Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos

0

Sign in to get full access
Overview
- This paper presents a novel approach for grounded multi-hop video question answering (VideoQA) in long-form egocentric videos.
- The proposed method aims to address the challenge of answering complex, multi-step questions that require reasoning over extended video sequences.
- The research involves designing an architecture that can efficiently process and ground information from long-form videos to answer multi-hop questions.
Plain English Explanation
The paper focuses on a specific type of video question answering, where the goal is to answer complex questions that require piecing together information from different parts of a long video. This is a challenging task because the relevant information may be spread out across the video, and the questions may involve multiple steps of reasoning.
To address this, the researchers developed a new model that can effectively process and understand the content of long videos. The model is designed to "ground" the relevant information from the video to the specific details needed to answer the multi-step question. This grounding process helps the model connect the dots and understand the full context required to provide a complete answer.
The key innovation is the model's ability to efficiently navigate and extract the necessary information from extended video sequences, rather than just looking at a single snapshot or short clip. This allows the model to truly understand the broader context and relationships between different events and details in the video.
Technical Explanation
The paper proposes a novel Grounded Multi-Hop VideoQA model for answering complex, multi-step questions in the context of long-form egocentric videos. The model consists of several key components:
- Video Encoder: This module processes the input video and extracts meaningful visual and temporal features.
- Question Encoder: The question is encoded into a semantic representation that can be used for cross-modal reasoning.
- Grounding Module: This is the core innovation of the model. It learns to ground relevant video information to the specific details required to answer the multi-step question.
- Multi-Hop Reasoning: By iteratively attending to and extracting information from the grounded video representation, the model can perform the necessary multi-hop reasoning to arrive at the final answer.
The key technical contributions include the design of the grounding module, which enables efficient and effective extraction of relevant video information, as well as the multi-hop reasoning mechanism that allows the model to tackle complex, multi-step questions.
Critical Analysis
The paper presents a solid technical approach to the challenging problem of grounded multi-hop VideoQA in long-form egocentric videos. The authors have thoughtfully designed the model components and the overall architecture to address the key challenges in this domain.
One potential limitation is the reliance on the specific video and question dataset used for evaluation. While the dataset is well-suited for the task, it would be interesting to see how the model generalizes to other video domains and question types. Additionally, the paper does not fully explore the model's interpretability - it would be helpful to understand the inner workings of the grounding and reasoning modules in more detail.
Further research could also investigate ways to improve the model's efficiency and scalability, as processing long-form videos can be computationally intensive. Exploring techniques to selectively focus on the most relevant video segments, for example, could be a fruitful direction.
Conclusion
This paper presents a novel approach to the challenging problem of grounded multi-hop VideoQA in long-form egocentric videos. The proposed model leverages a carefully designed grounding module and multi-hop reasoning mechanism to effectively extract and connect relevant information from extended video sequences to answer complex, multi-step questions.
The technical contributions and the model's strong performance on the evaluation dataset suggest that this research represents a significant step forward in the field of video understanding and question answering. The insights and techniques developed in this work could have broader implications for a range of applications, from assistive technologies to educational tools, that involve reasoning over long-form visual data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
Qirui Chen, Shangzhe Di, Weidi Xie
This paper considers the problem of Multi-Hop Video Question Answering (MH-VidQA) in long-form egocentric videos. This task not only requires to answer visual questions, but also to localize multiple relevant time intervals within the video as visual evidences. We develop an automated pipeline to create multi-hop question-answering pairs with associated temporal evidence, enabling to construct a large-scale dataset for instruction-tuning. To monitor the progress of this new task, we further curate a high-quality benchmark, MultiHop-EgoQA, with careful manual verification and refinement. Experimental results reveal that existing multi-modal systems exhibit inadequate multi-hop grounding and reasoning abilities, resulting in unsatisfactory performance. We then propose a novel architecture, termed as Grounding Scattered Evidence with Large Language Model (GeLM), that enhances multi-modal large language models (MLLMs) by incorporating a grounding module to retrieve temporal evidence from videos using flexible grounding tokens. Trained on our visual instruction data, GeLM demonstrates improved multi-hop grounding and reasoning capabilities, setting a new baseline for this challenging task. Furthermore, when trained on third-person view videos, the same architecture also achieves state-of-the-art performance on the single-hop VidQA benchmark, ActivityNet-RTL, demonstrating its effectiveness.
Read more8/27/2024

0
Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
Haibo Wang, Chenghang Lai, Yixuan Sun, Weifeng Ge
Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently, by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we first fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments and pseudo-labels, with the visual-language alignment capability of the CLIP models. With these pseudo-labeled keyframes as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
Read more7/24/2024
0
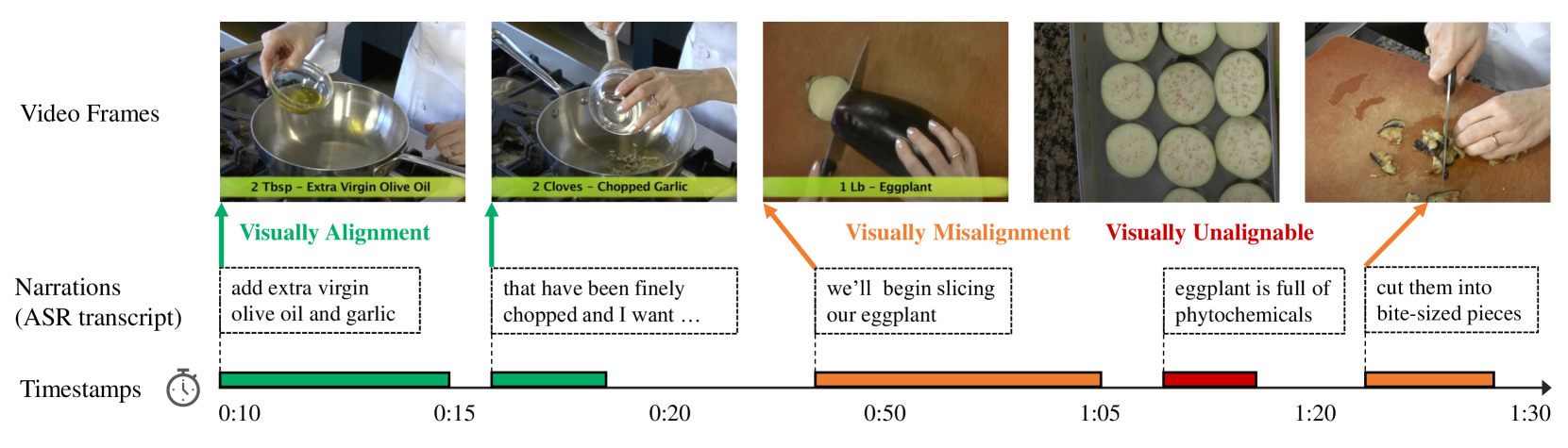
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024

0
Infusing Environmental Captions for Long-Form Video Language Grounding
Hyogun Lee, Soyeon Hong, Mujeen Sung, Jinwoo Choi
In this work, we tackle the problem of long-form video-language grounding (VLG). Given a long-form video and a natural language query, a model should temporally localize the precise moment that answers the query. Humans can easily solve VLG tasks, even with arbitrarily long videos, by discarding irrelevant moments using extensive and robust knowledge gained from experience. Unlike humans, existing VLG methods are prone to fall into superficial cues learned from small-scale datasets, even when they are within irrelevant frames. To overcome this challenge, we propose EI-VLG, a VLG method that leverages richer textual information provided by a Multi-modal Large Language Model (MLLM) as a proxy for human experiences, helping to effectively exclude irrelevant frames. We validate the effectiveness of the proposed method via extensive experiments on a challenging EgoNLQ benchmark.
Read more8/7/2024