Selecting Large Language Model to Fine-tune via Rectified Scaling Law
2402.02314
0
0
💬
Abstract
The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with Scaling Law. Unlike pre-training, we find that the fine-tuning scaling curve includes not just the well-known power phase but also the previously unobserved pre-power phase. We also explain why existing Scaling Law fails to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of pre-learned data size into our Rectified Scaling Law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection. The project page is available at rectified-scaling-law.github.io.
Create account to get full access
Overview
- Selecting the best pre-trained large language model (LLM) to fine-tune can be challenging given the vast number of options available.
- This work formulates the resource-constrained model selection task as predicting fine-tuning performance and explores its connection with Scaling Law.
- The authors find that the fine-tuning scaling curve includes a previously unobserved "pre-power" phase, which existing Scaling Law fails to capture.
- To address this, they introduce the concept of "pre-learned data size" into a Rectified Scaling Law, which better fits the experimental results.
- Using their Rectified Scaling Law, the authors propose a novel, efficient LLM selection algorithm that requires far less computational resources compared to other methods.
Plain English Explanation
With the rapid growth of large language models (LLMs), researchers and developers are faced with the challenge of selecting the most appropriate pre-trained model to fine-tune for their specific tasks. Given the limited computational resources available, it's not practical to fine-tune all the models and then choose the best one.
This research paper tackles this problem by formulating it as a task of predicting the fine-tuning performance of different LLMs. The researchers explore the connection between this task and the well-known Scaling Law, which describes the relationship between a model's size and its performance.
Interestingly, the researchers found that the fine-tuning scaling curve includes not just the expected "power" phase, but also a previously unobserved "pre-power" phase. Existing Scaling Law models were unable to capture this transition between the two phases.
To address this, the researchers introduced a new concept called "pre-learned data size" into their Rectified Scaling Law. This allowed their model to better fit the experimental results and overcome the limitations of the previous Scaling Law approaches.
Using their Rectified Scaling Law, the researchers developed a novel algorithm that can select the near-optimal LLM to fine-tune with much less computational resources compared to other methods. This is a significant breakthrough, as it allows researchers and developers to efficiently identify the best model for their needs, even with limited computing power.
Technical Explanation
The paper explores the challenge of selecting the most appropriate pre-trained large language model (LLM) to fine-tune, given the ever-growing ecosystem of such models and constrained computational resources. The authors formulate this task as predicting the fine-tuning performance of different LLMs, and investigate its connection with Scaling Law.
Unlike pre-training, the researchers find that the fine-tuning scaling curve includes not just the well-known "power" phase, but also a previously unobserved "pre-power" phase. They explain why existing Scaling Law models fail to capture this phase transition, both theoretically and empirically.
To address this, the authors introduce the concept of "pre-learned data size" into their Rectified Scaling Law, which allows their model to better fit the experimental results and overcome the limitations of previous approaches. This is further supported by the Unraveling the Mystery of Scaling Laws framework.
The researchers then leverage their Rectified Scaling Law to propose a novel LLM selection algorithm that can identify the near-optimal model with hundreds of times less resource consumption compared to other methods. This is a significant improvement over existing techniques, which may provide negatively correlated selections.
Critical Analysis
The paper provides a valuable contribution to the understanding of the fine-tuning performance of large language models and the limitations of existing Scaling Law approaches. The introduction of the "pre-power" phase and the concept of "pre-learned data size" are interesting insights that expand our knowledge of the scaling behavior of LLMs.
However, the paper does not discuss the potential implications of this research for the broader field of machine learning and language modeling. It would be interesting to see how the Rectified Scaling Law and the proposed selection algorithm could be applied to other types of models or tasks, beyond just LLMs.
Additionally, the paper does not address the potential biases or limitations of the datasets and models used in the experiments. It would be important to understand how the Rectified Scaling Law and the selection algorithm might perform on more diverse and representative datasets, as well as the potential fairness and ethical considerations.
Finally, the paper could have benefited from a more detailed discussion of the practical applications and real-world impact of the proposed approach. While the resource-efficient model selection is a valuable contribution, the paper could have explored the specific use cases and the potential barriers to adoption by the broader research and development community.
Conclusion
This research paper presents a novel approach to selecting the most appropriate pre-trained large language model (LLM) for fine-tuning, addressing the challenge posed by the ever-growing ecosystem of such models and constrained computational resources.
By formulating the model selection task as predicting fine-tuning performance and exploring its connection with Scaling Law, the authors uncover a previously unobserved "pre-power" phase in the fine-tuning scaling curve. To capture this phase transition, they introduce the concept of "pre-learned data size" into their Rectified Scaling Law, which better fits the experimental results.
Leveraging their Rectified Scaling Law, the researchers propose a highly efficient LLM selection algorithm that can identify the near-optimal model with significantly less computational resources compared to other methods. This breakthrough has the potential to greatly improve the accessibility and practicality of fine-tuning large language models, especially for researchers and developers with limited computing power.
The findings of this paper expand our understanding of the scaling behavior of LLMs and pave the way for more efficient and informed decision-making in the selection and fine-tuning of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
0
0
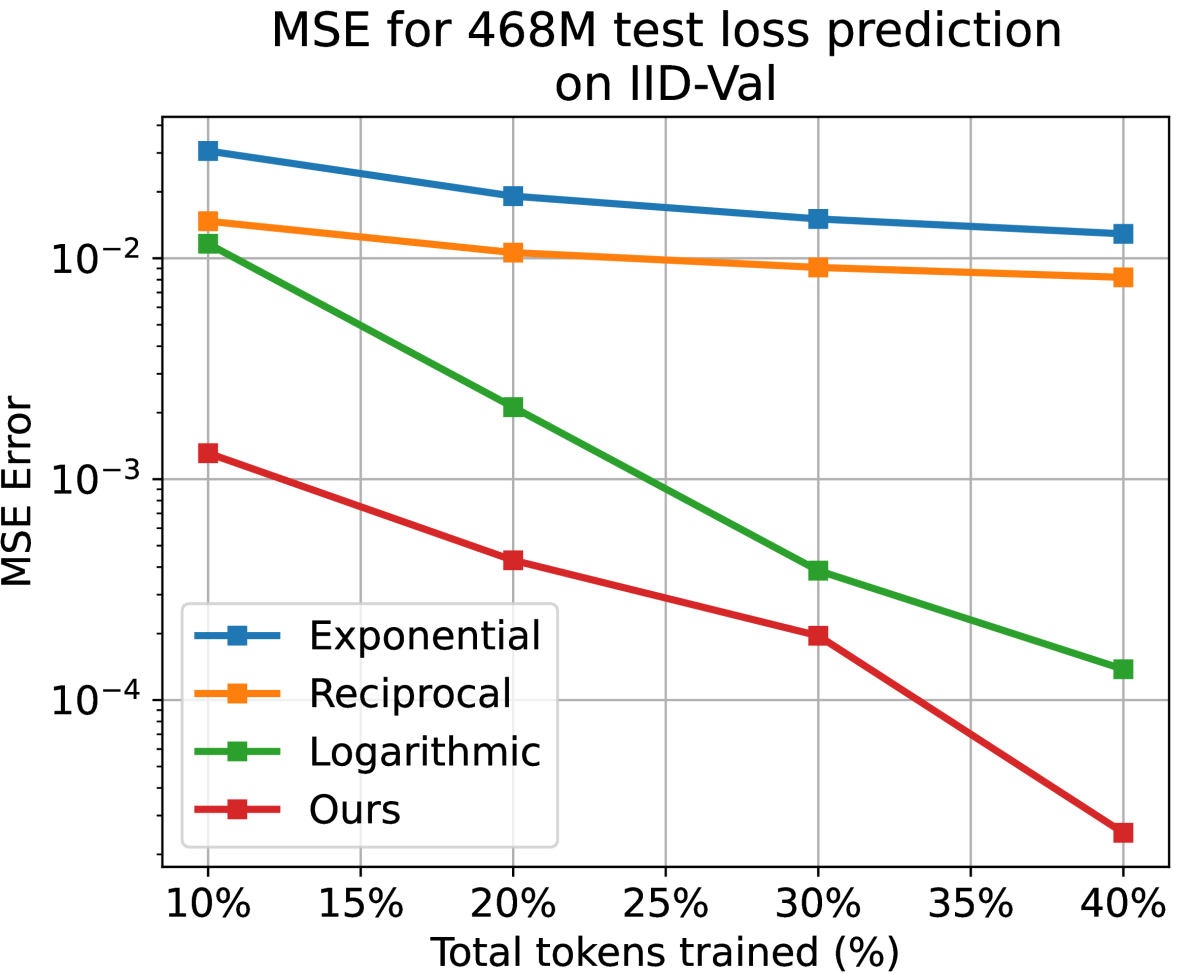
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
6/18/2024
👨🏫
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
0
0
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
5/24/2024
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
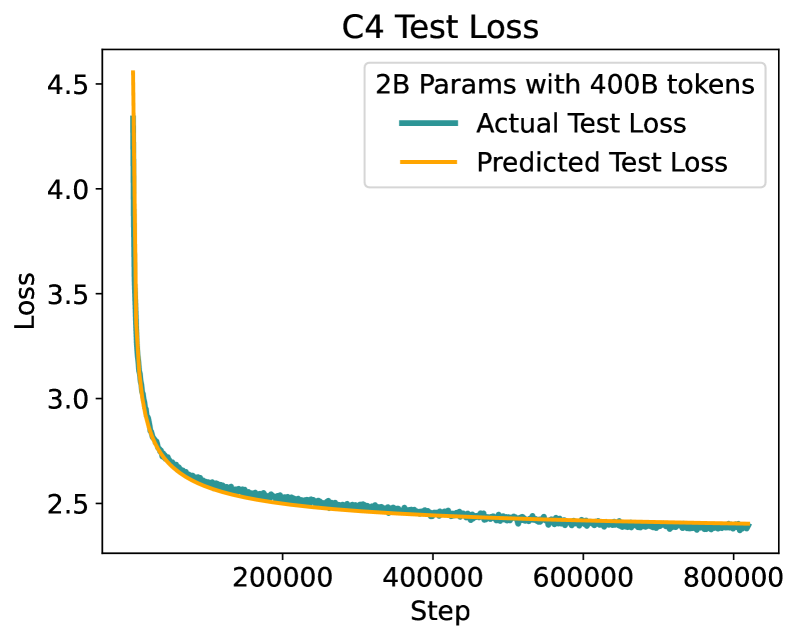
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, Ruoxi Jia
0
0
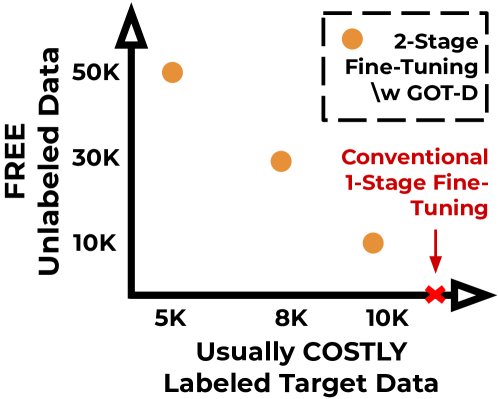
This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
5/7/2024