Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned (Survey)

0
💬
Sign in to get full access
Overview
- Grounding and evaluation of large language models (LLMs) are critical for ensuring their safety, reliability, and responsible development
- The paper discusses practical challenges and lessons learned from grounding and evaluating LLMs, covering topics like truthfulness, safety and alignment, bias and fairness, model robustness and security, privacy, and more
- The authors draw on their extensive experience working on LLM development and evaluation to provide insights that can guide future research and real-world deployment
Plain English Explanation
Large language models (LLMs) like GPT-3 and ChatGPT have become increasingly powerful and capable, but ensuring they behave in a safe, reliable, and responsible manner is a major challenge. The paper "Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned" discusses the practical issues involved in rigorously evaluating and 'grounding' these models - that is, making sure they have a solid understanding of the real world and act in accordance with human values and ethics.
The authors, who have extensive experience working on LLM development and testing, cover a wide range of topics. This includes ensuring the truthfulness and factual accuracy of LLM outputs, aligning them with human safety and ethics, identifying and mitigating biases and unfairness, maintaining model robustness and security, protecting user privacy, and dealing with issues like copyright infringement and the model's ability to 'unlearn' harmful knowledge.
The paper provides real-world examples and practical insights that can guide future research and development in this critical area. By addressing these challenges head-on, the authors hope to help ensure that LLMs are deployed in a way that benefits society while mitigating potential risks and harms.
Technical Explanation
The paper "Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned" explores the practical challenges involved in rigorously evaluating and 'grounding' large language models (LLMs) to ensure their safety, reliability, and responsible development.
The authors draw on their extensive experience working on LLM systems to cover a wide range of topics. This includes ensuring the truthfulness and factual accuracy of LLM outputs, aligning them with human values and ethics for safety and alignment, identifying and mitigating biases and unfairness, maintaining model robustness and security, protecting user privacy, and addressing issues like copyright infringement and the model's ability to 'unlearn' harmful knowledge.
The paper presents a range of techniques and methodologies for evaluating these different aspects of LLM behavior, including human evaluation, automated metrics, edge case testing, and probing for specific capabilities and limitations. The authors also discuss the challenges of calibrating model confidence and achieving transparency around the models' inner workings and causal reasoning.
Throughout the paper, the authors share practical insights and lessons learned from their work, highlighting the importance of a multi-faceted, holistic approach to LLM evaluation and grounding. By addressing these challenges head-on, the research aims to guide the responsible development and deployment of LLMs in a way that maximizes their benefits while mitigating potential risks and harms.
Critical Analysis
The paper "Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned" provides a comprehensive and insightful overview of the critical challenges involved in ensuring the safety, reliability, and responsible development of large language models (LLMs).
The authors' extensive experience working on LLM systems lends credibility to the practical insights and lessons they share. By covering a wide range of topics, from truthfulness and factual accuracy to bias and fairness, the paper offers a comprehensive perspective on the challenges of LLM grounding and evaluation.
However, the paper could potentially be strengthened by delving deeper into some of the more complex and contentious issues, such as the challenges of aligning LLMs with human values and ethics or the difficulties of achieving transparency and interpretability in these highly complex models.
Additionally, while the paper covers a wide range of topics, some readers may find it useful to have more detailed case studies or concrete examples to illustrate the practical challenges and lessons learned. This could help bridge the gap between the theoretical concepts and the real-world application of LLM grounding and evaluation.
Overall, the paper offers a valuable contribution to the ongoing dialogue around the responsible development of large language models. By highlighting the critical challenges and sharing practical insights, the authors provide a roadmap for future research and development in this rapidly evolving field.
Conclusion
The paper "Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned" presents a comprehensive overview of the practical challenges and lessons learned in the process of grounding and evaluating large language models (LLMs).
The authors' extensive experience working on LLM systems gives them a unique perspective on the multifaceted issues involved, from ensuring truthfulness and factual accuracy to addressing bias and fairness, maintaining model robustness and security, and protecting user privacy.
By sharing these practical insights and lessons learned, the paper aims to guide future research and development in the responsible deployment of LLMs, ensuring they are designed and used in a way that maximizes their benefits while mitigating potential risks and harms to society. As the field of large language models continues to rapidly evolve, this paper provides a valuable resource for researchers, developers, and policymakers navigating the complex landscape of LLM grounding and evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Grounding and Evaluation for Large Language Models: Practical Challenges and Lessons Learned (Survey)
Krishnaram Kenthapadi, Mehrnoosh Sameki, Ankur Taly
With the ongoing rapid adoption of Artificial Intelligence (AI)-based systems in high-stakes domains, ensuring the trustworthiness, safety, and observability of these systems has become crucial. It is essential to evaluate and monitor AI systems not only for accuracy and quality-related metrics but also for robustness, bias, security, interpretability, and other responsible AI dimensions. We focus on large language models (LLMs) and other generative AI models, which present additional challenges such as hallucinations, harmful and manipulative content, and copyright infringement. In this survey article accompanying our KDD 2024 tutorial, we highlight a wide range of harms associated with generative AI systems, and survey state of the art approaches (along with open challenges) to address these harms.
Read more7/19/2024

0
AI Safety in Generative AI Large Language Models: A Survey
Jaymari Chua, Yun Li, Shiyi Yang, Chen Wang, Lina Yao
Large Language Model (LLMs) such as ChatGPT that exhibit generative AI capabilities are facing accelerated adoption and innovation. The increased presence of Generative AI (GAI) inevitably raises concerns about the risks and safety associated with these models. This article provides an up-to-date survey of recent trends in AI safety research of GAI-LLMs from a computer scientist's perspective: specific and technical. In this survey, we explore the background and motivation for the identified harms and risks in the context of LLMs being generative language models; our survey differentiates by emphasising the need for unified theories of the distinct safety challenges in the research development and applications of LLMs. We start our discussion with a concise introduction to the workings of LLMs, supported by relevant literature. Then we discuss earlier research that has pointed out the fundamental constraints of generative models, or lack of understanding thereof (e.g., performance and safety trade-offs as LLMs scale in number of parameters). We provide a sufficient coverage of LLM alignment -- delving into various approaches, contending methods and present challenges associated with aligning LLMs with human preferences. By highlighting the gaps in the literature and possible implementation oversights, our aim is to create a comprehensive analysis that provides insights for addressing AI safety in LLMs and encourages the development of aligned and secure models. We conclude our survey by discussing future directions of LLMs for AI safety, offering insights into ongoing research in this critical area.
Read more7/29/2024

0
Towards Trustworthy AI: A Review of Ethical and Robust Large Language Models
Md Meftahul Ferdaus, Mahdi Abdelguerfi, Elias Ioup, Kendall N. Niles, Ken Pathak, Steven Sloan
The rapid progress in Large Language Models (LLMs) could transform many fields, but their fast development creates significant challenges for oversight, ethical creation, and building user trust. This comprehensive review looks at key trust issues in LLMs, such as unintended harms, lack of transparency, vulnerability to attacks, alignment with human values, and environmental impact. Many obstacles can undermine user trust, including societal biases, opaque decision-making, potential for misuse, and the challenges of rapidly evolving technology. Addressing these trust gaps is critical as LLMs become more common in sensitive areas like finance, healthcare, education, and policy. To tackle these issues, we suggest combining ethical oversight, industry accountability, regulation, and public involvement. AI development norms should be reshaped, incentives aligned, and ethics integrated throughout the machine learning process, which requires close collaboration across technology, ethics, law, policy, and other fields. Our review contributes a robust framework to assess trust in LLMs and analyzes the complex trust dynamics in depth. We provide contextualized guidelines and standards for responsibly developing and deploying these powerful AI systems. This review identifies key limitations and challenges in creating trustworthy AI. By addressing these issues, we aim to build a transparent, accountable AI ecosystem that benefits society while minimizing risks. Our findings provide valuable guidance for researchers, policymakers, and industry leaders striving to establish trust in LLMs and ensure they are used responsibly across various applications for the good of society.
Read more7/22/2024
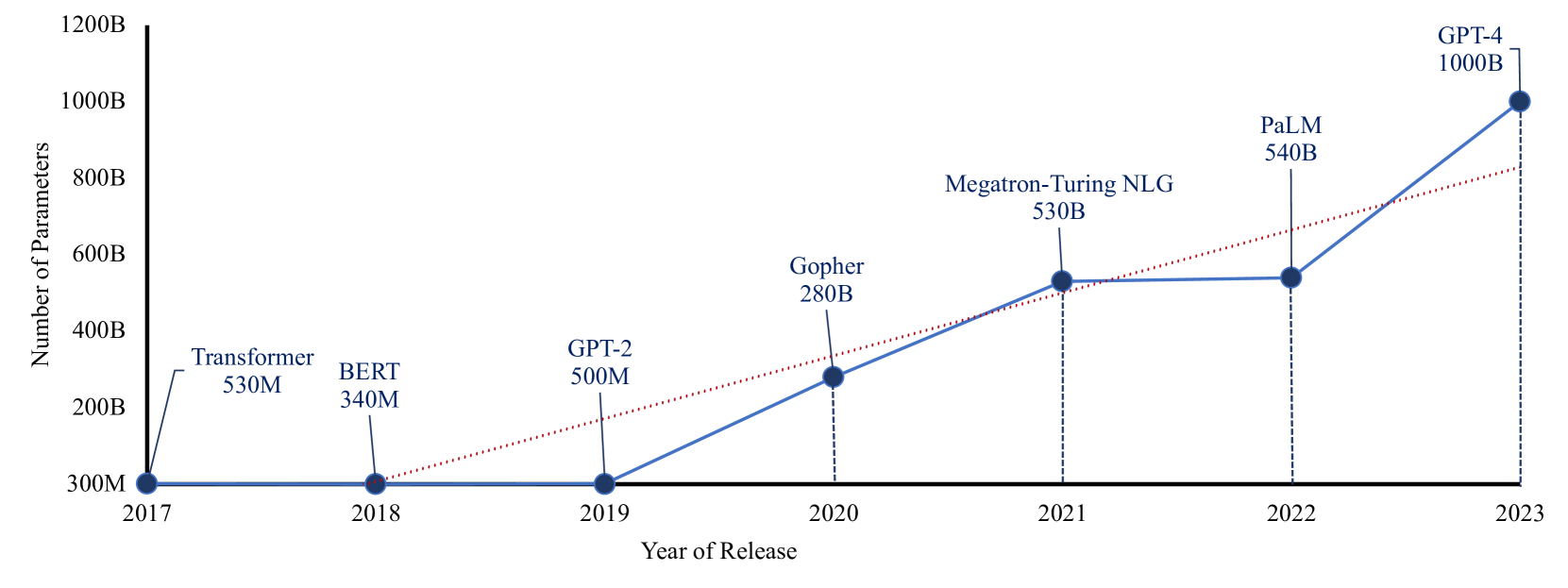
0
Recent Advances in Generative AI and Large Language Models: Current Status, Challenges, and Perspectives
Desta Haileselassie Hagos, Rick Battle, Danda B. Rawat
The emergence of Generative Artificial Intelligence (AI) and Large Language Models (LLMs) has marked a new era of Natural Language Processing (NLP), introducing unprecedented capabilities that are revolutionizing various domains. This paper explores the current state of these cutting-edge technologies, demonstrating their remarkable advancements and wide-ranging applications. Our paper contributes to providing a holistic perspective on the technical foundations, practical applications, and emerging challenges within the evolving landscape of Generative AI and LLMs. We believe that understanding the generative capabilities of AI systems and the specific context of LLMs is crucial for researchers, practitioners, and policymakers to collaboratively shape the responsible and ethical integration of these technologies into various domains. Furthermore, we identify and address main research gaps, providing valuable insights to guide future research endeavors within the AI research community.
Read more8/26/2024