GMM-ResNext: Combining Generative and Discriminative Models for Speaker Verification

0

Sign in to get full access
Overview
- This research paper introduces GMM-ResNext, a novel approach that combines generative and discriminative models for speaker verification.
- The key idea is to leverage the strengths of both generative and discriminative models to improve the performance of speaker verification systems.
- The paper explores the use of a log Gaussian probability feature, which captures the probabilistic characteristics of speaker embeddings, and integrates it with a ResNeXt-based discriminative model.
Plain English Explanation
The paper presents a new technique called GMM-ResNext that aims to improve speaker verification, which is the process of verifying a person's identity based on their voice. Traditional speaker verification systems often rely on either generative models that capture the statistical properties of speaker embeddings, or discriminative models that focus on differentiating between speakers.
The researchers behind GMM-ResNext propose a hybrid approach that combines the strengths of both types of models. They introduce a "log Gaussian probability feature" that captures the probabilistic nature of speaker embeddings, and then integrate this feature with a powerful ResNeXt-based discriminative model. The idea is that by leveraging both the statistical and the discriminative information, the resulting system can achieve better performance in verifying a speaker's identity.
This combination of generative and discriminative models is a novel approach in the field of speaker verification, and the researchers believe it has the potential to advance the state of the art in this important area of biometric authentication.
Technical Explanation
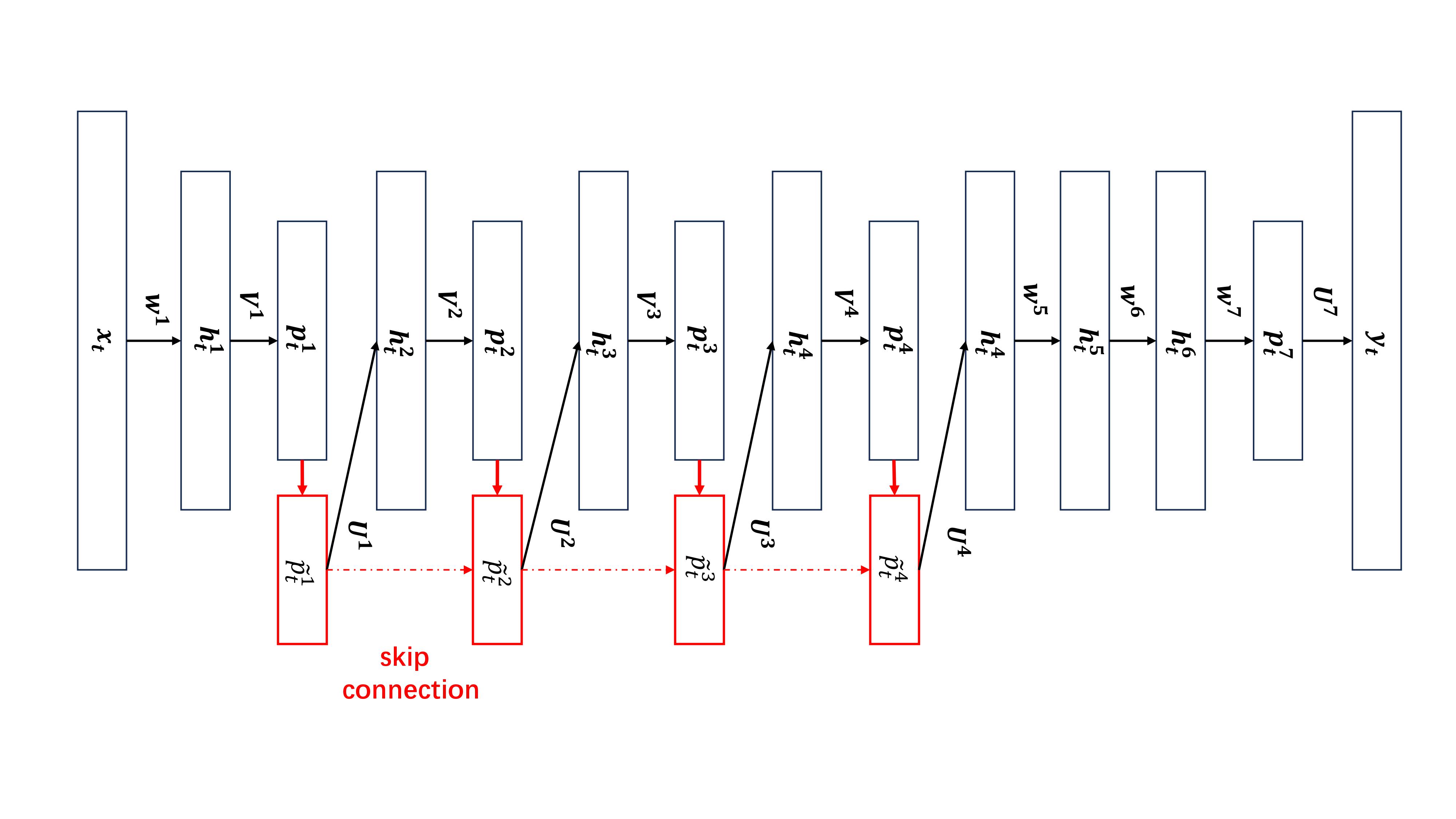
The key technical contribution of this paper is the introduction of the "log Gaussian probability feature" (LGPF), which is designed to capture the probabilistic characteristics of speaker embeddings. The LGPF is computed by passing the speaker embeddings through a Gaussian Mixture Model (GMM), which models the underlying probability distribution of the embeddings. The log of the resulting probability values is then used as an additional feature, which is concatenated with the original speaker embeddings.
This LGPF feature is then fed into a ResNeXt-based discriminative model, which is trained to perform speaker verification. The researchers hypothesize that the combination of the generative LGPF feature and the discriminative power of the ResNeXt model will result in improved speaker verification performance compared to using either type of model alone.
The proposed GMM-ResNext architecture is evaluated on several standard speaker verification benchmarks, and the results demonstrate that it outperforms state-of-the-art approaches, including those that use only generative or discriminative models.
Critical Analysis
The researchers have made a strong case for the benefits of combining generative and discriminative models for speaker verification. The use of the LGPF feature is a novel and well-justified approach, as it allows the model to leverage the probabilistic information in the speaker embeddings.
However, one potential limitation of the proposed method is the added computational complexity and training overhead. Incorporating the GMM-based LGPF feature increases the model size and the number of parameters that need to be trained, which could make it less practical for real-time or resource-constrained applications.
Additionally, the paper does not provide a detailed analysis of the trade-offs between the generative and discriminative components of the model. It would be interesting to see how the performance of the system changes when the relative weights of these two components are varied, and to understand the scenarios where one type of model might be more beneficial than the other.
Further research could also explore the applicability of this hybrid approach to other biometric authentication tasks, such as face recognition or gesture recognition, where the combination of generative and discriminative models might also prove advantageous.
Conclusion
The GMM-ResNext model presented in this paper represents a significant advancement in the field of speaker verification. By combining the strengths of generative and discriminative models, the researchers have developed a novel approach that outperforms state-of-the-art techniques.
The introduction of the LGPF feature is a particularly notable contribution, as it allows the model to capture the probabilistic nature of speaker embeddings in a way that complements the discriminative power of the ResNeXt architecture.
While there may be some practical considerations around the increased complexity of the model, the overall results suggest that the GMM-ResNext approach has the potential to make a lasting impact on biometric authentication systems, particularly in scenarios where high-accuracy speaker verification is critical, such as in voice-based user authentication or speech-based access control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GMM-ResNext: Combining Generative and Discriminative Models for Speaker Verification
Hui Yan, Zhenchun Lei, Changhong Liu, Yong Zhou
With the development of deep learning, many different network architectures have been explored in speaker verification. However, most network architectures rely on a single deep learning architecture, and hybrid networks combining different architectures have been little studied in ASV tasks. In this paper, we propose the GMM-ResNext model for speaker verification. Conventional GMM does not consider the score distribution of each frame feature over all Gaussian components and ignores the relationship between neighboring speech frames. So, we extract the log Gaussian probability features based on the raw acoustic features and use ResNext-based network as the backbone to extract the speaker embedding. GMM-ResNext combines Generative and Discriminative Models to improve the generalization ability of deep learning models and allows one to more easily specify meaningful priors on model parameters. A two-path GMM-ResNext model based on two gender-related GMMs has also been proposed. The Experimental results show that the proposed GMM-ResNext achieves relative improvements of 48.1% and 11.3% in EER compared with ResNet34 and ECAPA-TDNN on VoxCeleb1-O test set.
Read more7/4/2024

0
Two-Path GMM-ResNet and GMM-SENet for ASV Spoofing Detection
Zhenchun Lei, Hui Yan, Changhong Liu, Minglei Ma, Yingen Yang
The automatic speaker verification system is sometimes vulnerable to various spoofing attacks. The 2-class Gaussian Mixture Model classifier for genuine and spoofed speech is usually used as the baseline for spoofing detection. However, the GMM classifier does not separately consider the scores of feature frames on each Gaussian component. In addition, the GMM accumulates the scores on all frames independently, and does not consider their correlations. We propose the two-path GMM-ResNet and GMM-SENet models for spoofing detection, whose input is the Gaussian probability features based on two GMMs trained on genuine and spoofed speech respectively. The models consider not only the score distribution on GMM components, but also the relationship between adjacent frames. A two-step training scheme is applied to improve the system robustness. Experiments on the ASVspoof 2019 show that the LFCC+GMM-ResNet system can relatively reduce min-tDCF and EER by 76.1% and 76.3% on logical access scenario compared with the GMM, and the LFCC+GMM-SENet system by 94.4% and 95.4% on physical access scenario. After score fusion, the systems give the second-best results on both scenarios.
Read more7/9/2024
0
A New Perspective on Speaker Verification: Joint Modeling with DFSMN and Transformer
Hongyu Wang, Hui Li, Bo Li
Speaker verification is to judge the similarity between two unknown voices in an open set, where the ideal speaker embedding should be able to condense discriminant information into a compact utterance-level representation that has small intra-speaker distances and large inter-speaker distances. We propose Voice Transformer (VOT), a novel model for speaker verification, which integrates parallel transformers at multiple scales. A deep feedforward sequential memory network (DFSMN) is incorporated into the attention part of these transformers to increase feature granularity. The attentive statistics pooling layer is added to focus on important frames and form utterance-level features. We propose Additive Angular Margin Focal Loss (AAMF) to address the hard samples problem. We evaluate the proposed approach on the VoxCeleb1 and CN-Celeb2 datasets, demonstrating that VOT surpasses most mainstream models. The code is available on GitHubfootnote{url{https://github.com/luckyerr/Voice-Transformer_Speaker-Verification}}.
Read more9/10/2024

0
Straight Through Gumbel Softmax Estimator based Bimodal Neural Architecture Search for Audio-Visual Deepfake Detection
Aravinda Reddy PN, Raghavendra Ramachandra, Krothapalli Sreenivasa Rao, Pabitra Mitra, Vinod Rathod
Deepfakes are a major security risk for biometric authentication. This technology creates realistic fake videos that can impersonate real people, fooling systems that rely on facial features and voice patterns for identification. Existing multimodal deepfake detectors rely on conventional fusion methods, such as majority rule and ensemble voting, which often struggle to adapt to changing data characteristics and complex patterns. In this paper, we introduce the Straight-through Gumbel-Softmax (STGS) framework, offering a comprehensive approach to search multimodal fusion model architectures. Using a two-level search approach, the framework optimizes the network architecture, parameters, and performance. Initially, crucial features were efficiently identified from backbone networks, whereas within the cell structure, a weighted fusion operation integrated information from various sources. An architecture that maximizes the classification performance is derived by varying parameters such as temperature and sampling time. The experimental results on the FakeAVCeleb and SWAN-DF datasets demonstrated an impressive AUC value 94.4% achieved with minimal model parameters.
Read more6/21/2024