Straight Through Gumbel Softmax Estimator based Bimodal Neural Architecture Search for Audio-Visual Deepfake Detection

0

Sign in to get full access
Overview
- Presents a bimodal neural architecture for audio-visual deepfake detection using a Straight Through Gumbel Softmax Estimator
- Proposes a novel neural architecture search approach to automatically discover the optimal model configuration for this task
- Demonstrates state-of-the-art performance on several benchmark datasets for audio-visual deepfake detection
Plain English Explanation
This research paper introduces a new approach for detecting deepfake videos, which are manipulated media that can make people appear to say or do things they didn't. The key innovation is the use of a "bimodal" system that analyzes both the audio and visual components of a video, rather than just one or the other.
The researchers developed a neural network architecture that can automatically search for the optimal configuration of this bimodal system. This is done using a technique called the "Straight Through Gumbel Softmax Estimator," which helps the model efficiently explore different architectural choices.
The resulting model achieves impressive performance on standard benchmarks for detecting deepfake videos. This is an important step forward, as the proliferation of deepfakes poses growing challenges for verifying the authenticity of online content. By combining audio and visual cues, this new system can more reliably identify manipulated media.
Technical Explanation
The paper proposes a Straight Through Gumbel Softmax Estimator based Bimodal Neural Architecture Search for audio-visual deepfake detection. The model consists of separate audio and visual processing streams that are fused together using a multi-modal feature fusion approach.
The key innovation is the use of neural architecture search to automatically discover the optimal configuration of the bimodal system. This is done using the Straight Through Gumbel Softmax Estimator, which allows the model to efficiently explore different architectural choices during training.
The audio and visual streams leverage state-of-the-art deep learning models that have been shown to be effective for deepfake detection. The fused features are then passed to a classification head to predict whether a given sample is a real or deepfake video.
Critical Analysis
The paper presents a compelling approach that leverages both audio and visual cues to improve deepfake detection. The neural architecture search technique is a novel contribution that allows the model to automatically discover an optimal configuration, rather than relying on manual design choices.
However, the paper does not provide a detailed analysis of the computational complexity or training time required for the architecture search process. This is an important consideration, as the time and resources needed for neural architecture search can be significant.
Additionally, the paper tests the model on standard benchmark datasets, but does not evaluate its performance on more diverse or realistic deepfake samples. Further research may be needed to assess the model's robustness and generalization capabilities in real-world scenarios.
Conclusion
This research represents an important advancement in the field of audio-visual deepfake detection. By combining state-of-the-art deep learning models with a novel neural architecture search technique, the authors have developed a bimodal system that achieves impressive performance on standard benchmarks.
As deepfakes continue to become more sophisticated and widespread, tools like this bimodal detector will be crucial for verifying the authenticity of online content. The ability to leverage both audio and visual cues makes this approach a promising step towards more reliable deepfake detection.
Future work could explore ways to further improve the efficiency and robustness of the architecture search process, as well as test the model on a wider range of deepfake samples. Overall, this research represents an important contribution to the ongoing effort to combat the growing threat of manipulated media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Straight Through Gumbel Softmax Estimator based Bimodal Neural Architecture Search for Audio-Visual Deepfake Detection
Aravinda Reddy PN, Raghavendra Ramachandra, Krothapalli Sreenivasa Rao, Pabitra Mitra, Vinod Rathod
Deepfakes are a major security risk for biometric authentication. This technology creates realistic fake videos that can impersonate real people, fooling systems that rely on facial features and voice patterns for identification. Existing multimodal deepfake detectors rely on conventional fusion methods, such as majority rule and ensemble voting, which often struggle to adapt to changing data characteristics and complex patterns. In this paper, we introduce the Straight-through Gumbel-Softmax (STGS) framework, offering a comprehensive approach to search multimodal fusion model architectures. Using a two-level search approach, the framework optimizes the network architecture, parameters, and performance. Initially, crucial features were efficiently identified from backbone networks, whereas within the cell structure, a weighted fusion operation integrated information from various sources. An architecture that maximizes the classification performance is derived by varying parameters such as temperature and sampling time. The experimental results on the FakeAVCeleb and SWAN-DF datasets demonstrated an impressive AUC value 94.4% achieved with minimal model parameters.
Read more6/21/2024
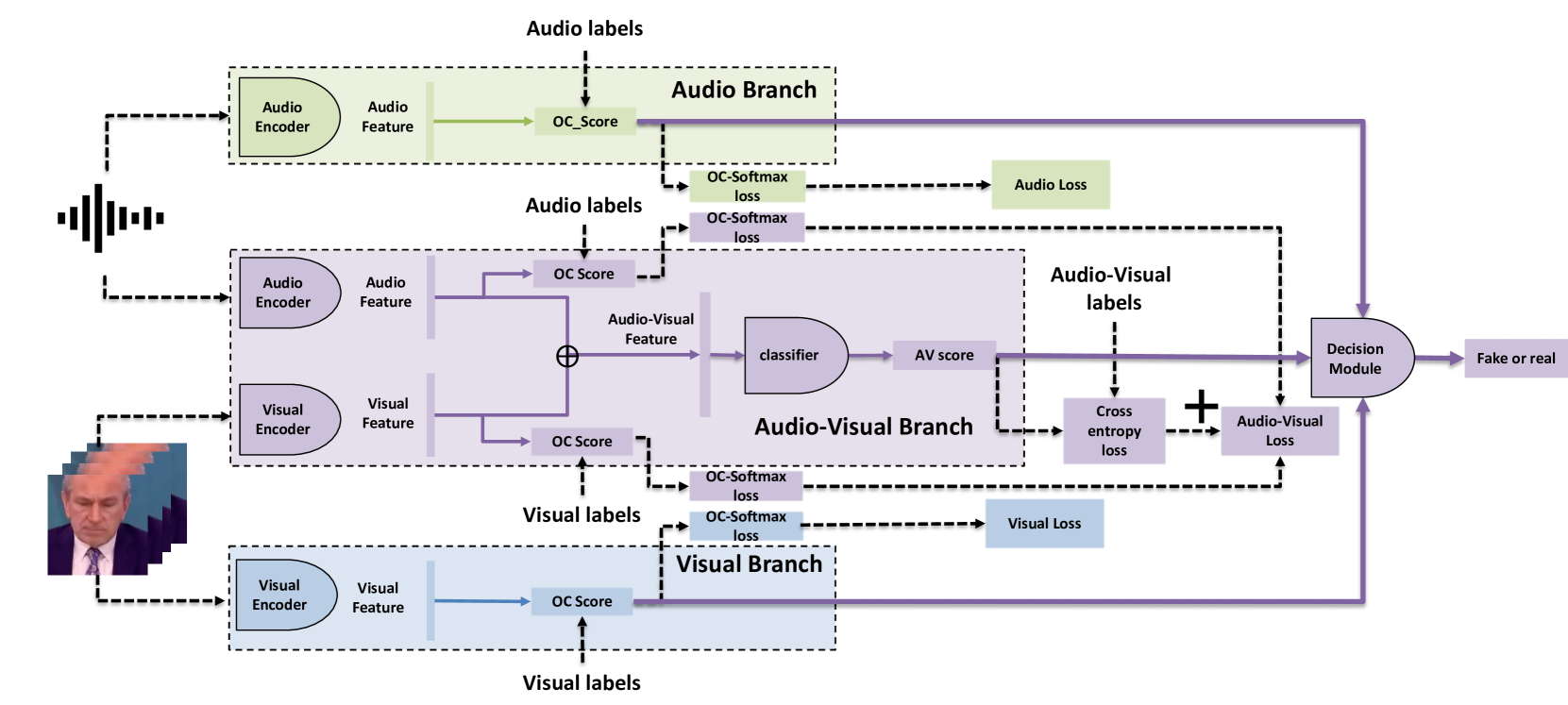
0
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake videos (Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and Unsynchronized videos). The experimental results demonstrate that our approach surpasses the previous models by a large margin. Furthermore, our proposed framework offers interpretability, indicating which modality the model identifies as more likely to be fake. The source code is released at https://github.com/bok-bok/MSOC.
Read more8/20/2024

0
Statistics-aware Audio-visual Deepfake Detector
Marcella Astrid, Enjie Ghorbel, Djamila Aouada
In this paper, we propose an enhanced audio-visual deep detection method. Recent methods in audio-visual deepfake detection mostly assess the synchronization between audio and visual features. Although they have shown promising results, they are based on the maximization/minimization of isolated feature distances without considering feature statistics. Moreover, they rely on cumbersome deep learning architectures and are heavily dependent on empirically fixed hyperparameters. Herein, to overcome these limitations, we propose: (1) a statistical feature loss to enhance the discrimination capability of the model, instead of relying solely on feature distances; (2) using the waveform for describing the audio as a replacement of frequency-based representations; (3) a post-processing normalization of the fakeness score; (4) the use of shallower network for reducing the computational complexity. Experiments on the DFDC and FakeAVCeleb datasets demonstrate the relevance of the proposed method.
Read more7/18/2024

0
Comparative Analysis of Modality Fusion Approaches for Audio-Visual Person Identification and Verification
Aref Farhadipour, Masoumeh Chapariniya, Teodora Vukovic, Volker Dellwo
Multimodal learning involves integrating information from various modalities to enhance learning and comprehension. We compare three modality fusion strategies in person identification and verification by processing two modalities: voice and face. In this paper, a one-dimensional convolutional neural network is employed for x-vector extraction from voice, while the pre-trained VGGFace2 network and transfer learning are utilized for face modality. In addition, gammatonegram is used as speech representation in engagement with the Darknet19 pre-trained network. The proposed systems are evaluated using the K-fold cross-validation technique on the 118 speakers of the test set of the VoxCeleb2 dataset. The comparative evaluations are done for single-modality and three proposed multimodal strategies in equal situations. Results demonstrate that the feature fusion strategy of gammatonegram and facial features achieves the highest performance, with an accuracy of 98.37% in the person identification task. However, concatenating facial features with the x-vector reaches 0.62% for EER in verification tasks.
Read more9/4/2024