GTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement

0
🔮
Sign in to get full access
Overview
- Proposes a novel approach for 3D mesh reconstruction from multi-view images
- Builds upon large reconstruction models like LRM that use a transformer-based triplane generator and a Neural Radiance Field (NeRF) model
- Introduces several key modifications to enhance 3D reconstruction quality
Plain English Explanation
The researchers have developed a new method for creating 3D mesh models from multiple camera views of an object or scene. Their approach is inspired by large-scale 3D reconstruction models, such as LRM, which use a combination of a transformer-based triplane generator and a Neural Radiance Field (NeRF) model trained on multi-view images.
However, the researchers identified several shortcomings in the original LRM architecture and introduced modifications to improve the quality of the 3D reconstructions. First, they refined the way the multi-view images are represented, leading to more efficient training. Second, they developed a differentiable technique to extract meshes from the NeRF field, allowing for direct supervision of the geometry during training, which improves the overall reconstruction accuracy.
Despite these improvements, the researchers found that their model still struggled to faithfully reconstruct complex textures, such as text and portraits. To address this, they introduced a lightweight per-instance texture refinement procedure that fine-tunes the triplane representation and the NeRF color estimation on the mesh surface using the input multi-view images. This refinement step significantly enhances the visual quality of the final 3D reconstructions.
The researchers' approach enables various downstream applications, including text-to-3D and image-to-3D generation, making it a versatile tool for 3D content creation.
Technical Explanation
The proposed method builds upon the LRM architecture, which uses a transformer-based triplane generator and a NeRF model to reconstruct 3D meshes from multi-view images. The researchers identified several limitations in the original LRM design and introduced the following key modifications:
-
Improved Multi-view Image Representation: The researchers examined the LRM architecture and found ways to enhance the representation of the multi-view images, leading to more computationally efficient training.
-
Differentiable Mesh Extraction: To improve geometry reconstruction and enable supervision at full image resolution, the researchers developed a differentiable technique to extract meshes from the NeRF field and fine-tune the NeRF model through mesh rendering.
-
Texture Refinement: Despite the superior 2D and 3D evaluation metrics achieved by the modified model, the researchers found that it still struggled to faithfully reconstruct complex textures, such as text and portraits. To address this, they introduced a lightweight per-instance texture refinement procedure that fine-tunes the triplane representation and the NeRF color estimation on the mesh surface using the input multi-view images.
The researchers' experiments on the Google Scanned Objects (GSO) dataset demonstrate that their approach achieves state-of-the-art performance, reaching a PSNR of 28.67. The texture refinement step further improves the PSNR to 29.79 and enables the faithful reconstruction of complex textures.
Critical Analysis
The researchers have presented a compelling approach for 3D mesh reconstruction from multi-view images, building upon the strengths of the LRM model while addressing some of its limitations. The modifications to the multi-view image representation and the differentiable mesh extraction process are particularly noteworthy, as they lead to significant improvements in reconstruction quality.
However, the researchers acknowledge that their model still struggles with the reconstruction of complex textures, such as text and portraits. While the introduced texture refinement procedure helps mitigate this issue, it would be interesting to explore further enhancements to the core model architecture to better handle such challenging visual elements.
Additionally, the researchers could potentially investigate the incorporation of G-NeRF or Refined 3D Gaussian Representation techniques to further improve the geometry-aware representation and reconstruction capabilities of their model.
Overall, the proposed approach represents a significant contribution to the field of 3D mesh reconstruction, particularly in its ability to leverage multi-view images to generate high-quality 3D models. The researchers' focus on improving both the 2D and 3D evaluation metrics, as well as enabling downstream applications like text-to-3D and image-to-3D generation, demonstrates the versatility and practical relevance of their work.
Conclusion
The researchers have presented a novel approach for 3D mesh reconstruction from multi-view images that builds upon the strengths of large-scale reconstruction models like LRM while introducing several key modifications to enhance the quality of the reconstructions. By improving the multi-view image representation, developing a differentiable mesh extraction process, and incorporating a lightweight texture refinement procedure, the researchers have achieved state-of-the-art performance on both 2D and 3D evaluation metrics.
This work has the potential to significantly impact various applications, from 3D content creation to virtual reality and beyond, by enabling the generation of high-fidelity 3D models from multi-view images. The researchers' focus on addressing the challenges of complex texture reconstruction further demonstrates their commitment to developing practical and versatile solutions for the 3D reconstruction field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
GTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement
Peiye Zhuang, Songfang Han, Chaoyang Wang, Aliaksandr Siarohin, Jiaxu Zou, Michael Vasilkovsky, Vladislav Shakhrai, Sergey Korolev, Sergey Tulyakov, Hsin-Ying Lee
We propose a novel approach for 3D mesh reconstruction from multi-view images. Our method takes inspiration from large reconstruction models like LRM that use a transformer-based triplane generator and a Neural Radiance Field (NeRF) model trained on multi-view images. However, in our method, we introduce several important modifications that allow us to significantly enhance 3D reconstruction quality. First of all, we examine the original LRM architecture and find several shortcomings. Subsequently, we introduce respective modifications to the LRM architecture, which lead to improved multi-view image representation and more computationally efficient training. Second, in order to improve geometry reconstruction and enable supervision at full image resolution, we extract meshes from the NeRF field in a differentiable manner and fine-tune the NeRF model through mesh rendering. These modifications allow us to achieve state-of-the-art performance on both 2D and 3D evaluation metrics, such as a PSNR of 28.67 on Google Scanned Objects (GSO) dataset. Despite these superior results, our feed-forward model still struggles to reconstruct complex textures, such as text and portraits on assets. To address this, we introduce a lightweight per-instance texture refinement procedure. This procedure fine-tunes the triplane representation and the NeRF color estimation model on the mesh surface using the input multi-view images in just 4 seconds. This refinement improves the PSNR to 29.79 and achieves faithful reconstruction of complex textures, such as text. Additionally, our approach enables various downstream applications, including text- or image-to-3D generation.
Read more6/17/2024
0
GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Chubin Zhang, Hongliang Song, Yi Wei, Yu Chen, Jiwen Lu, Yansong Tang
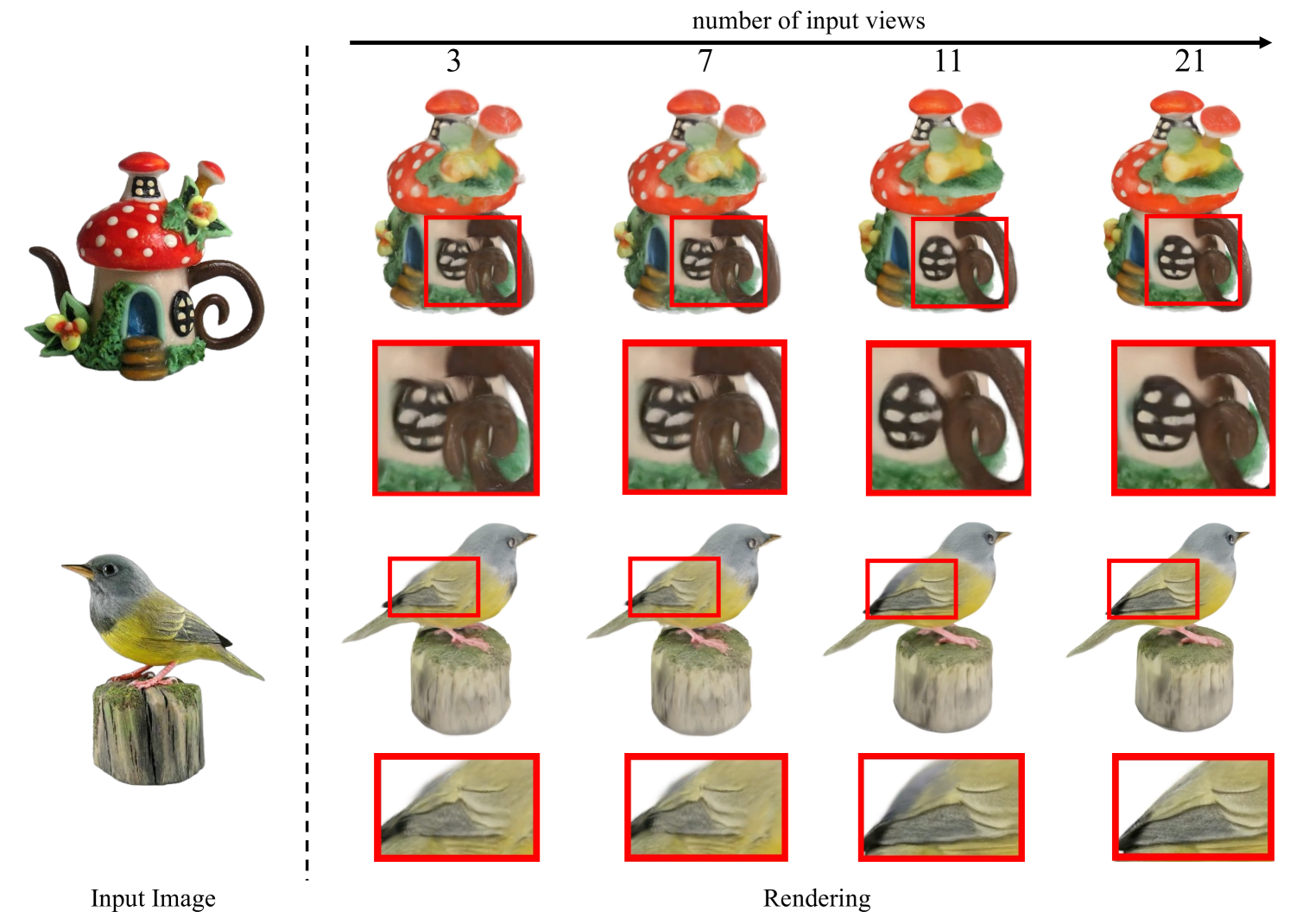
In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
Read more6/24/2024
📈
0
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, Zexiang Xu
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
Read more4/19/2024

0
M-LRM: Multi-view Large Reconstruction Model
Mengfei Li, Xiaoxiao Long, Yixun Liang, Weiyu Li, Yuan Liu, Peng Li, Xiaowei Chi, Xingqun Qi, Wei Xue, Wenhan Luo, Qifeng Liu, Yike Guo
Despite recent advancements in the Large Reconstruction Model (LRM) demonstrating impressive results, when extending its input from single image to multiple images, it exhibits inefficiencies, subpar geometric and texture quality, as well as slower convergence speed than expected. It is attributed to that, LRM formulates 3D reconstruction as a naive images-to-3D translation problem, ignoring the strong 3D coherence among the input images. In this paper, we propose a Multi-view Large Reconstruction Model (M-LRM) designed to efficiently reconstruct high-quality 3D shapes from multi-views in a 3D-aware manner. Specifically, we introduce a multi-view consistent cross-attention scheme to enable M-LRM to accurately query information from the input images. Moreover, we employ the 3D priors of the input multi-view images to initialize the tri-plane tokens. Compared to LRM, the proposed M-LRM can produce a tri-plane NeRF with $128 times 128$ resolution and generate 3D shapes of high fidelity. Experimental studies demonstrate that our model achieves a significant performance gain and faster training convergence than LRM. Project page: https://murphylmf.github.io/M-LRM/
Read more6/13/2024