GLiRA: Black-Box Membership Inference Attack via Knowledge Distillation

0

Sign in to get full access
Overview
- This paper presents GLiRA, a black-box membership inference attack that leverages knowledge distillation to infer whether a given data sample was used to train a target machine learning model.
- The key idea is to train a separate "attack model" to mimic the target model's behavior, which can then be used to detect membership of the target model's training data.
- The authors demonstrate that GLiRA can achieve strong attack performance across a variety of datasets and model architectures, posing a threat to the privacy of machine learning systems.
Plain English Explanation
The paper introduces a new technique called GLiRA that can be used to determine whether a particular data sample was used to train a machine learning model. This is known as a "membership inference attack," and it can pose a risk to the privacy of individuals whose data may have been used to train the model.
The core idea behind GLiRA is to create a separate "attack model" that is trained to mimic the behavior of the target machine learning model. By observing how the attack model responds to different data samples, it is possible to infer whether those samples were part of the target model's original training data.
This is a concerning development, as it means that even if a machine learning model is kept private or "black-box," there may be ways for attackers to still infer sensitive information about the training data. The authors show that GLiRA can be effective across a wide range of datasets and model architectures, making it a potentially powerful tool for breaching the privacy of machine learning systems.
Researchers and practitioners in the field of trustworthy AI will need to consider how to mitigate these types of membership inference attacks, perhaps by developing more robust training techniques or better privacy-preserving measures. The paper on learning-based difficulty calibration and the paper on distributional black-box model inversion explore related topics in this area.
Technical Explanation
The key components of GLiRA are:
- Target Model: The machine learning model whose training data membership is to be inferred.
- Attack Model: A separate model that is trained to mimic the behavior of the target model using knowledge distillation.
- Membership Inference: The attack model is used to identify whether a given data sample was part of the target model's training data or not.
The authors first train the target model on a given dataset. They then create the attack model by training it to match the output probabilities of the target model on a separate dataset. This allows the attack model to learn the underlying patterns and decision boundaries of the target model.
To perform the membership inference, the authors evaluate the attack model's output on the target data samples. Samples that the attack model can predict with high confidence are more likely to have been part of the target model's training data, while samples that the attack model struggles with are more likely to be from the broader population.
The authors evaluate GLiRA's performance across multiple datasets and model architectures, demonstrating its effectiveness at identifying membership in the target model's training data. They also discuss potential countermeasures, such as those explored in the paper on dissecting distribution inference and the paper on towards a game-theoretic understanding of explanation-based membership.
Critical Analysis
The authors provide a thorough evaluation of GLiRA's performance, showing that it can effectively identify membership in the target model's training data across a variety of settings. However, there are a few potential limitations and areas for further research:
- Generalization to Different Domains: The authors primarily evaluate GLiRA on image classification tasks. It would be interesting to see how well the approach generalizes to other domains, such as natural language processing or tabular data.
- Robustness to Countermeasures: The authors discuss potential defenses, such as those explored in the paper on center-based relaxed learning, but do not provide a comprehensive evaluation of how GLiRA performs against these countermeasures.
- Ethical Considerations: Membership inference attacks can have significant privacy implications, and the authors could have delved deeper into the ethical considerations and potential misuse of such techniques.
Overall, GLiRA represents an important advancement in the field of membership inference attacks, but more research is needed to fully understand its capabilities, limitations, and potential countermeasures.
Conclusion
The GLiRA paper introduces a novel black-box membership inference attack that leverages knowledge distillation to infer whether a data sample was used to train a target machine learning model. This work highlights the privacy risks posed by such attacks and the need for continued research into developing robust and trustworthy AI systems that can withstand these types of threats.
As the use of machine learning continues to grow, it will be increasingly important for researchers, practitioners, and policymakers to address the privacy and security concerns surrounding these technologies. The techniques and insights presented in this paper, as well as the related work referenced, will be valuable contributions to this ongoing effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GLiRA: Black-Box Membership Inference Attack via Knowledge Distillation
Andrey V. Galichin, Mikhail Pautov, Alexey Zhavoronkin, Oleg Y. Rogov, Ivan Oseledets
While Deep Neural Networks (DNNs) have demonstrated remarkable performance in tasks related to perception and control, there are still several unresolved concerns regarding the privacy of their training data, particularly in the context of vulnerability to Membership Inference Attacks (MIAs). In this paper, we explore a connection between the susceptibility to membership inference attacks and the vulnerability to distillation-based functionality stealing attacks. In particular, we propose {GLiRA}, a distillation-guided approach to membership inference attack on the black-box neural network. We observe that the knowledge distillation significantly improves the efficiency of likelihood ratio of membership inference attack, especially in the black-box setting, i.e., when the architecture of the target model is unknown to the attacker. We evaluate the proposed method across multiple image classification datasets and models and demonstrate that likelihood ratio attacks when guided by the knowledge distillation, outperform the current state-of-the-art membership inference attacks in the black-box setting.
Read more5/14/2024
0
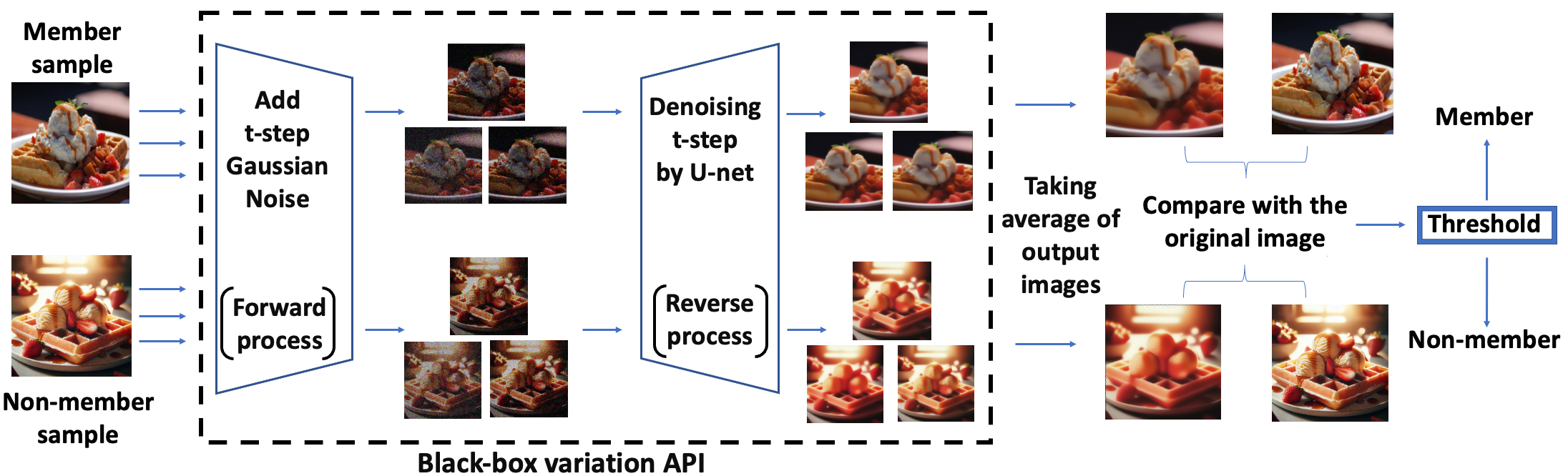
Towards Black-Box Membership Inference Attack for Diffusion Models
Jingwei Li, Jing Dong, Tianxing He, Jingzhao Zhang
Identifying whether an artwork was used to train a diffusion model is an important research topic, given the rising popularity of AI-generated art and the associated copyright concerns. The work approaches this problem from the membership inference attack (MIA) perspective. We first identify the limitations of applying existing MIA methods for copyright protection: the required access of internal U-nets and the choice of non-member datasets for evaluation. To address the above problems, we introduce a novel black-box membership inference attack method that operates without needing access to the model's internal U-net. We then construct a DALL-E generated dataset for a more comprehensive evaluation. We validate our method across various setups, and our experimental results outperform previous works.
Read more6/3/2024
0
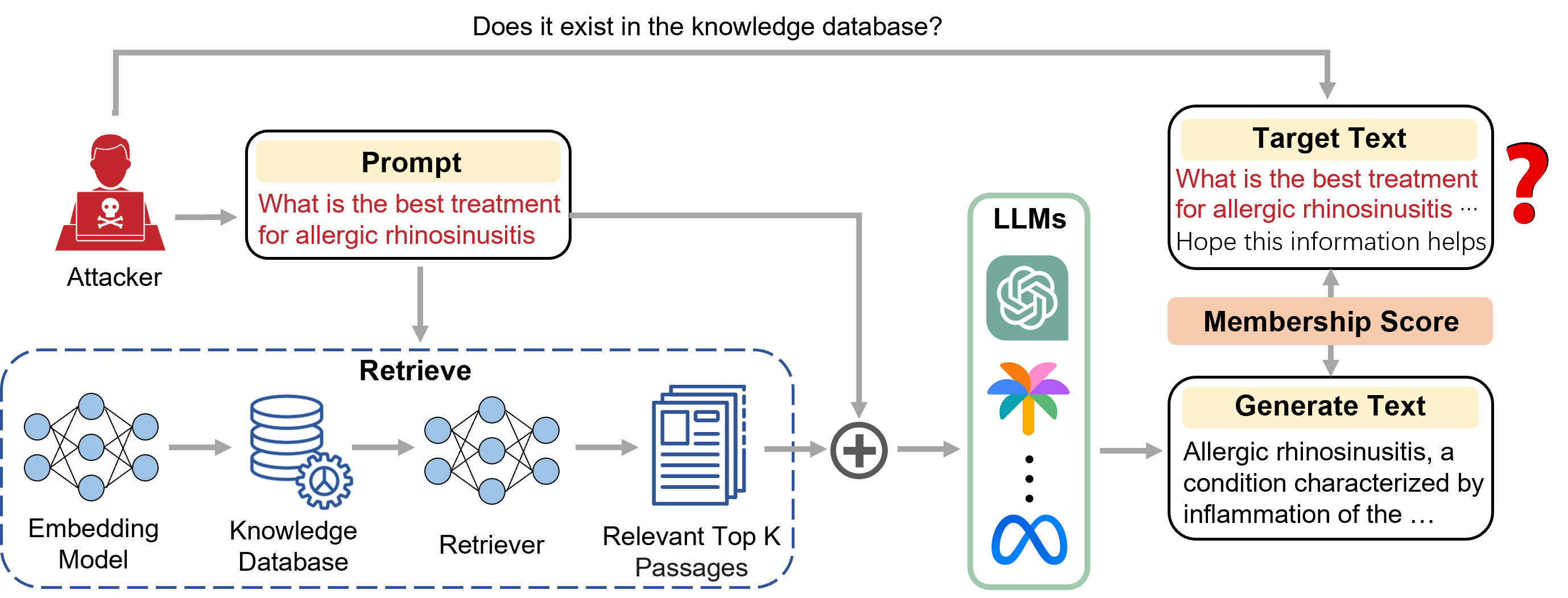
Seeing Is Believing: Black-Box Membership Inference Attacks Against Retrieval Augmented Generation
Yuying Li, Gaoyang Liu, Chen Wang, Yang Yang
Retrieval-Augmented Generation (RAG) is a state-of-the-art technique that mitigates issues such as hallucinations and knowledge staleness in Large Language Models (LLMs) by retrieving relevant knowledge from an external database to assist in content generation. Existing research has demonstrated potential privacy risks associated with the LLMs of RAG. However, the privacy risks posed by the integration of an external database, which often contains sensitive data such as medical records or personal identities, have remained largely unexplored. In this paper, we aim to bridge this gap by focusing on membership privacy of RAG's external database, with the aim of determining whether a given sample is part of the RAG's database. Our basic idea is that if a sample is in the external database, it will exhibit a high degree of semantic similarity to the text generated by the RAG system. We present S$^2$MIA, a underline{M}embership underline{I}nference underline{A}ttack that utilizes the underline{S}emantic underline{S}imilarity between a given sample and the content generated by the RAG system. With our proposed S$^2$MIA, we demonstrate the potential to breach the membership privacy of the RAG database. Extensive experiment results demonstrate that S$^2$MIA can achieve a strong inference performance compared with five existing MIAs, and is able to escape from the protection of three representative defenses.
Read more9/27/2024

0
Unveiling the Unseen: Exploring Whitebox Membership Inference through the Lens of Explainability
Chenxi Li, Abhinav Kumar, Zhen Guo, Jie Hou, Reza Tourani
The increasing prominence of deep learning applications and reliance on personalized data underscore the urgent need to address privacy vulnerabilities, particularly Membership Inference Attacks (MIAs). Despite numerous MIA studies, significant knowledge gaps persist, particularly regarding the impact of hidden features (in isolation) on attack efficacy and insufficient justification for the root causes of attacks based on raw data features. In this paper, we aim to address these knowledge gaps by first exploring statistical approaches to identify the most informative neurons and quantifying the significance of the hidden activations from the selected neurons on attack accuracy, in isolation and combination. Additionally, we propose an attack-driven explainable framework by integrating the target and attack models to identify the most influential features of raw data that lead to successful membership inference attacks. Our proposed MIA shows an improvement of up to 26% on state-of-the-art MIA.
Read more7/2/2024