QGen: On the Ability to Generalize in Quantization Aware Training
2404.11769
0
0
Abstract
Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper explores the ability of quantization-aware training (QAT) to generalize to different datasets and tasks beyond the ones used during training.
• QAT is a technique used to reduce the precision of neural network weights and activations, which can enable efficient deployment on resource-constrained hardware.
• The researchers investigate whether models trained with QAT can maintain their performance on unseen datasets and tasks, addressing the common concern that quantization may degrade generalization.
Plain English Explanation
• The paper looks at a technique called quantization-aware training, or QAT, which is used to make AI models run more efficiently on devices with limited computing power, like smartphones.
• QAT reduces the precision of the numbers used in the AI model, which allows it to use less memory and do calculations faster. However, there's a concern that this reduction in precision could hurt the model's ability to work well on data it hasn't seen before.
• The researchers in this paper wanted to see if models trained using QAT could still perform well on new datasets and tasks, beyond just the ones used during the training process. This is important because if QAT hurts a model's ability to generalize, it could limit the real-world usefulness of the technique.
Technical Explanation
• The paper evaluates the generalization ability of models trained using QAT across different computer vision and natural language processing tasks and datasets.
• They compare the performance of full-precision models, models trained with standard quantization-aware training, and models trained with an extended QAT approach that incorporates additional techniques like layer-wise scaling and post-training quantization.
• The results show that models trained with QAT are able to maintain strong performance on unseen datasets and tasks, with the extended QAT approach providing additional generalization benefits in some cases.
• The paper also includes an analysis of the robustness of quantized neural networks to different types of adversarial attacks.
Critical Analysis
• The paper provides a thorough empirical evaluation of QAT's impact on model generalization, addressing an important practical concern around the deployment of quantized neural networks.
• However, the analysis is limited to a relatively narrow set of tasks and datasets, so further research would be needed to fully understand the generalization capabilities of QAT across a wider range of applications.
• Additionally, the paper does not explore the potential for hardware-aware quantization techniques to further improve the generalization of quantized models.
Conclusion
• This paper demonstrates that quantization-aware training can be an effective technique for improving the efficiency of neural networks without significantly compromising their ability to generalize to new datasets and tasks.
• The results suggest that QAT could be a valuable tool for deploying high-performing AI models on resource-constrained devices, while the analysis of adversarial robustness highlights the importance of considering security implications when using quantized models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
0
0
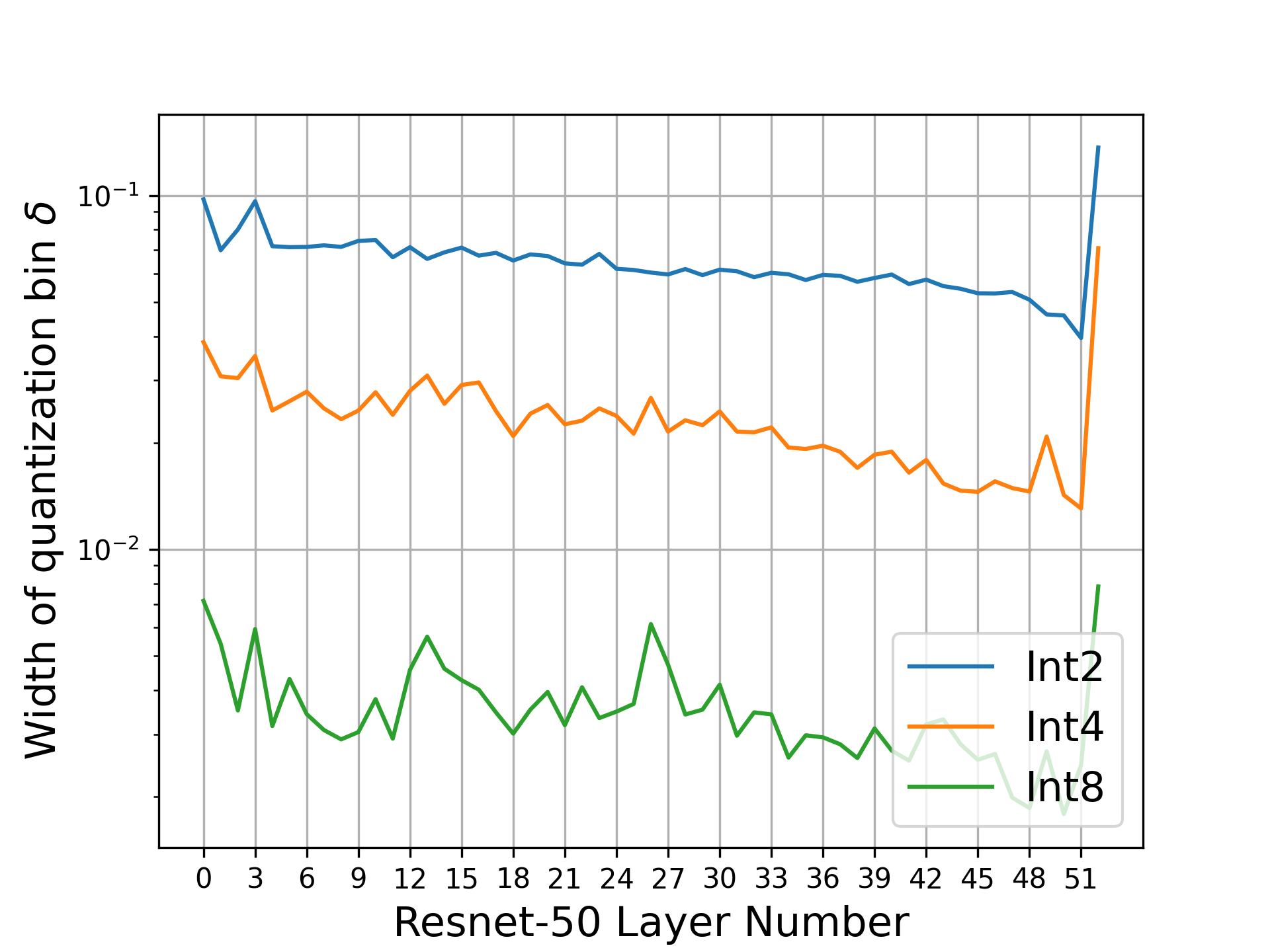
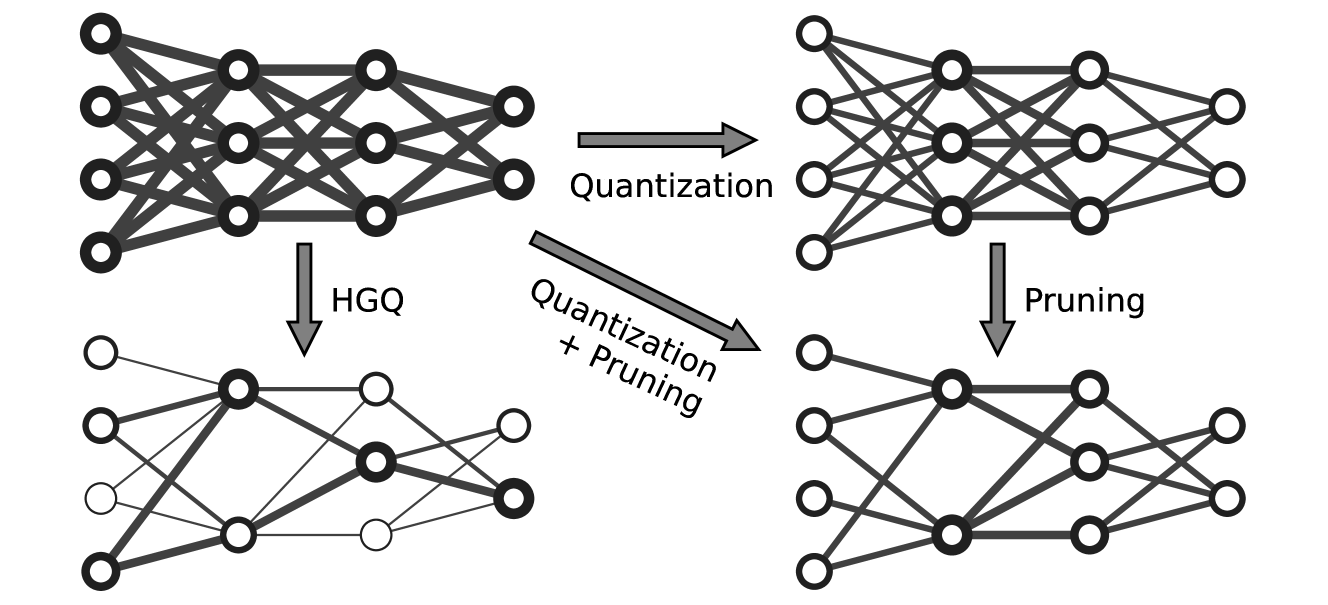
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
5/2/2024
Investigating the Impact of Quantization on Adversarial Robustness
Qun Li, Yuan Meng, Chen Tang, Jiacheng Jiang, Zhi Wang
0
0
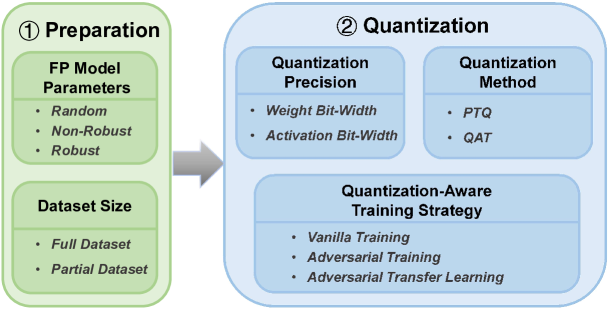
Quantization is a promising technique for reducing the bit-width of deep models to improve their runtime performance and storage efficiency, and thus becomes a fundamental step for deployment. In real-world scenarios, quantized models are often faced with adversarial attacks which cause the model to make incorrect inferences by introducing slight perturbations. However, recent studies have paid less attention to the impact of quantization on the model robustness. More surprisingly, existing studies on this topic even present inconsistent conclusions, which prompted our in-depth investigation. In this paper, we conduct a first-time analysis of the impact of the quantization pipeline components that can incorporate robust optimization under the settings of Post-Training Quantization and Quantization-Aware Training. Through our detailed analysis, we discovered that this inconsistency arises from the use of different pipelines in different studies, specifically regarding whether robust optimization is performed and at which quantization stage it occurs. Our research findings contribute insights into deploying more secure and robust quantized networks, assisting practitioners in reference for scenarios with high-security requirements and limited resources.
4/9/2024
🏋️
AdaQAT: Adaptive Bit-Width Quantization-Aware Training
C'edric Gernigon (TARAN), Silviu-Ioan Filip (TARAN), Olivier Sentieys (TARAN), Cl'ement Coggiola (CNES), Mickael Bruno (CNES)
0
0
Large-scale deep neural networks (DNNs) have achieved remarkable success in many application scenarios. However, high computational complexity and energy costs of modern DNNs make their deployment on edge devices challenging. Model quantization is a common approach to deal with deployment constraints, but searching for optimized bit-widths can be challenging. In this work, we present Adaptive Bit-Width Quantization Aware Training (AdaQAT), a learning-based method that automatically optimizes weight and activation signal bit-widths during training for more efficient DNN inference. We use relaxed real-valued bit-widths that are updated using a gradient descent rule, but are otherwise discretized for all quantization operations. The result is a simple and flexible QAT approach for mixed-precision uniform quantization problems. Compared to other methods that are generally designed to be run on a pretrained network, AdaQAT works well in both training from scratch and fine-tuning scenarios.Initial results on the CIFAR-10 and ImageNet datasets using ResNet20 and ResNet18 models, respectively, indicate that our method is competitive with other state-of-the-art mixed-precision quantization approaches.
4/29/2024
⛏️
Generalization with data-dependent quantum geometry
Tobias Haug, M. S. Kim
0
0
Generalization is the ability of machine learning models to make accurate predictions on new data by learning from training data. However, understanding generalization of quantum machine learning models has been a major challenge. Here, we introduce the data quantum Fisher information metric (DQFIM). It describes the capacity of variational quantum algorithms depending on variational ansatz, training data and their symmetries. We apply the DQFIM to quantify circuit parameters and training data needed to successfully train and generalize. Using the dynamical Lie algebra, we explain how to generalize using a low number of training states. Counter-intuitively, breaking symmetries of the training data can help to improve generalization. Finally, we find that out-of-distribution generalization, where training and testing data are drawn from different data distributions, can be better than using the same distribution. Our work provides a useful framework to explore the power of quantum machine learning models.
5/14/2024