Hallucination in Perceptual Metric-Driven Speech Enhancement Networks

0
Sign in to get full access
Overview
- This paper investigates the issue of "hallucination" in perceptual metric-driven speech enhancement networks.
- Hallucination refers to the phenomenon where these networks generate artificial audio content that is not present in the original signal, leading to perceptual distortions.
- The research was supported by the Centre for Doctoral Training in Speech and Language Technologies (SLT) and their Applications, as well as TOSHIBA Cambridge Research Laboratory.
Plain English Explanation
Speech enhancement networks are AI systems designed to improve the quality of audio signals, for example by reducing noise or improving clarity. However, these networks can sometimes generate artificial sounds that were not present in the original audio. This is known as "hallucination" and can lead to distortions that make the enhanced audio sound unnatural or unreliable.
The researchers in this paper set out to better understand and mitigate the problem of hallucination in these speech enhancement networks. By examining how the networks operate and the factors that contribute to hallucination, they hope to develop techniques to reduce these unwanted artifacts and produce more accurate and reliable audio enhancement.
Technical Explanation
The paper investigates the problem of hallucination in perceptual metric-driven speech enhancement networks. These networks use machine learning models to analyze the characteristics of an audio signal and apply processing to improve its quality, based on perceptual metrics that aim to match human audio perception.
However, the researchers found that these networks can sometimes introduce artificial audio content, known as "hallucinations", that was not present in the original signal. This can lead to perceptual distortions and reduce the reliability of the enhanced output.
To study this phenomenon, the researchers designed experiments to measure the prevalence of hallucination in different speech enhancement network architectures and training regimes. They also analyzed the factors that contribute to hallucination, such as the choice of perceptual metrics and the network's sensitivity to certain audio features.
Based on their findings, the researchers propose potential mitigation strategies, such as incorporating additional constraints or modules into the network design to better control and detect hallucinations. They also discuss the implications of this issue for the development of robust and trustworthy speech enhancement systems.
Critical Analysis
The paper provides a valuable contribution to the field of speech enhancement by shedding light on the often overlooked issue of hallucination. The researchers' experimental approach and analysis of the underlying factors contributing to this problem are thorough and well-designed.
However, the paper does not delve into the potential causes of hallucination at a deeper level. While the researchers hypothesize that factors such as perceptual metrics and network sensitivity may play a role, a more comprehensive exploration of the fundamental mechanisms driving hallucination could further strengthen the understanding of this phenomenon.
Additionally, the proposed mitigation strategies, while promising, would benefit from more detailed exploration and validation. The paper could have provided a more comprehensive evaluation of these approaches, including their effectiveness, limitations, and potential trade-offs.
Conclusion
This paper presents an in-depth investigation into the problem of hallucination in perceptual metric-driven speech enhancement networks. By examining the prevalence and contributing factors of this issue, the researchers have taken an important step towards understanding and addressing a critical challenge in the development of reliable and trustworthy audio enhancement systems.
The insights and proposed mitigation strategies outlined in this work provide a valuable foundation for future research and development in this area. Ultimately, the goal of this research is to enable the creation of speech enhancement networks that can consistently produce high-quality, artifact-free audio, ensuring their reliable deployment in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hallucination in Perceptual Metric-Driven Speech Enhancement Networks
George Close, Thomas Hain, Stefan Goetze
Within the area of speech enhancement, there is an ongoing interest in the creation of neural systems which explicitly aim to improve the perceptual quality of the processed audio. In concert with this is the topic of non-intrusive (i.e. without clean reference) speech quality prediction, for which neural networks are trained to predict human-assigned quality labels directly from distorted audio. When combined, these areas allow for the creation of powerful new speech enhancement systems which can leverage large real-world datasets of distorted audio, by taking inference of a pre-trained speech quality predictor as the sole loss function of the speech enhancement system. This paper aims to identify a potential pitfall with this approach, namely hallucinations which are introduced by the enhancement system `tricking' the speech quality predictor.
Read more5/27/2024
0
Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Robert Sutherland, George Close, Thomas Hain, Stefan Goetze, Jon Barker
Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Read more7/19/2024

0
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Read more7/23/2024
0
Enhancing Hallucination Detection through Perturbation-Based Synthetic Data Generation in System Responses
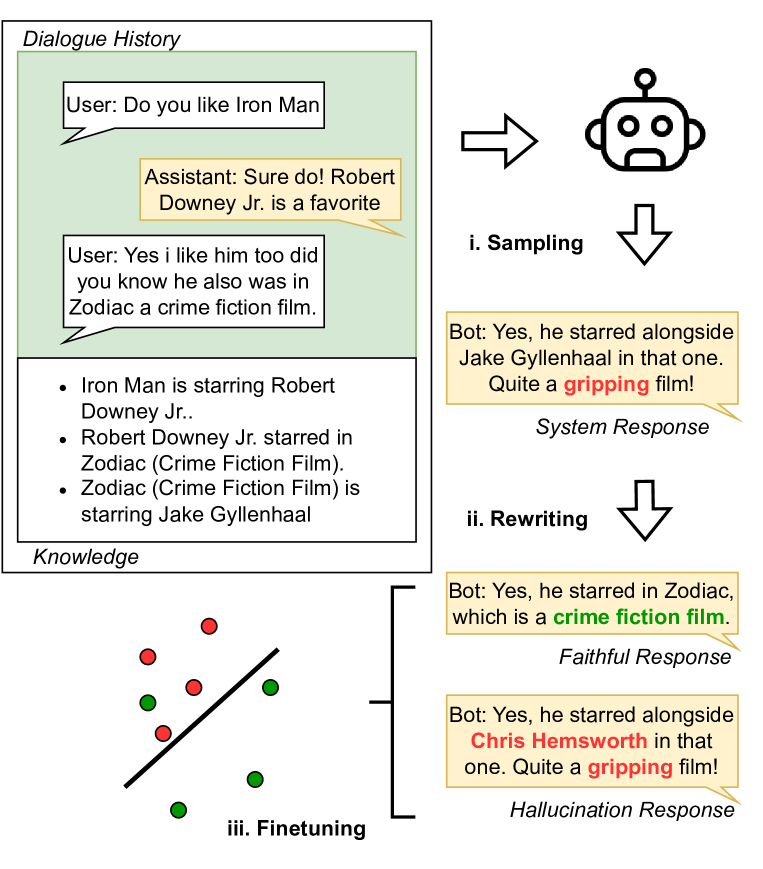
Dongxu Zhang, Varun Gangal, Barrett Martin Lattimer, Yi Yang
Detecting hallucinations in large language model (LLM) outputs is pivotal, yet traditional fine-tuning for this classification task is impeded by the expensive and quickly outdated annotation process, especially across numerous vertical domains and in the face of rapid LLM advancements. In this study, we introduce an approach that automatically generates both faithful and hallucinated outputs by rewriting system responses. Experimental findings demonstrate that a T5-base model, fine-tuned on our generated dataset, surpasses state-of-the-art zero-shot detectors and existing synthetic generation methods in both accuracy and latency, indicating efficacy of our approach.
Read more7/9/2024