A Grading Rubric for AI Safety Frameworks

0

Sign in to get full access
Overview
- This paper proposes a grading rubric for evaluating the safety and robustness of AI safety frameworks.
- The rubric covers key aspects such as problem scope, technical validity, and real-world applicability.
- Researchers can use the rubric to assess the strengths and weaknesses of different AI safety frameworks.
Plain English Explanation
As artificial intelligence (AI) systems become more advanced and widespread, ensuring their safety and reliability is crucial. AI safety frameworks are designed to help developers and researchers identify and mitigate potential risks associated with these systems.
This paper introduces a grading rubric that can be used to evaluate the quality and effectiveness of different AI safety frameworks. The rubric covers several key areas:
- Problem Scope: Does the framework address the right set of safety concerns and challenges facing AI systems?
- Technical Validity: Is the framework based on sound scientific principles and empirical evidence?
- Real-World Applicability: Can the framework be practically implemented and deployed in complex, real-world scenarios?
- Transparency and Explainability: Is the framework transparent and easy to understand, allowing for accountability and auditing?
- Generalizability: Can the framework be applied to a wide range of AI systems and domains, or is it narrowly focused?
By evaluating AI safety frameworks against these criteria, researchers and developers can better understand the strengths and weaknesses of different approaches, and work to improve the overall safety and trustworthiness of AI systems.
Technical Explanation
The paper presents a comprehensive grading rubric for evaluating AI safety frameworks, consisting of five key dimensions:
-
Problem Scope: This dimension assesses whether the framework addresses the right set of safety concerns, such as robustness to distributional shift, value alignment, and scalability, among others.
-
Technical Validity: This dimension examines the scientific soundness of the framework, including the quality of the underlying theory, the rigor of the empirical evaluation, and the strength of the technical implementation.
-
Real-World Applicability: This dimension evaluates the framework's ability to be effectively deployed in complex, real-world scenarios, considering factors such as computational efficiency, data requirements, and ease of integration with existing systems.
-
Transparency and Explainability: This dimension assesses the framework's level of transparency, interpretability, and explainability, which are crucial for building trust and enabling effective auditing and oversight.
-
Generalizability: This dimension considers the framework's ability to be applied across a wide range of AI systems and domains, rather than being narrowly focused on a specific use case or problem.
The paper provides detailed rubrics and scoring guidelines for each of these dimensions, allowing researchers and developers to systematically evaluate the strengths and weaknesses of different AI safety frameworks.
Critical Analysis
The proposed grading rubric is a valuable tool for the AI research community, as it provides a structured way to assess the quality and effectiveness of AI safety frameworks. By focusing on key aspects such as problem scope, technical validity, and real-world applicability, the rubric helps to identify frameworks that are truly robust and practical for deployment in complex, safety-critical environments.
One potential limitation of the rubric is that it may not capture all the nuances and context-specific considerations that can arise when evaluating AI safety frameworks. The authors acknowledge this and suggest that the rubric should be used as a starting point for more in-depth analysis and discussion.
Additionally, the rubric does not directly address the challenge of aligning AI systems with human values and preferences, which is a critical aspect of AI safety. While this is touched upon in the "Problem Scope" dimension, a more explicit focus on value alignment may be beneficial.
Overall, the grading rubric presented in this paper is a valuable contribution to the field of AI safety, and it can serve as a foundation for further research and development in this important area.
Conclusion
This paper introduces a comprehensive grading rubric for evaluating the safety and robustness of AI safety frameworks. The rubric covers key dimensions such as problem scope, technical validity, real-world applicability, transparency, and generalizability, providing a structured way for researchers and developers to assess the strengths and weaknesses of different approaches.
By using this rubric, the AI research community can better identify and improve upon the most promising AI safety frameworks, ultimately contributing to the development of more reliable and trustworthy AI systems that can be safely deployed in real-world, safety-critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Grading Rubric for AI Safety Frameworks
Jide Alaga, Jonas Schuett, Markus Anderljung
Over the past year, artificial intelligence (AI) companies have been increasingly adopting AI safety frameworks. These frameworks outline how companies intend to keep the potential risks associated with developing and deploying frontier AI systems to an acceptable level. Major players like Anthropic, OpenAI, and Google DeepMind have already published their frameworks, while another 13 companies have signaled their intent to release similar frameworks by February 2025. Given their central role in AI companies' efforts to identify and address unacceptable risks from their systems, AI safety frameworks warrant significant scrutiny. To enable governments, academia, and civil society to pass judgment on these frameworks, this paper proposes a grading rubric. The rubric consists of seven evaluation criteria and 21 indicators that concretize the criteria. Each criterion can be graded on a scale from A (gold standard) to F (substandard). The paper also suggests three methods for applying the rubric: surveys, Delphi studies, and audits. The purpose of the grading rubric is to enable nuanced comparisons between frameworks, identify potential areas of improvement, and promote a race to the top in responsible AI development.
Read more9/16/2024

0
An AI System Evaluation Framework for Advancing AI Safety: Terminology, Taxonomy, Lifecycle Mapping
Boming Xia, Qinghua Lu, Liming Zhu, Zhenchang Xing
The advent of advanced AI underscores the urgent need for comprehensive safety evaluations, necessitating collaboration across communities (i.e., AI, software engineering, and governance). However, divergent practices and terminologies across these communities, combined with the complexity of AI systems-of which models are only a part-and environmental affordances (e.g., access to tools), obstruct effective communication and comprehensive evaluation. This paper proposes a framework for AI system evaluation comprising three components: 1) harmonised terminology to facilitate communication across communities involved in AI safety evaluation; 2) a taxonomy identifying essential elements for AI system evaluation; 3) a mapping between AI lifecycle, stakeholders, and requisite evaluations for accountable AI supply chain. This framework catalyses a deeper discourse on AI system evaluation beyond model-centric approaches.
Read more5/17/2024

0
Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework for AI Safety with Challenges and Mitigations
Chen Chen, Ziyao Liu, Weifeng Jiang, Si Qi Goh, Kwok-Yan Lam
AI Safety is an emerging area of critical importance to the safe adoption and deployment of AI systems. With the rapid proliferation of AI and especially with the recent advancement of Generative AI (or GAI), the technology ecosystem behind the design, development, adoption, and deployment of AI systems has drastically changed, broadening the scope of AI Safety to address impacts on public safety and national security. In this paper, we propose a novel architectural framework for understanding and analyzing AI Safety; defining its characteristics from three perspectives: Trustworthy AI, Responsible AI, and Safe AI. We provide an extensive review of current research and advancements in AI safety from these perspectives, highlighting their key challenges and mitigation approaches. Through examples from state-of-the-art technologies, particularly Large Language Models (LLMs), we present innovative mechanism, methodologies, and techniques for designing and testing AI safety. Our goal is to promote advancement in AI safety research, and ultimately enhance people's trust in digital transformation.
Read more9/14/2024
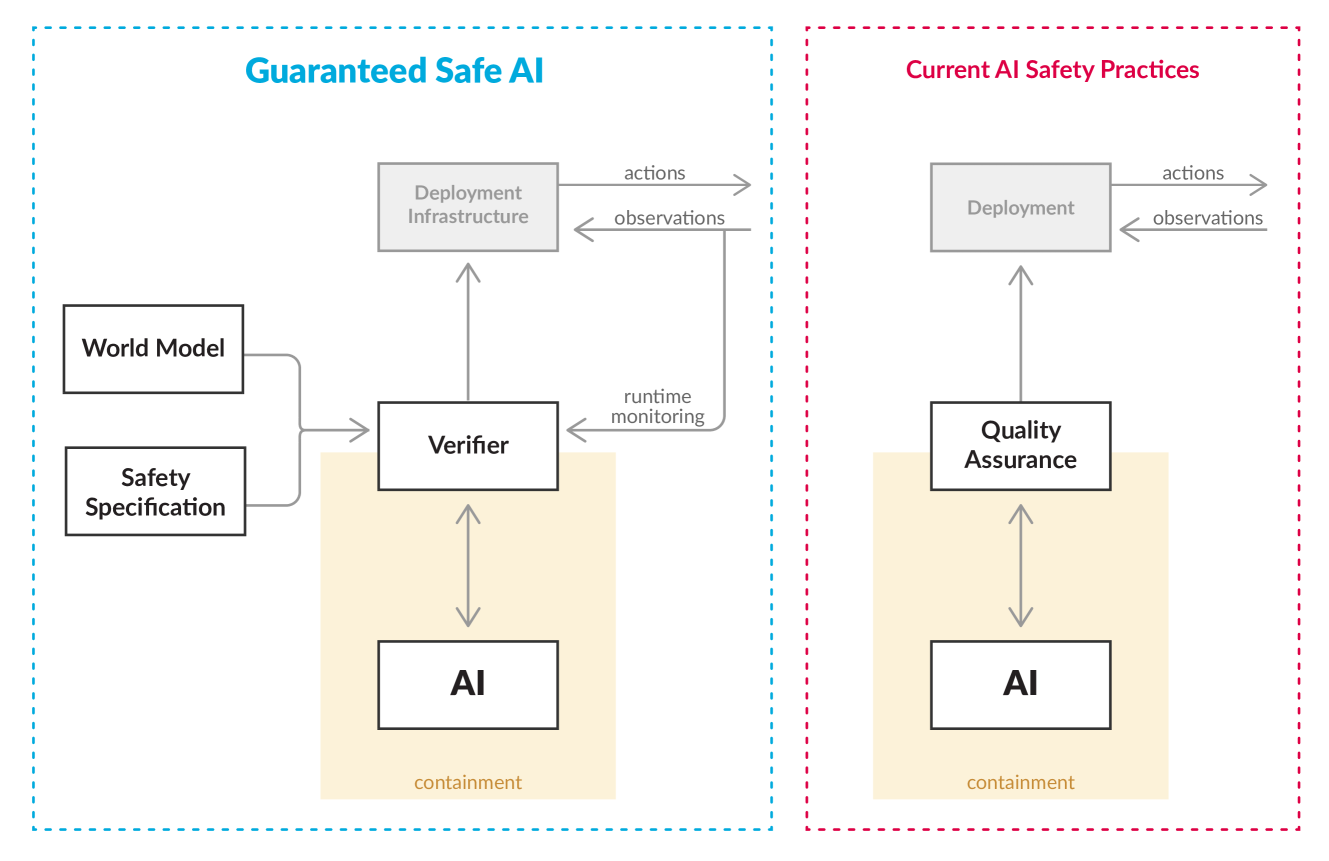
2
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
David davidad Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, Joshua Tenenbaum
Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Read more7/9/2024