MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models

0
🤔
Sign in to get full access
Overview
- The ability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more comprehensive understanding of a scene.
- Recent multi-image LVLMs have started addressing this need, but their evaluation has not kept pace with their development.
- To fill this gap, the researchers introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks.
Plain English Explanation
The researchers recognized that Large Vision-Language Models (LVLMs) need to be able to process and understand multiple images at once to truly grasp the complexities of a scene. Recent advances in multi-image LVLMs have started to address this need, but the ways to evaluate these models have not kept up.
To fix this, the researchers created the Multimodal Multi-image Understanding (MMIU) benchmark. This is a comprehensive set of tests that can assess how well LVLMs perform on a wide variety of tasks involving multiple images. The benchmark includes 7 different types of multi-image relationships, 52 specific tasks, 77,000 images, and 11,000 carefully crafted multiple-choice questions.
By evaluating 24 popular LVLMs, including both open-source and proprietary models, the researchers found that these models still struggle significantly with comprehending scenes that involve multiple images. Even the most advanced models, like GPT-4o, only achieved about 55.7% accuracy on the MMIU benchmark. The researchers identified key gaps in performance and limitations, providing valuable insights to improve future models and datasets.
The goal is for the MMIU benchmark to help drive progress in LVLM research and development, moving us closer to achieving sophisticated multimodal multi-image interactions for users.
Technical Explanation
The researchers developed the Multimodal Multi-image Understanding (MMIU) benchmark to comprehensively evaluate the ability of Large Vision-Language Models (LVLMs) to process and understand multiple images at once. This benchmark includes 7 types of multi-image relationships, 52 specific tasks, 77,000 images, and 11,000 carefully curated multiple-choice questions.
To assess the current state of multi-image comprehension in LVLMs, the researchers evaluated 24 popular models, both open-source and proprietary, on the MMIU benchmark. They found that even the most advanced models, such as GPT-4o, struggled, achieving only 55.7% accuracy on average.
Through their analysis, the researchers identified key performance gaps and limitations in the models' ability to understand spatial relationships, reason about the interactions between multiple images, and make inferences based on the combined information. These insights provide valuable guidance for future improvements in model architecture and training data.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their work. For instance, the MMIU benchmark, while extensive, may not capture the full breadth of multi-image understanding tasks that users might encounter in real-world applications.
Additionally, the evaluation was limited to 24 popular LVLMs, and there may be other models or approaches that could perform better on the benchmark. The researchers also note that the performance gaps they identified may be influenced by biases or shortcomings in the dataset itself, which would need to be further investigated.
It would be valuable for future research to explore alternative evaluation methodologies, expand the benchmark to include a wider range of multi-image tasks and relationships, and investigate the underlying reasons for the models' performance limitations. Addressing these areas could lead to more robust and capable LVLMs that can truly excel at multimodal multi-image understanding.
Conclusion
The introduction of the Multimodal Multi-image Understanding (MMIU) benchmark represents an important step forward in assessing the capabilities of Large Vision-Language Models (LVLMs) to process and comprehend multiple images simultaneously. The comprehensive evaluation conducted by the researchers revealed significant challenges in this area, even for the most advanced models.
By identifying key performance gaps and limitations, this work provides valuable insights to guide future improvements in model architecture, training data, and evaluation methodologies. Advancing the state of multi-image understanding in LVLMs is crucial for developing sophisticated multimodal interactions that can truly benefit users across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, Kaipeng Zhang, Wenqi Shao
The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced understanding of a scene. Recent multi-image LVLMs have begun to address this need. However, their evaluation has not kept pace with their development. To fill this gap, we introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks. MMIU encompasses 7 types of multi-image relationships, 52 tasks, 77K images, and 11K meticulously curated multiple-choice questions, making it the most extensive benchmark of its kind. Our evaluation of 24 popular LVLMs, including both open-source and proprietary models, reveals significant challenges in multi-image comprehension, particularly in tasks involving spatial understanding. Even the most advanced models, such as GPT-4o, achieve only 55.7% accuracy on MMIU. Through multi-faceted analytical experiments, we identify key performance gaps and limitations, providing valuable insights for future model and data improvements. We aim for MMIU to advance the frontier of LVLM research and development, moving us toward achieving sophisticated multimodal multi-image user interactions.
Read more8/7/2024
🤔
0
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of 14 open-source LMMs as well as the proprietary GPT-4V(ision) and Gemini highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V and Gemini Ultra only achieve accuracies of 56% and 59% respectively, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Read more6/14/2024
0
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
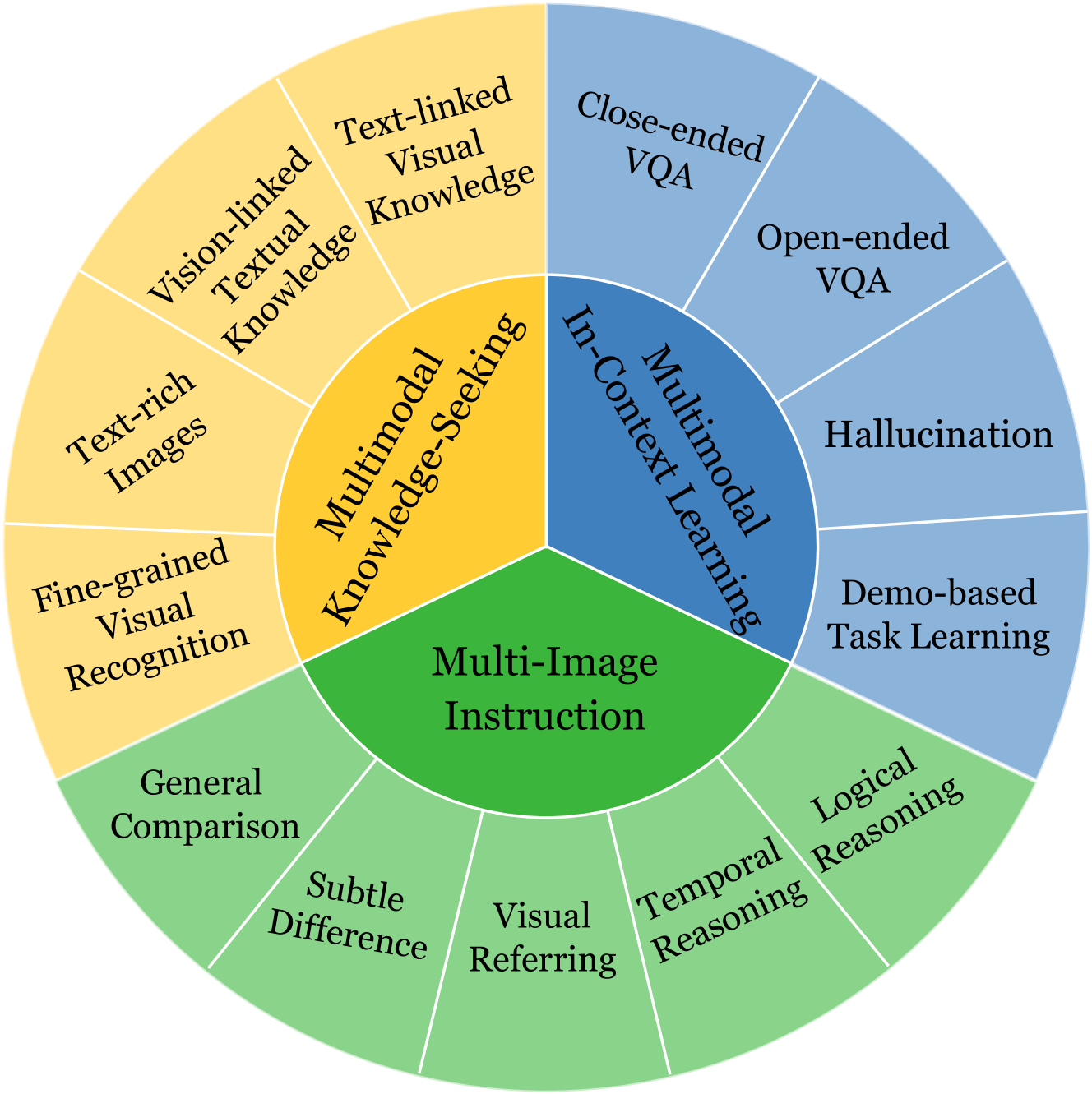
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024

0
M4U: Evaluating Multilingual Understanding and Reasoning for Large Multimodal Models
Hongyu Wang, Jiayu Xu, Senwei Xie, Ruiping Wang, Jialin Li, Zhaojie Xie, Bin Zhang, Chuyan Xiong, Xilin Chen
Multilingual multimodal reasoning is a core component in achieving human-level intelligence. However, most existing benchmarks for multilingual multimodal reasoning struggle to differentiate between models of varying performance; even language models without visual capabilities can easily achieve high scores. This leaves a comprehensive evaluation of leading multilingual multimodal models largely unexplored. In this work, we introduce M4U, a novel and challenging benchmark for assessing the capability of multi-discipline multilingual multimodal understanding and reasoning. M4U contains 8,931 samples covering 64 disciplines across 16 subfields in Science, Engineering, and Healthcare in Chinese, English, and German. Using M4U, we conduct extensive evaluations of 21 leading Large Multimodal Models (LMMs) and Large Language Models (LLMs) with external tools. The evaluation results show that the state-of-the-art model, GPT-4o, achieves only 47.6% average accuracy on M4U. Additionally, we observe that the leading LMMs exhibit significant language preferences. Our in-depth analysis indicates that leading LMMs, including GPT-4o, suffer performance degradation when prompted with cross-lingual multimodal questions, such as images with key textual information in Chinese while the question is in German. We believe that M4U can serve as a crucial tool for systematically evaluating LMMs based on their multilingual multimodal reasoning capabilities and monitoring their development. The homepage, codes and data are public available.
Read more5/27/2024