Grasper: A Generalist Pursuer for Pursuit-Evasion Problems

0

Sign in to get full access
Overview
- This paper introduces Grasper, a generalist pursuer agent for solving pursuit-evasion problems.
- Pursuit-evasion problems involve an agent (the pursuer) trying to catch another agent (the evader) in a dynamic environment.
- Grasper is designed to be able to handle a wide variety of pursuit-evasion scenarios, rather than being specialized for a particular set of environments or tasks.
Plain English Explanation
Grasper is a type of artificial intelligence (AI) agent that is designed to be able to play a "cat-and-mouse" style game, where one agent (the pursuer) is trying to catch another agent (the evader). The key innovation of Grasper is that it is a "generalist" - meaning it is not specialized for just one type of pursuit-evasion scenario, but can handle a wide variety of different environments and rules.
Typically, AI agents for pursuit-evasion problems are trained on a specific set of environments and struggle to perform well outside of those. Grasper, on the other hand, is trained in a more general way, allowing it to adapt to new pursuit-evasion scenarios more effectively. This makes Grasper a more flexible and versatile AI system compared to more specialized agents.
The researchers who developed Grasper believe that this generalist approach has important practical applications, such as in robotics, autonomous vehicles, and computer games. By having an AI agent that can handle a wide variety of pursuit-evasion tasks, it becomes more useful and applicable in the real world.
Technical Explanation
The core of Grasper is a neural network architecture that consists of a pre-trained foundation model combined with a hypernetwork that allows the model to quickly adapt to new pursuit-evasion scenarios. This "pre-training and fine-tuning" approach enables Grasper to leverage general knowledge about the world while still being able to specialize for specific tasks.
The researchers evaluate Grasper on a diverse set of pursuit-evasion benchmark environments, including maze-like settings, continuous navigation scenarios, and multi-agent competitive games. They show that Grasper is able to outperform specialized pursuit agents across these different settings, demonstrating the benefits of the generalist approach.
Critical Analysis
The key strength of Grasper is its ability to adapt to a wide variety of pursuit-evasion problems. This versatility is important for real-world applications, where the specific environment or task may not be known in advance. However, the paper does not fully address the potential limitations of this approach.
For example, it is unclear how Grasper would perform in extremely complex or high-stakes environments, where specialized solutions may be necessary. Additionally, the paper does not explore the computational and resource requirements of the Grasper architecture, which could be a practical concern for deployment.
Overall, the Grasper approach is a promising direction for pursuit-evasion AI, but further research is needed to fully understand its capabilities and limitations across a broader range of scenarios.
Conclusion
This paper introduces Grasper, a generalist pursuer agent that can adapt to a wide variety of pursuit-evasion problems. By combining a pre-trained foundation model with a hypernetwork, Grasper is able to leverage general knowledge while still specializing for specific tasks.
The results demonstrate the benefits of this generalist approach, with Grasper outperforming specialized pursuit agents across diverse benchmark environments. This suggests that Grasper could have valuable real-world applications in areas like robotics, autonomous vehicles, and computer games.
While further research is needed to fully understand Grasper's capabilities and limitations, this work represents an important step forward in the development of more versatile and adaptable AI systems for pursuit-evasion problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Grasper: A Generalist Pursuer for Pursuit-Evasion Problems
Pengdeng Li, Shuxin Li, Xinrun Wang, Jakub Cerny, Youzhi Zhang, Stephen McAleer, Hau Chan, Bo An
Pursuit-evasion games (PEGs) model interactions between a team of pursuers and an evader in graph-based environments such as urban street networks. Recent advancements have demonstrated the effectiveness of the pre-training and fine-tuning paradigm in PSRO to improve scalability in solving large-scale PEGs. However, these methods primarily focus on specific PEGs with fixed initial conditions that may vary substantially in real-world scenarios, which significantly hinders the applicability of the traditional methods. To address this issue, we introduce Grasper, a GeneRAlist purSuer for Pursuit-Evasion pRoblems, capable of efficiently generating pursuer policies tailored to specific PEGs. Our contributions are threefold: First, we present a novel architecture that offers high-quality solutions for diverse PEGs, comprising critical components such as (i) a graph neural network (GNN) to encode PEGs into hidden vectors, and (ii) a hypernetwork to generate pursuer policies based on these hidden vectors. As a second contribution, we develop an efficient three-stage training method involving (i) a pre-pretraining stage for learning robust PEG representations through self-supervised graph learning techniques like GraphMAE, (ii) a pre-training stage utilizing heuristic-guided multi-task pre-training (HMP) where heuristic-derived reference policies (e.g., through Dijkstra's algorithm) regularize pursuer policies, and (iii) a fine-tuning stage that employs PSRO to generate pursuer policies on designated PEGs. Finally, we perform extensive experiments on synthetic and real-world maps, showcasing Grasper's significant superiority over baselines in terms of solution quality and generalizability. We demonstrate that Grasper provides a versatile approach for solving pursuit-evasion problems across a broad range of scenarios, enabling practical deployment in real-world situations.
Read more4/22/2024

0
Learning to Play Pursuit-Evasion with Dynamic and Sensor Constraints
Burak M. Gonultas, Volkan Isler
We present a multi-agent reinforcement learning approach to solve a pursuit-evasion game between two players with car-like dynamics and sensing limitations. We develop a curriculum for an existing multi-agent deterministic policy gradient algorithm to simultaneously obtain strategies for both players, and deploy the learned strategies on real robots moving as fast as 2 m/s in indoor environments. Through experiments we show that the learned strategies improve over existing baselines by up to 30% in terms of capture rate for the pursuer. The learned evader model has up to 5% better escape rate over the baselines even against our competitive pursuer model. We also present experiment results which show how the pursuit-evasion game and its results evolve as the player dynamics and sensor constraints are varied. Finally, we deploy learned policies on physical robots for a game between the F1TENTH and JetRacer platforms and show that the learned strategies can be executed on real-robots. Our code and supplementary material including videos from experiments are available at https: //gonultasbu.github.io/pursuit-evasion/.
Read more5/10/2024
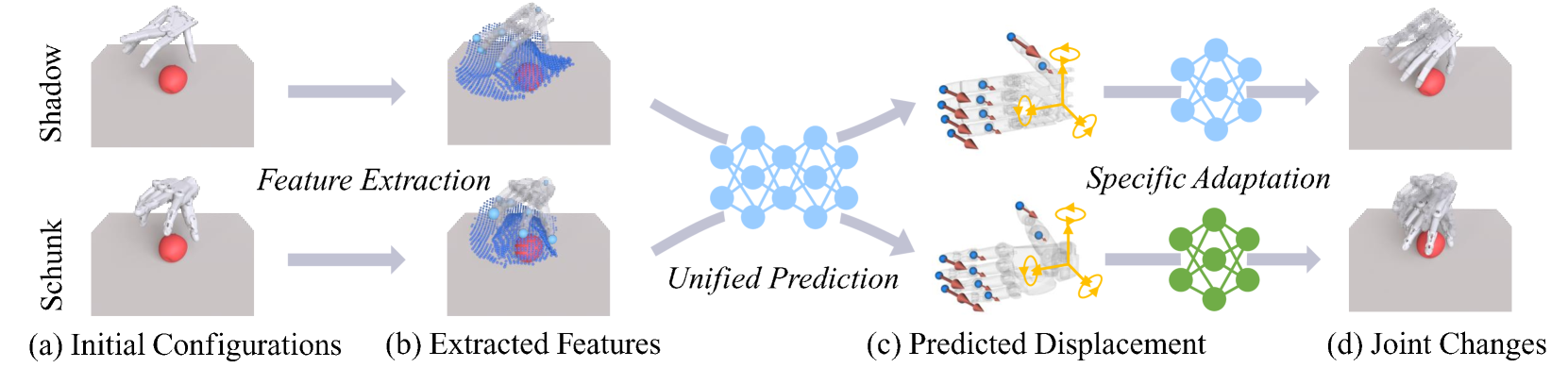
0
Learning Cross-hand Policies for High-DOF Reaching and Grasping
Qijin She, Shishun Zhang, Yunfan Ye, Ruizhen Hu, Kai Xu
Reaching-and-grasping is a fundamental skill for robotic manipulation, but existing methods usually train models on a specific gripper and cannot be reused on another gripper. In this paper, we propose a novel method that can learn a unified policy model that can be easily transferred to different dexterous grippers. Our method consists of two stages: a gripper-agnostic policy model that predicts the displacements of pre-defined key points on the gripper, and a gripper-specific adaptation model that translates these displacements into adjustments for controlling the grippers' joints. The gripper state and interactions with objects are captured at the finger level using robust geometric representations, integrated with a transformer-based network to address variations in gripper morphology and geometry. In the experiments, we evaluate our method on several dexterous grippers and diverse objects, and the result shows that our method significantly outperforms the baseline methods. Pioneering the transfer of grasp policies across dexterous grippers, our method effectively demonstrates its potential for learning generalizable and transferable manipulation skills for various robotic hands.
Read more7/16/2024

0
MPGNet: Learning Move-Push-Grasping Synergy for Target-Oriented Grasping in Occluded Scenes
Dayou Li, Chenkun Zhao, Shuo Yang, Ran Song, Xiaolei Li, Wei Zhang
This paper focuses on target-oriented grasping in occluded scenes, where the target object is specified by a binary mask and the goal is to grasp the target object with as few robotic manipulations as possible. Most existing methods rely on a push-grasping synergy to complete this task. To deliver a more powerful target-oriented grasping pipeline, we present MPGNet, a three-branch network for learning a synergy between moving, pushing, and grasping actions. We also propose a multi-stage training strategy to train the MPGNet which contains three policy networks corresponding to the three actions. The effectiveness of our method is demonstrated via both simulated and real-world experiments.
Read more8/21/2024