GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robot

0
Sign in to get full access
Overview
- This paper presents a Generalist Robotic Model (GeRM) that uses a mixture-of-experts approach to enable quadruped robots to perform a wide range of tasks.
- The model aims to address the challenges of developing versatile and adaptable robotic systems by combining multiple specialized models into a single generalist framework.
- The paper describes the architecture of GeRM and demonstrates its performance on various locomotion and manipulation tasks using a quadruped robot.
Plain English Explanation
The researchers have developed a new kind of robotic system called the Generalist Robotic Model (GeRM) that can be used to control a four-legged (quadruped) robot. The key idea behind GeRM is to combine multiple specialized models, each trained to perform a specific task, into a single, more versatile system.
Traditionally, robotic systems have been designed to excel at a particular set of tasks, such as walking or picking up objects. However, this specialization can limit the robot's adaptability and make it challenging to deploy in real-world environments that require a wide range of capabilities. The GeRM approach aims to address this by leveraging a "mixture-of-experts" technique, where the robot can draw on different specialized models as needed to tackle different types of tasks.
For example, the robot might use one specialized model for walking on flat ground, another for navigating uneven terrain, and a third for manipulating objects. By seamlessly switching between these experts, the robot can adapt to a variety of situations and perform a much broader range of activities than a traditional, specialized system.
The researchers have demonstrated the GeRM system's effectiveness by testing it on a range of locomotion and manipulation tasks using a quadruped robot. The results show that the GeRM model can enable the robot to navigate complex environments, pick up and manipulate objects, and even combine these skills to perform more complex, multi-step tasks.
Technical Explanation
The researchers propose a Generalist Robotic Model (GeRM) that uses a mixture-of-experts approach to enable quadruped robots to perform a wide variety of tasks. The model is designed to address the challenge of developing versatile and adaptable robotic systems, which often struggle to generalize beyond the specific tasks they were trained for.
The GeRM architecture consists of several specialized expert models, each trained on a different set of skills, such as locomotion or object manipulation. These experts are then combined using a gating network that dynamically selects the most appropriate expert(s) for the current task. This allows the robot to seamlessly switch between different capabilities as needed, rather than being limited to a fixed set of skills.
The researchers evaluate the GeRM model on a range of locomotion and manipulation tasks using a quadruped robot platform. The results demonstrate the model's ability to adapt to different environments and challenges, outperforming traditional specialized models. For example, the robot is able to navigate complex terrains, pick up and manipulate objects, and even combine these skills to perform more complex, multi-step tasks.
Critical Analysis
The paper presents a promising approach to developing versatile and adaptable robotic systems, but there are a few potential limitations and areas for further research:
-
Task Generalization: While the GeRM model demonstrates strong performance on the specific tasks evaluated in the paper, it is unclear how well it would generalize to a broader range of real-world scenarios. Further testing on a wider variety of tasks and environments would be valuable to assess the model's true generalization capabilities.
-
Interpretability and Explainability: The mixture-of-experts approach used in GeRM can be challenging to interpret and understand, as the model's decision-making process is distributed across multiple specialized experts. Improving the interpretability and explainability of the model could be an important area for future research, especially for applications where transparency and accountability are critical.
-
Computational Efficiency: Maintaining multiple expert models and a gating network may introduce significant computational overhead, which could be a concern for real-time robotics applications. Exploring ways to optimize the GeRM architecture for efficiency would be an important area of further investigation.
-
Integration with Other Robotic Frameworks: The paper does not discuss how the GeRM model could be integrated with other robotic frameworks, such as RobotMP or Long-Horizon Locomotion and Manipulation. Exploring these integration possibilities could help expand the capabilities and versatility of the GeRM system even further.
Overall, the GeRM paper presents an interesting and potentially impactful approach to developing more adaptable and capable robotic systems. However, further research and refinement will be needed to address the limitations and fully realize the potential of this technology.
Conclusion
The Generalist Robotic Model (GeRM) presented in this paper offers a promising solution to the challenge of creating versatile and adaptable robotic systems. By leveraging a mixture-of-experts approach, the GeRM model can dynamically combine specialized skills to tackle a wide range of tasks, rather than being limited to a fixed set of capabilities.
The demonstrated performance of the GeRM system on a quadruped robot suggests that this technology could have significant implications for the field of robotics, enabling the development of more capable and adaptable systems that can thrive in complex, real-world environments. As the researchers continue to refine and expand the GeRM model, it will be exciting to see how this technology evolves and its potential applications, from multimodal perception and planning to long-horizon locomotion and manipulation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robot
Wenxuan Song, Han Zhao, Pengxiang Ding, Can Cui, Shangke Lyu, Yaning Fan, Donglin Wang
Multi-task robot learning holds significant importance in tackling diverse and complex scenarios. However, current approaches are hindered by performance issues and difficulties in collecting training datasets. In this paper, we propose GeRM (Generalist Robotic Model). We utilize offline reinforcement learning to optimize data utilization strategies to learn from both demonstrations and sub-optimal data, thus surpassing the limitations of human demonstrations. Thereafter, we employ a transformer-based VLA network to process multi-modal inputs and output actions. By introducing the Mixture-of-Experts structure, GeRM allows faster inference speed with higher whole model capacity, and thus resolves the issue of limited RL parameters, enhancing model performance in multi-task learning while controlling computational costs. Through a series of experiments, we demonstrate that GeRM outperforms other methods across all tasks, while also validating its efficiency in both training and inference processes. Additionally, we uncover its potential to acquire emergent skills. Additionally, we contribute the QUARD-Auto dataset, collected automatically to support our training approach and foster advancements in multi-task quadruped robot learning. This work presents a new paradigm for reducing the cost of collecting robot data and driving progress in the multi-task learning community. You can reach our project and video through the link: https://songwxuan.github.io/GeRM/ .
Read more4/10/2024

0
GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy
Peiyan Li, Hongtao Wu, Yan Huang, Chilam Cheang, Liang Wang, Tao Kong
The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One of the primary challenges is that obtaining robot data fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially annotated data, such as human activity videos without action labels and robot play data without language labels, is much easier to collect. Can we leverage these data to enhance the generalization capability of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on both a language instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is unavailable. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and condition on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially annotated data while still using language to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process, significantly improving the fidelity and the performance. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 47 different tasks and improves the success rate from 62.5% to 75.0% and 42.4% to 57.6% in simple and generalization settings, respectively. Code and checkpoints will be available at the project page: https://gr-mg.github.io/.
Read more8/27/2024

0
RoboCoder: Robotic Learning from Basic Skills to General Tasks with Large Language Models
Jingyao Li, Pengguang Chen, Sitong Wu, Chuanyang Zheng, Hong Xu, Jiaya Jia
The emergence of Large Language Models (LLMs) has improved the prospects for robotic tasks. However, existing benchmarks are still limited to single tasks with limited generalization capabilities. In this work, we introduce a comprehensive benchmark and an autonomous learning framework, RoboCoder aimed at enhancing the generalization capabilities of robots in complex environments. Unlike traditional methods that focus on single-task learning, our research emphasizes the development of a general-purpose robotic coding algorithm that enables robots to leverage basic skills to tackle increasingly complex tasks. The newly proposed benchmark consists of 80 manually designed tasks across 7 distinct entities, testing the models' ability to learn from minimal initial mastery. Initial testing revealed that even advanced models like GPT-4 could only achieve a 47% pass rate in three-shot scenarios with humanoid entities. To address these limitations, the RoboCoder framework integrates Large Language Models (LLMs) with a dynamic learning system that uses real-time environmental feedback to continuously update and refine action codes. This adaptive method showed a remarkable improvement, achieving a 36% relative improvement. Our codes will be released.
Read more6/7/2024
0
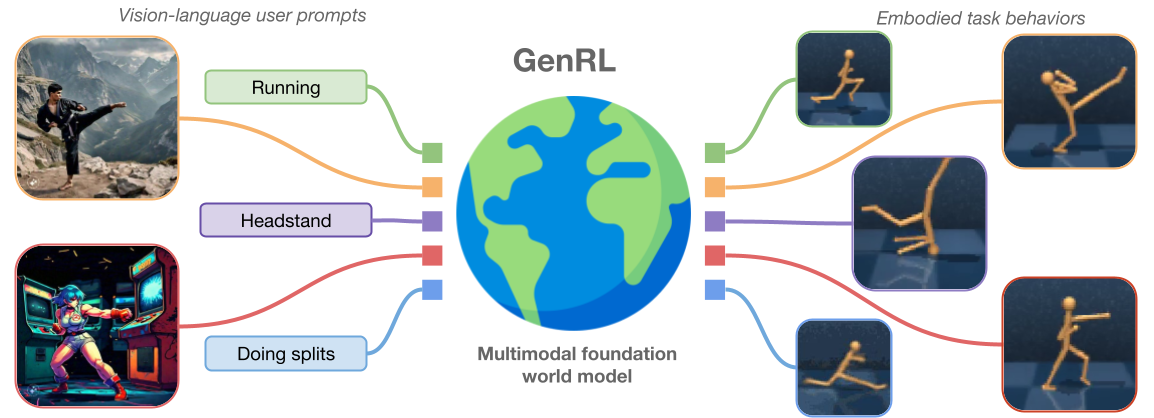
Multimodal foundation world models for generalist embodied agents
Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, Sai Rajeswar
Learning generalist embodied agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning (RL) is hard to scale up as it requires a complex reward design for each task. In contrast, language can specify tasks in a more natural way. Current foundation vision-language models (VLMs) generally require fine-tuning or other adaptations to be functional, due to the significant domain gap. However, the lack of multimodal data in such domains represents an obstacle toward developing foundation models for embodied applications. In this work, we overcome these problems by presenting multimodal foundation world models, able to connect and align the representation of foundation VLMs with the latent space of generative world models for RL, without any language annotations. The resulting agent learning framework, GenRL, allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain's dynamics, and learns the corresponding behaviors in imagination. As assessed through large-scale multi-task benchmarking, GenRL exhibits strong multi-task generalization performance in several locomotion and manipulation domains. Furthermore, by introducing a data-free RL strategy, it lays the groundwork for foundation model-based RL for generalist embodied agents.
Read more6/27/2024