GuideWalk -- Heterogeneous Data Fusion for Enhanced Learning -- A Multiclass Document Classification Case

0
Sign in to get full access
Overview
- This paper explores methods for enhancing embedding performance using large language models.
- It proposes a clustering-based image-text graph matching approach for domain-specific applications.
- The paper also investigates description-based text similarity and knowledge graph completion using structural and textual embeddings.
- Additionally, the research discusses scaling up multi-domain semantic segmentation for sentences.
Plain English Explanation
The paper examines ways to improve the performance of embedding models, which are used to represent text, images, and other data in a numerical format that can be understood by machine learning algorithms. The researchers explore several techniques to enhance these embeddings:
-
Clustering-based image-text graph matching: This approach aims to better match images and corresponding text in specific domains, like healthcare or finance.
-
Description-based text similarity: The paper investigates methods to determine how similar two pieces of text are based on their descriptions or explanations, rather than just their surface-level content.
-
Knowledge graph completion using structural and textual embeddings: The researchers use a combination of the inherent structure of knowledge graphs and the textual information within them to fill in missing information in these knowledge graphs.
-
Scaling up multi-domain semantic segmentation for sentences: This work looks at ways to apply semantic segmentation, which identifies the meaning of different parts of a sentence, to a wide range of domains, rather than just a few.
By exploring these diverse approaches, the paper aims to enhance the performance and capabilities of embedding models, which are foundational to many modern AI and machine learning applications.
Technical Explanation
The paper presents several novel techniques for improving embedding performance:
-
Clustering-based image-text graph matching: The researchers propose a method that uses clustering to better align images and their corresponding textual descriptions in domain-specific applications. This is achieved by constructing a graph that captures the relationships between images and text, and then optimizing the matching between them.
-
Description-based text similarity: The paper introduces a new approach to determine text similarity based on the descriptions or explanations of the text, rather than just the surface-level content. This can provide a more nuanced understanding of the semantic relationships between texts.
-
Knowledge graph completion using structural and textual embeddings: The researchers leverage both the inherent structure of knowledge graphs and the textual information within them to fill in missing information in these knowledge graphs. This combines structural and textual embedding techniques to enhance the overall performance.
-
Scaling up multi-domain semantic segmentation for sentences: The paper explores methods to apply semantic segmentation, which identifies the meaning of different parts of a sentence, to a wide range of domains, rather than just a few. This allows for more robust and versatile sentence understanding capabilities.
Through these innovative approaches, the paper aims to push the boundaries of embedding performance and enable more advanced applications of these fundamental AI and machine learning techniques.
Critical Analysis
The paper presents several promising techniques for enhancing embedding performance, but it also acknowledges some potential limitations and areas for further research:
-
The clustering-based image-text graph matching approach may face challenges in scaling to large-scale datasets or handling complex, diverse data sources.
-
The description-based text similarity method relies on the availability of high-quality textual descriptions, which may not always be present in real-world applications.
-
The knowledge graph completion technique could be sensitive to the quality and coverage of the initial knowledge graph, and may require careful curation and maintenance of the graph structure.
-
The scaling up multi-domain semantic segmentation approach may face challenges in ensuring consistent and robust performance across a wide range of domains, as the linguistic and contextual characteristics of each domain can vary significantly.
Overall, the paper presents a solid set of techniques for enhancing embedding performance, but further research and validation may be needed to address these potential limitations and ensure the scalability and real-world applicability of these methods.
Conclusion
This paper explores several innovative approaches for improving the performance of embedding models, which are fundamental to many AI and machine learning applications. By leveraging techniques like clustering-based image-text graph matching, description-based text similarity, knowledge graph completion, and scaled-up multi-domain semantic segmentation, the researchers aim to push the boundaries of what is possible with embeddings.
While the paper acknowledges some potential limitations and areas for further research, the proposed methods represent significant advancements in the field of embedding performance enhancement. These techniques have the potential to enable more accurate, robust, and versatile applications across a wide range of domains, from healthcare and finance to natural language processing and knowledge representation.
As the demand for high-performing AI systems continues to grow, research like this will be crucial in driving the development of more powerful and capable embedding models, ultimately leading to more intelligent and effective solutions for real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GuideWalk -- Heterogeneous Data Fusion for Enhanced Learning -- A Multiclass Document Classification Case
Sarmad N. Mohammed, Semra Gunduc{c}
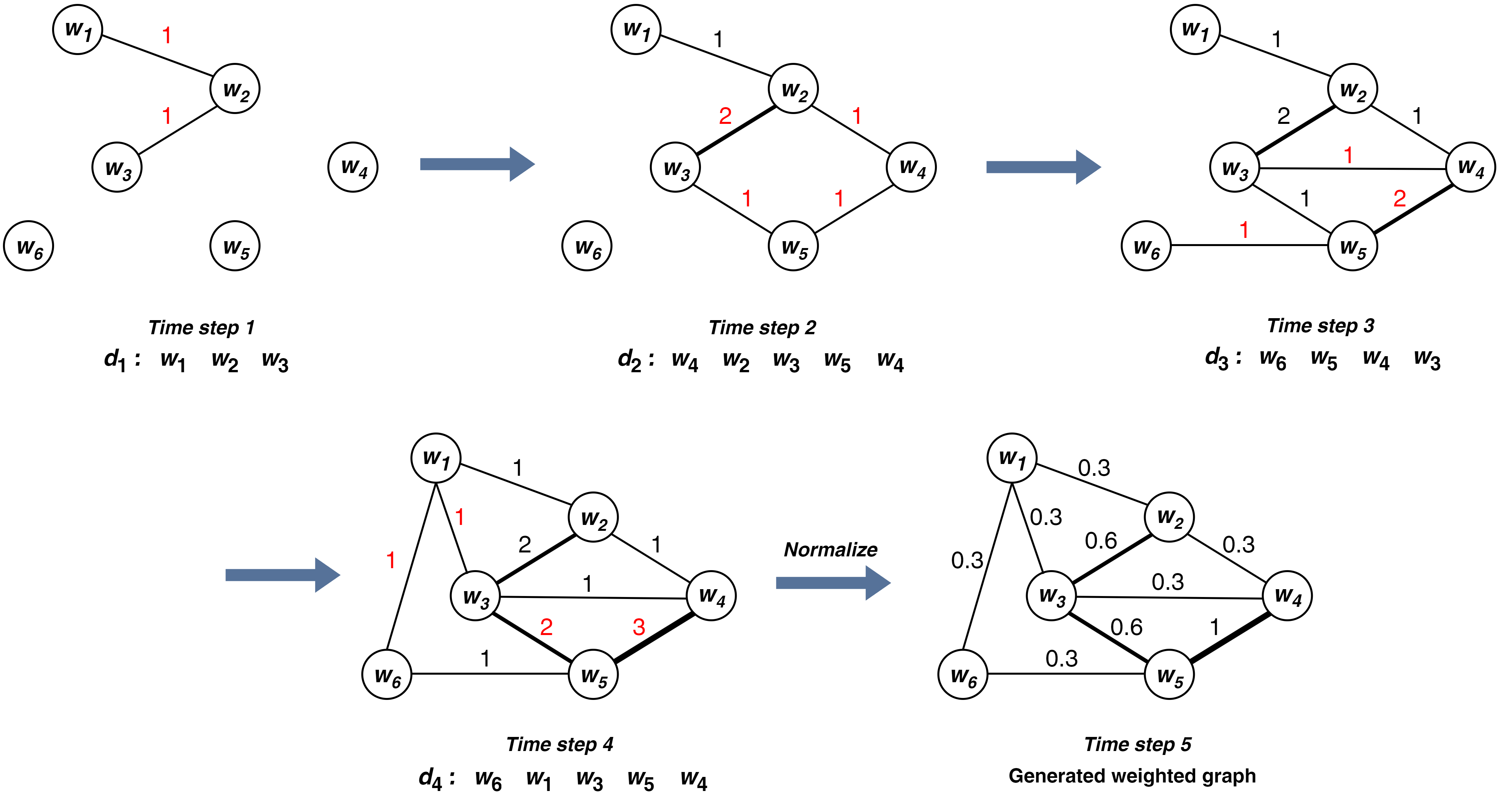
One of the prime problems of computer science and machine learning is to extract information efficiently from large-scale, heterogeneous data. Text data, with its syntax, semantics, and even hidden information content, possesses an exceptional place among the data types in concern. The processing of the text data requires embedding, a method of translating the content of the text to numeric vectors. A correct embedding algorithm is the starting point for obtaining the full information content of the text data. In this work, a new text embedding approach, namely the Guided Transition Probability Matrix (GTPM) model is proposed. The model uses the graph structure of sentences to capture different types of information from text data, such as syntactic, semantic, and hidden content. Using random walks on a weighted word graph, GTPM calculates transition probabilities to derive text embedding vectors. The proposed method is tested with real-world data sets and eight well-known and successful embedding algorithms. GTPM shows significantly better classification performance for binary and multi-class datasets than well-known algorithms. Additionally, the proposed method demonstrates superior robustness, maintaining performance with limited (only $10%$) training data, showing an $8%$ decline compared to $15-20%$ for baseline methods.
Read more9/10/2024

0
Optimal synthesis embeddings
Roberto Santana, Mauricio Romero Sicre
In this paper we introduce a word embedding composition method based on the intuitive idea that a fair embedding representation for a given set of words should satisfy that the new vector will be at the same distance of the vector representation of each of its constituents, and this distance should be minimized. The embedding composition method can work with static and contextualized word representations, it can be applied to create representations of sentences and learn also representations of sets of words that are not necessarily organized as a sequence. We theoretically characterize the conditions for the existence of this type of representation and derive the solution. We evaluate the method in data augmentation and sentence classification tasks, investigating several design choices of embeddings and composition methods. We show that our approach excels in solving probing tasks designed to capture simple linguistic features of sentences.
Read more6/18/2024
👁️
0
A Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
Elika Bozorgi, Sakher Khalil Alqaiidi, Afsaneh Shams, Hamid Reza Arabnia, Krzysztof Kochut
Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
Read more6/12/2024

0
AutoML-guided Fusion of Entity and LLM-based representations
Boshko Koloski, Senja Pollak, Roberto Navigli, Blav{z} v{S}krlj
Large semantic knowledge bases are grounded in factual knowledge. However, recent approaches to dense text representations (embeddings) do not efficiently exploit these resources. Dense and robust representations of documents are essential for effectively solving downstream classification and retrieval tasks. This work demonstrates that injecting embedded information from knowledge bases can augment the performance of contemporary Large Language Model (LLM)-based representations for the task of text classification. Further, by considering automated machine learning (AutoML) with the fused representation space, we demonstrate it is possible to improve classification accuracy even if we use low-dimensional projections of the original representation space obtained via efficient matrix factorization. This result shows that significantly faster classifiers can be achieved with minimal or no loss in predictive performance, as demonstrated using five strong LLM baselines on six diverse real-life datasets.
Read more8/20/2024