GraCoRe: Benchmarking Graph Comprehension and Complex Reasoning in Large Language Models

0
Sign in to get full access
Overview
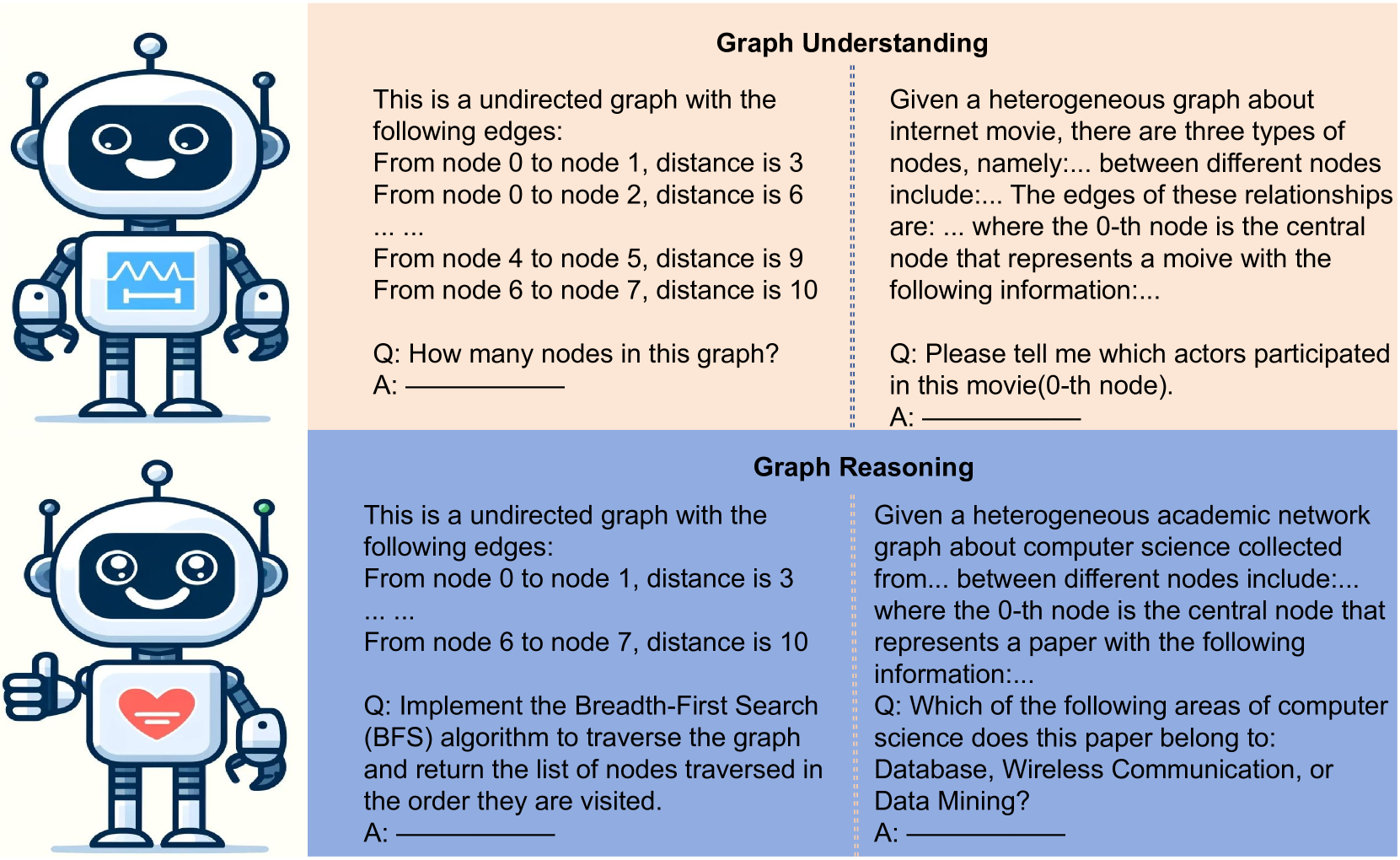
- This paper presents GraCoRe, a new benchmark for evaluating the graph comprehension and complex reasoning capabilities of large language models (LLMs).
- The benchmark includes a diverse set of tasks that assess an LLM's ability to understand and reason about graph-structured data, such as answering questions about relationships between entities, making inferences, and solving graph-based problems.
- The authors demonstrate the effectiveness of GraCoRe by evaluating several state-of-the-art LLMs and provide insights into their strengths and weaknesses in graph-related tasks.
Plain English Explanation
The paper describes a new way to test how well large language models (LLMs) can understand and work with information that is organized in the form of graphs. Graphs are a way of representing relationships between different entities, like how people are connected in a social network or how chemical reactions are linked together.
The researchers created a GraphEval benchmark, called GraCoRe, that includes a variety of tasks to assess an LLM's ability to comprehend and reason about graph-structured data. For example, the tasks might ask the model to answer questions about the relationships between entities in a graph, make logical inferences based on the graph, or solve problems that involve navigating and analyzing the graph.
By evaluating several state-of-the-art LLMs on the GraCoRe benchmark, the researchers were able to get a better understanding of how these models perform on graph-related tasks. This information can help guide the development of more capable and versatile LLMs that can better handle real-world data that is often organized in graph-like structures, such as social networks, transportation networks, or knowledge graphs.
Technical Explanation
The paper presents GraCoRe, a new benchmark for evaluating the graph comprehension and complex reasoning capabilities of large language models (LLMs). The benchmark includes a diverse set of tasks that assess an LLM's ability to understand and reason about graph-structured data, such as answering questions about relationships between entities, making inferences, and solving graph-based problems.
The authors demonstrate the effectiveness of GraCoRe by evaluating several state-of-the-art LLMs, including GPT-3, BERT, and RoBERTa, on the benchmark. The results provide insights into the strengths and weaknesses of these models in graph-related tasks, highlighting areas for improvement and the need for further research in this domain.
The GraCoRe benchmark is designed to complement existing graph-related benchmarks, such as GraphArena and GraphReason, by focusing on a wider range of graph comprehension and complex reasoning tasks. The authors also discuss the potential for using techniques like Graph Chain-of-Thought to further enhance the reasoning capabilities of LLMs in the context of graph-structured data.
Critical Analysis
The GraCoRe benchmark presented in this paper is a valuable contribution to the field of graph-based reasoning in large language models. By providing a comprehensive and diverse set of tasks, the authors have created a robust tool for evaluating the graph comprehension and complex reasoning abilities of LLMs.
One potential limitation of the study is the use of a relatively small set of LLM architectures, which may limit the generalizability of the findings. It would be interesting to see the performance of a wider range of LLMs, including more specialized models for graph-related tasks, such as those developed in the ChartBench project.
Additionally, the paper does not discuss the potential biases or limitations of the benchmark itself. It would be valuable to understand how the task design and dataset composition may influence the performance of LLMs, and whether there are any inherent biases or blind spots in the benchmark that need to be addressed.
Overall, the GraCoRe benchmark is a significant step forward in the evaluation of LLM capabilities in the graph domain. The insights gained from this work can inform the development of more capable and versatile LLMs that can better handle the complex, graph-structured data encountered in real-world applications.
Conclusion
The GraCoRe benchmark presented in this paper represents an important advancement in the evaluation of graph comprehension and complex reasoning capabilities in large language models. By providing a diverse and comprehensive set of tasks, the authors have created a valuable tool for assessing the strengths and weaknesses of LLMs in this critical domain.
The findings from the evaluation of state-of-the-art LLMs on the GraCoRe benchmark offer valuable insights that can guide the development of more capable and versatile models, better equipped to handle the graph-structured data common in real-world applications. As the field of LLM research continues to evolve, benchmarks like GraCoRe will play a crucial role in driving progress and ensuring that these models can effectively reason about and comprehend the complex, interconnected nature of the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GraCoRe: Benchmarking Graph Comprehension and Complex Reasoning in Large Language Models
Zike Yuan, Ming Liu, Hui Wang, Bing Qin
Evaluating the graph comprehension and reasoning abilities of Large Language Models (LLMs) is challenging and often incomplete. Existing benchmarks focus primarily on pure graph understanding, lacking a comprehensive evaluation across all graph types and detailed capability definitions. This paper presents GraCoRe, a benchmark for systematically assessing LLMs' graph comprehension and reasoning. GraCoRe uses a three-tier hierarchical taxonomy to categorize and test models on pure graph and heterogeneous graphs, subdividing capabilities into 10 distinct areas tested through 19 tasks. Our benchmark includes 11 datasets with 5,140 graphs of varying complexity. We evaluated three closed-source and seven open-source LLMs, conducting thorough analyses from both ability and task perspectives. Key findings reveal that semantic enrichment enhances reasoning performance, node ordering impacts task success, and the ability to process longer texts does not necessarily improve graph comprehension or reasoning. GraCoRe is open-sourced at https://github.com/ZIKEYUAN/GraCoRe
Read more7/4/2024

0
GraphEval2000: Benchmarking and Improving Large Language Models on Graph Datasets
Qiming Wu, Zichen Chen, Will Corcoran, Misha Sra, Ambuj K. Singh
Large language models (LLMs) have achieved remarkable success in natural language processing (NLP), demonstrating significant capabilities in processing and understanding text data. However, recent studies have identified limitations in LLMs' ability to reason about graph-structured data. To address this gap, we introduce GraphEval2000, the first comprehensive graph dataset, comprising 40 graph data structure problems along with 2000 test cases. Additionally, we introduce an evaluation framework based on GraphEval2000, designed to assess the graph reasoning abilities of LLMs through coding challenges. Our dataset categorizes test cases into four primary and four sub-categories, ensuring a comprehensive evaluation. We evaluate eight popular LLMs on GraphEval2000, revealing that LLMs exhibit a better understanding of directed graphs compared to undirected ones. While private LLMs consistently outperform open-source models, the performance gap is narrowing. Furthermore, to improve the usability of our evaluation framework, we propose Structured Symbolic Decomposition (SSD), an instruction-based method designed to enhance LLM performance on GraphEval2000. Results show that SSD improves the performance of GPT-3.5, GPT-4, and GPT-4o on complex graph problems, with an increase of 11.11%, 33.37%, and 33.37%, respectively.
Read more6/26/2024

0
GraphArena: Benchmarking Large Language Models on Graph Computational Problems
Jianheng Tang, Qifan Zhang, Yuhan Li, Jia Li
The arms race of Large Language Models (LLMs) demands novel, challenging, and diverse benchmarks to faithfully examine their progresses. We introduce GraphArena, a benchmarking tool designed to evaluate LLMs on graph computational problems using million-scale real-world graphs from diverse scenarios such as knowledge graphs, social networks, and molecular structures. GraphArena offers a suite of 10 computational tasks, encompassing four polynomial-time (e.g., Shortest Distance) and six NP-complete challenges (e.g., Travelling Salesman Problem). It features a rigorous evaluation framework that classifies LLM outputs as correct, suboptimal (feasible but not optimal), or hallucinatory (properly formatted but infeasible). Evaluation of 10 leading LLMs, including GPT-4o and LLaMA3-70B-Instruct, reveals that even top-performing models struggle with larger, more complex graph problems and exhibit hallucination issues. Despite the application of strategies such as chain-of-thought prompting, these issues remain unresolved. GraphArena contributes a valuable supplement to the existing LLM benchmarks and is open-sourced at https://github.com/squareRoot3/GraphArena.
Read more7/2/2024

0
CLR-Fact: Evaluating the Complex Logical Reasoning Capability of Large Language Models over Factual Knowledge
Tianshi Zheng, Jiaxin Bai, Yicheng Wang, Tianqing Fang, Yue Guo, Yauwai Yim, Yangqiu Song
While large language models (LLMs) have demonstrated impressive capabilities across various natural language processing tasks by acquiring rich factual knowledge from their broad training data, their ability to synthesize and logically reason with this knowledge in complex ways remains underexplored. In this work, we present a systematic evaluation of state-of-the-art LLMs' complex logical reasoning abilities through a novel benchmark of automatically generated complex reasoning questions over general domain and biomedical knowledge graphs. Our extensive experiments, employing diverse in-context learning techniques, reveal that LLMs excel at reasoning over general world knowledge but face significant challenges with specialized domain-specific knowledge. We find that prompting with explicit Chain-of-Thought demonstrations can substantially improve LLM performance on complex logical reasoning tasks with diverse logical operations. Interestingly, our controlled evaluations uncover an asymmetry where LLMs display proficiency at set union operations, but struggle considerably with set intersections - a key building block of logical reasoning. To foster further work, we will publicly release our evaluation benchmark and code.
Read more7/31/2024