Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned

0

Sign in to get full access
Overview
- This paper discusses the development of a reliable, general-purpose hallucination detection and mitigation service.
- Hallucination refers to the generation of false or nonsensical content by language models.
- The paper shares insights and lessons learned from this development process.
Plain English Explanation
The paper describes the creation of a system that can detect when language models are generating false or nonsensical information, known as "hallucination." Hallucination is a common problem with large language models that can produce plausible-sounding but completely made-up responses.
The researchers developed a service that can reliably identify when a model is hallucinating, and potentially mitigate or correct those errors. This is an important capability for applications that rely on language models, such as question answering systems or multimodal AI, to ensure the information being provided is accurate and trustworthy.
The paper shares the key insights and lessons the researchers learned through the process of developing this hallucination detection and mitigation service. This includes details about their approach, challenges they faced, and recommendations for others working on similar problems.
Technical Explanation
The paper describes the researchers' efforts to develop a reliable, general-purpose service for detecting and mitigating hallucination in language models. They approached this challenge through several key steps:
-
Dataset Curation: The researchers curated a diverse dataset of human-written and model-generated text, including examples of hallucination, to use for training and evaluating their hallucination detection system.
-
Model Architecture: They experimented with different model architectures and techniques, such as using internal model representations and task-specific finetuning, to improve the reliability of hallucination detection.
-
Mitigation Strategies: In addition to detection, the researchers explored mitigation approaches to correct or prevent hallucination, including methods to unify detection across modalities.
-
Evaluation and Insights: Through extensive testing and analysis, the researchers gained insights into the strengths, limitations, and best practices for deploying a reliable hallucination detection and mitigation service.
Critical Analysis
The paper provides a comprehensive look at the challenges and considerations involved in developing a robust hallucination detection and mitigation system. The researchers acknowledge that while their service demonstrates promising results, there are still some limitations and areas for further research:
- The hallucination detection model may not generalize well to all types of language models and domains, requiring additional training and fine-tuning.
- The mitigation strategies, while effective, may not be suitable for all use cases and could introduce additional complexities or trade-offs.
- Evaluating the reliability and trustworthiness of language model outputs remains an ongoing challenge, and the researchers suggest the need for continued research in this area.
Overall, the paper offers valuable insights and lessons learned that could benefit others working on similar problems in the field of language model reliability and safety.
Conclusion
This paper presents the development of a reliable, general-purpose hallucination detection and mitigation service, which is a crucial capability for ensuring the trustworthiness of language models in various applications. The researchers share their approach, insights, and lessons learned through this process, providing a roadmap for others working on similar challenges. The work highlights the importance of addressing hallucination and other reliability issues in language models to support the safe and responsible deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Read more7/23/2024

0
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Weihang Su, Changyue Wang, Qingyao Ai, Yiran HU, Zhijing Wu, Yujia Zhou, Yiqun Liu
Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
Read more6/11/2024

0
Cost-Effective Hallucination Detection for LLMs
Simon Valentin, Jinmiao Fu, Gianluca Detommaso, Shaoyuan Xu, Giovanni Zappella, Bryan Wang
Large language models (LLMs) can be prone to hallucinations - generating unreliable outputs that are unfaithful to their inputs, external facts or internally inconsistent. In this work, we address several challenges for post-hoc hallucination detection in production settings. Our pipeline for hallucination detection entails: first, producing a confidence score representing the likelihood that a generated answer is a hallucination; second, calibrating the score conditional on attributes of the inputs and candidate response; finally, performing detection by thresholding the calibrated score. We benchmark a variety of state-of-the-art scoring methods on different datasets, encompassing question answering, fact checking, and summarization tasks. We employ diverse LLMs to ensure a comprehensive assessment of performance. We show that calibrating individual scoring methods is critical for ensuring risk-aware downstream decision making. Based on findings that no individual score performs best in all situations, we propose a multi-scoring framework, which combines different scores and achieves top performance across all datasets. We further introduce cost-effective multi-scoring, which can match or even outperform more expensive detection methods, while significantly reducing computational overhead.
Read more8/12/2024
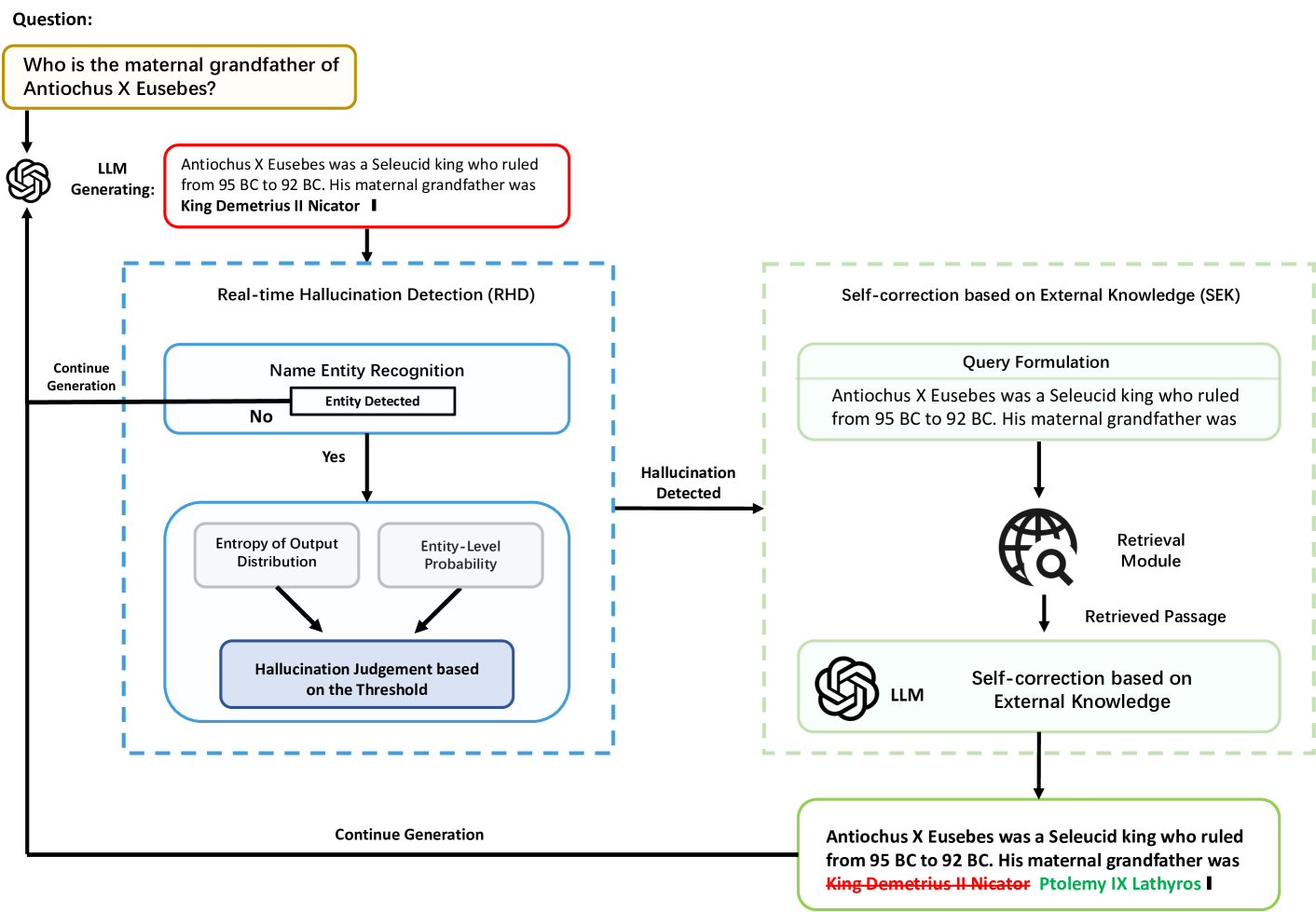
0
Mitigating Entity-Level Hallucination in Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, Yiqun Liu
The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Read more7/23/2024