Guided Masked Self-Distillation Modeling for Distributed Multimedia Sensor Event Analysis

0

Sign in to get full access
Overview
- This paper proposes a guided masked self-distillation modeling approach for analyzing events in distributed multimedia sensor networks.
- The method aims to enable cross-modal action recognition and multi-view action recognition using data from distributed cameras and microphones.
- It introduces a novel masked signal modeling technique to capture temporal and cross-modal relationships in the sensor data.
Plain English Explanation
This research paper presents a new way to analyze events detected by a network of cameras and microphones spread out in different locations. The key idea is to use "masked modeling" - a technique where some parts of the sensor data are hidden, and the model has to learn to fill in the missing information.
This allows the model to capture the relationships between the different sensor signals over time and across the different camera and microphone locations. The goal is to enable two important capabilities: cross-modal action recognition (identifying actions based on both video and audio data) and multi-view action recognition (identifying actions from multiple camera perspectives).
The paper claims this guided masked self-distillation approach can improve the performance of these tasks compared to previous methods. The motivation is to enable more robust and accurate event detection and analysis in distributed sensor networks, which have many applications like security monitoring, smart cities, and autonomous systems.
Technical Explanation
The paper introduces a new guided masked self-distillation modeling approach for distributed multimedia sensor event analysis. The key elements are:
-
Masked Signal Modeling: The model is trained to predict missing parts of the input sensor data (e.g. video frames or audio segments) by learning the temporal and cross-modal relationships in the complete data. This allows the model to capture rich representations.
-
Cross-Modal Guidance: The model uses a cross-modal guidance mechanism, where the predictions for one modality (e.g. audio) are used to guide the predictions for the other modality (e.g. video). This improves the model's ability to learn the connections between the different sensor signals.
-
Self-Distillation: The model is trained using a self-distillation approach, where the model's own predictions are used as targets for further training. This helps the model refine its internal representations and improve performance.
The proposed approach is evaluated on benchmark datasets for cross-modal action recognition and multi-view action recognition tasks. The results show improvements over previous state-of-the-art methods, demonstrating the effectiveness of the guided masked self-distillation modeling technique for distributed multimedia sensor event analysis.
Critical Analysis
The paper provides a novel and well-designed modeling approach for distributed sensor event analysis. The use of masked signal modeling to capture temporal and cross-modal relationships is a promising technique, and the incorporation of cross-modal guidance and self-distillation further enhances the model's learning capabilities.
However, the paper does not extensively discuss the potential limitations or caveats of the proposed method. For example, it could be valuable to understand how the approach might perform in real-world scenarios with noisy, incomplete, or heterogeneous sensor data, or how it scales to larger and more complex sensor networks.
Additionally, the paper could have explored the trade-offs between model complexity, inference speed, and performance, as these factors can be crucial in practical applications of distributed sensor systems. Further research in these areas could help strengthen the contributions of this work and provide a more comprehensive understanding of its strengths and weaknesses.
Conclusion
This research paper presents a novel guided masked self-distillation modeling approach for analyzing events in distributed multimedia sensor networks. The key innovations include masked signal modeling to capture temporal and cross-modal relationships, cross-modal guidance to improve learning, and self-distillation to refine the model's internal representations.
The proposed method demonstrates improved performance on benchmark tasks for cross-modal action recognition and multi-view action recognition, highlighting its potential for enabling more robust and accurate event detection and analysis in distributed sensor systems. While the paper provides a solid technical foundation, further exploration of real-world applications, scalability, and model efficiency could help strengthen the impact of this work and guide future research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Guided Masked Self-Distillation Modeling for Distributed Multimedia Sensor Event Analysis
Masahiro Yasuda, Noboru Harada, Yasunori Ohishi, Shoichiro Saito, Akira Nakayama, Nobutaka Ono
Observations with distributed sensors are essential in analyzing a series of human and machine activities (referred to as 'events' in this paper) in complex and extensive real-world environments. This is because the information obtained from a single sensor is often missing or fragmented in such an environment; observations from multiple locations and modalities should be integrated to analyze events comprehensively. However, a learning method has yet to be established to extract joint representations that effectively combine such distributed observations. Therefore, we propose Guided Masked sELf-Distillation modeling (Guided-MELD) for inter-sensor relationship modeling. The basic idea of Guided-MELD is to learn to supplement the information from the masked sensor with information from other sensors needed to detect the event. Guided-MELD is expected to enable the system to effectively distill the fragmented or redundant target event information obtained by the sensors without being overly dependent on any specific sensors. To validate the effectiveness of the proposed method in novel tasks of distributed multimedia sensor event analysis, we recorded two new datasets that fit the problem setting: MM-Store and MM-Office. These datasets consist of human activities in a convenience store and an office, recorded using distributed cameras and microphones. Experimental results on these datasets show that the proposed Guided-MELD improves event tagging and detection performance and outperforms conventional inter-sensor relationship modeling methods. Furthermore, the proposed method performed robustly even when sensors were reduced.
Read more4/15/2024

0
Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection
Jinbo Hu, Yin Cao, Ming Wu, Qiuqiang Kong, Feiran Yang, Mark D. Plumbley, Jun Yang
Environment shifts and conflicts present significant challenges for learning-based sound event localization and detection (SELD) methods. SELD systems, when trained in particular acoustic settings, often show restricted generalization capabilities for diverse acoustic environments. Furthermore, obtaining annotated samples for spatial sound events is notably costly. Deploying a SELD system in a new environment requires extensive time for re-training and fine-tuning. To overcome these challenges, we propose environment-adaptive Meta-SELD, designed for efficient adaptation to new environments using minimal data. Our method specifically utilizes computationally synthesized spatial data and employs Model-Agnostic Meta-Learning (MAML) on a pre-trained, environment-independent model. The method then utilizes fast adaptation to unseen real-world environments using limited samples from the respective environments. Inspired by the Learning-to-Forget approach, we introduce the concept of selective memory as a strategy for resolving conflicts across environments. This approach involves selectively memorizing target-environment-relevant information and adapting to the new environments through the selective attenuation of model parameters. In addition, we introduce environment representations to characterize different acoustic settings, enhancing the adaptability of our attenuation approach to various environments. We evaluate our proposed method on the development set of the Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23) dataset and computationally synthesized scenes. Experimental results demonstrate the superior performance of the proposed method compared to conventional supervised learning methods, particularly in localization.
Read more8/23/2024
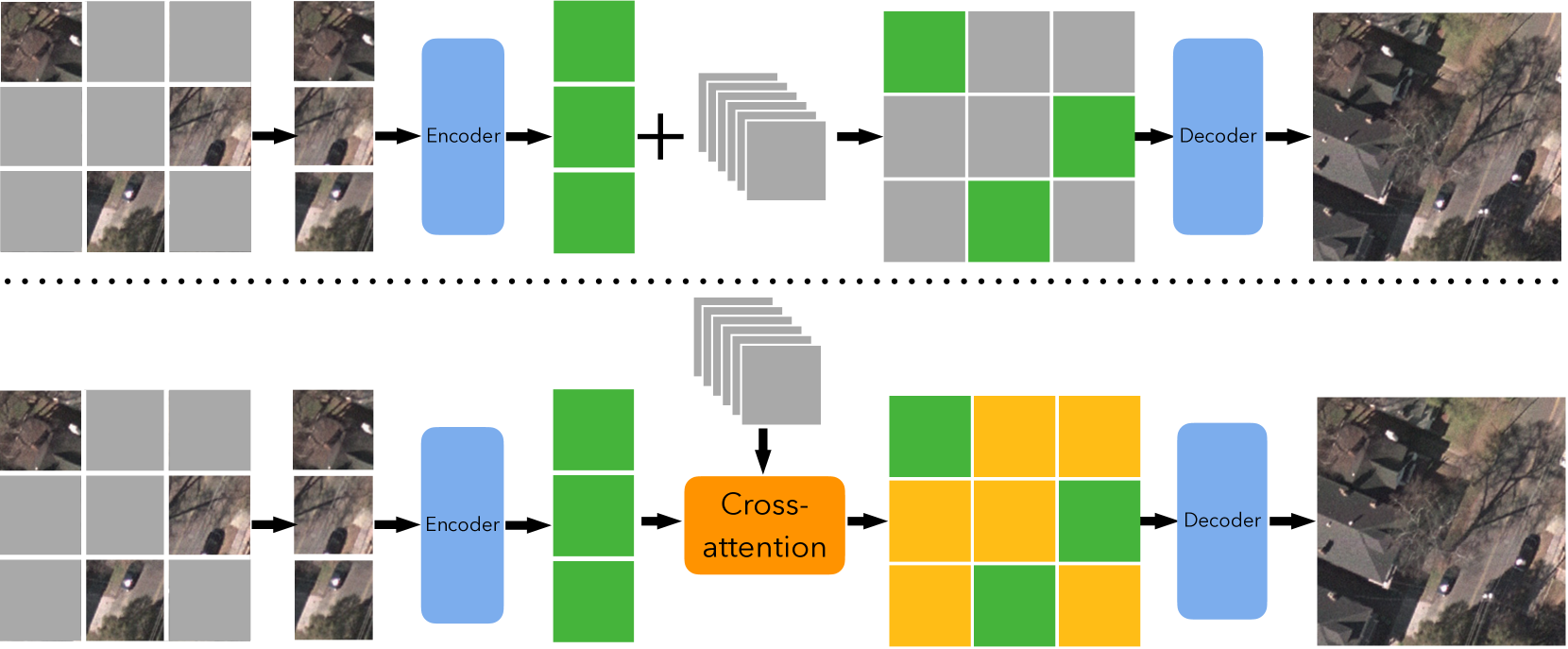
0
Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Minh-Duc Vu, Zuheng Ming, Fangchen Feng, Bissmella Bahaduri, Anissa Mokraoui
Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Read more9/16/2024

0
SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation
Da Mu, Zhicheng Zhang, Haobo Yue, Zehao Wang, Jin Tang, Jianqin Yin
In the Sound Event Localization and Detection (SELD) task, Transformer-based models have demonstrated impressive capabilities. However, the quadratic complexity of the Transformer's self-attention mechanism results in computational inefficiencies. In this paper, we propose a network architecture for SELD called SELD-Mamba, which utilizes Mamba, a selective state-space model. We adopt the Event-Independent Network V2 (EINV2) as the foundational framework and replace its Conformer blocks with bidirectional Mamba blocks to capture a broader range of contextual information while maintaining computational efficiency. Additionally, we implement a two-stage training method, with the first stage focusing on Sound Event Detection (SED) and Direction of Arrival (DoA) estimation losses, and the second stage reintroducing the Source Distance Estimation (SDE) loss. Our experimental results on the 2024 DCASE Challenge Task3 dataset demonstrate the effectiveness of the selective state-space model in SELD and highlight the benefits of the two-stage training approach in enhancing SELD performance.
Read more8/12/2024