability to comprehend the semantics of diverse data types. One such area that could highly benefit from multi-modality is in understanding geospatial data, which inherently has multiple modalities. However, current Natural Language Processing (NLP) mechanisms struggle to effectively address geospatial queries. Existing pre-trained LLMs are inadequately equipped to meet the unique demands of geospatial data, lacking the ability to retrieve precise spatio-temporal data in real-time, thus leading to significantly reduced accuracy in answering complex geospatial queries. To address these limitations, we introduce Geode--a pioneering system designed to tackle zero-shot geospatial question-answering tasks with high precision using spatio-temporal data retrieval. Our approach represents a significant improvement in addressing the limitations of current LLM models, demonstrating remarkable improvement in geospatial question-answering abilities compared to existing state-of-the-art pre-trained models.
Read more7/17/2024

0
Geolocation Representation from Large Language Models are Generic Enhancers for Spatio-Temporal Learning
Junlin He, Tong Nie, Wei Ma
In the geospatial domain, universal representation models are significantly less prevalent than their extensive use in natural language processing and computer vision. This discrepancy arises primarily from the high costs associated with the input of existing representation models, which often require street views and mobility data. To address this, we develop a novel, training-free method that leverages large language models (LLMs) and auxiliary map data from OpenStreetMap to derive geolocation representations (LLMGeovec). LLMGeovec can represent the geographic semantics of city, country, and global scales, which acts as a generic enhancer for spatio-temporal learning. Specifically, by direct feature concatenation, we introduce a simple yet effective paradigm for enhancing multiple spatio-temporal tasks including geographic prediction (GP), long-term time series forecasting (LTSF), and graph-based spatio-temporal forecasting (GSTF). LLMGeovec can seamlessly integrate into a wide spectrum of spatio-temporal learning models, providing immediate enhancements. Experimental results demonstrate that LLMGeovec achieves global coverage and significantly boosts the performance of leading GP, LTSF, and GSTF models.
Read more8/23/2024