Using Large Language Models to Assist Video Content Analysis: An Exploratory Study of Short Videos on Depression

0
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) to assist in the analysis of short user-generated videos on the topic of depression.
- The researchers investigate whether LLMs can be effectively leveraged to extract insights and annotations from video content, which could aid in understanding mental health-related user-generated content.
- The study focuses on a dataset of short videos on depression, examining how LLMs can be used to analyze the textual and visual elements of these videos.
Plain English Explanation
Large language models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. In this study, the researchers investigated whether LLMs could be used to help analyze the content of short videos related to depression.
The researchers collected a dataset of user-generated videos about depression, which are often shared online by people sharing their personal experiences or seeking support. They then explored how LLMs could be used to extract meaningful information and annotations from the textual and visual elements of these videos.
The goal was to see if LLMs could assist in understanding the mental health-related content in these user-generated videos, which could potentially help researchers, healthcare providers, or online communities better support people dealing with depression. By leveraging the capabilities of LLMs, the researchers aimed to gain insights that might be difficult to obtain through manual analysis alone.
Technical Explanation
The researchers collected a dataset of short user-generated videos on the topic of depression, which were sourced from online platforms. They then investigated the use of large language models (LLMs) to analyze the textual and visual content of these videos.
The study examined how LLMs could be employed to extract relevant information and annotations from the video content, such as identifying key topics, sentiment, and themes related to depression. The researchers explored various approaches for integrating LLM-based analysis with the video data, including techniques described in MovieLLM and VideoLLM.
Additionally, the researchers explored the potential of LLMs to assist in the annotation process, building on insights from studies such as Can Large Language Models Aid in Annotating Speech? and The Effectiveness of Large Language Models as Annotators: A Comparative Overview. This included investigating how LLMs could potentially streamline the annotation of video content, potentially complementing or enhancing manual annotation efforts.
The findings of this study contribute to the broader research on LongVLM, exploring the role of large language models in video understanding and content analysis, particularly in the context of mental health-related user-generated content.
Critical Analysis
The paper provides a valuable exploration of using large language models to assist in the analysis of user-generated video content related to mental health topics, specifically depression. The researchers acknowledge the challenges in manually analyzing such content and highlight the potential of LLMs to augment and enhance the understanding of these videos.
While the study presents promising results, the authors also note several caveats and limitations. For instance, the dataset used in the study is relatively small, and the researchers suggest that larger and more diverse datasets may be needed to fully evaluate the capabilities of LLMs in this context.
Additionally, the paper does not delve deeply into the ethical considerations and potential pitfalls of using LLMs for mental health-related content analysis. Issues around privacy, informed consent, and the potential for misuse or misinterpretation of the findings should be further explored in future research.
The researchers also acknowledge the need for more robust evaluation methods to assess the accuracy and reliability of LLM-based video analysis, particularly in sensitive domains like mental health. Incorporating feedback from domain experts, such as mental health professionals, and conducting user studies could help validate the utility and limitations of the proposed approaches.
Conclusion
This study presents an exploratory investigation into the use of large language models (LLMs) to assist in the analysis of user-generated videos related to depression. The researchers demonstrate the potential of LLMs to extract relevant information and annotations from the textual and visual elements of these videos, which could aid in understanding mental health-related content shared online.
The findings of this study contribute to the growing body of research on leveraging LLMs for video understanding and content analysis, particularly in the context of sensitive topics like mental health. While the results are promising, the authors highlight the need for further research to address the limitations and ethical considerations of using such technologies in this domain.
Ultimately, this work suggests that the integration of LLMs and video analysis could lead to more effective ways of supporting and understanding mental health-related user-generated content, with the potential to benefit both individuals and the broader mental health community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Using Large Language Models to Assist Video Content Analysis: An Exploratory Study of Short Videos on Depression
Jiaying Lizzy Liu, Yunlong Wang, Yao Lyu, Yiheng Su, Shuo Niu, Xuhai Orson Xu, Yan Zhang
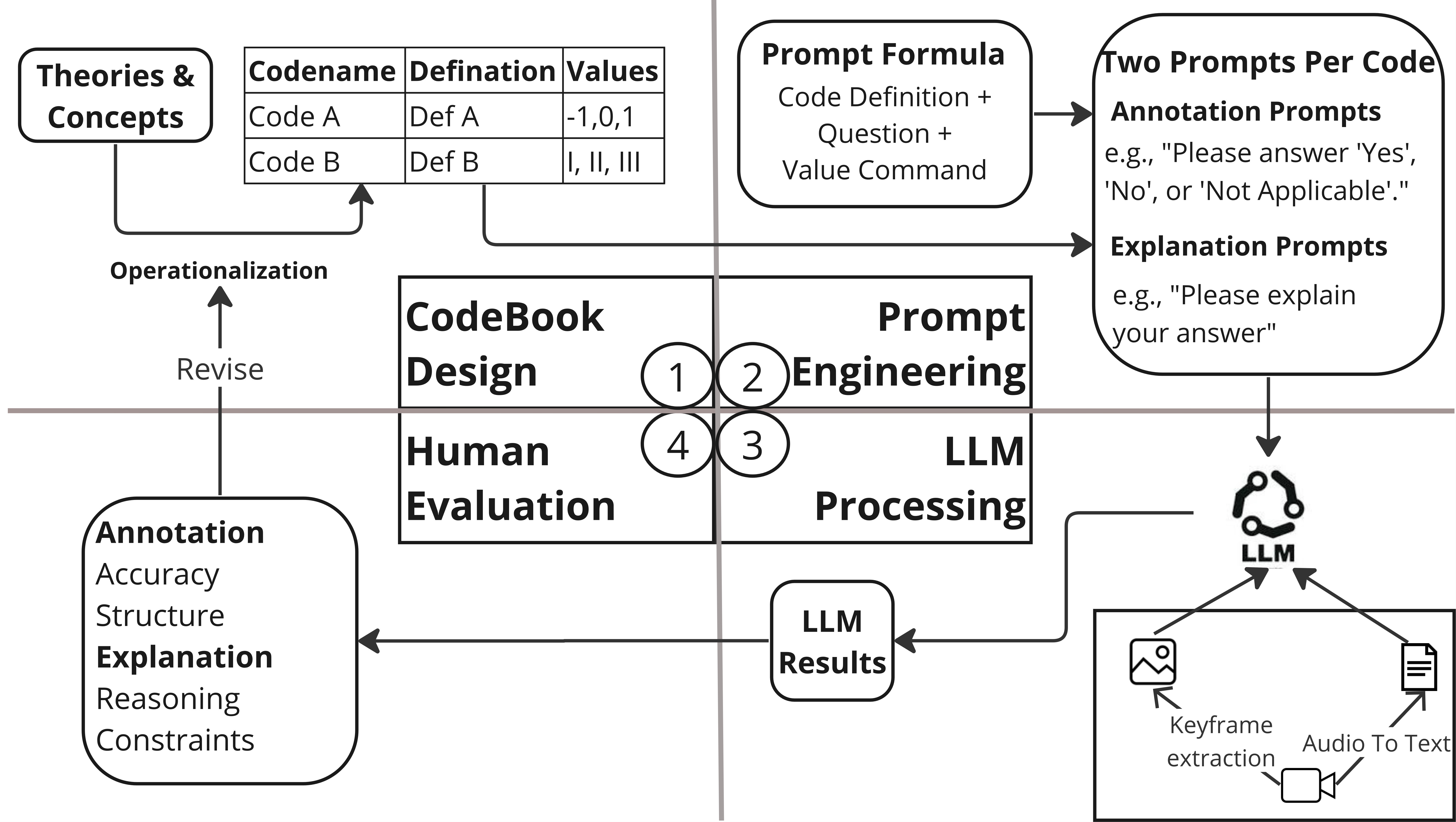
Despite the growing interest in leveraging Large Language Models (LLMs) for content analysis, current studies have primarily focused on text-based content. In the present work, we explored the potential of LLMs in assisting video content analysis by conducting a case study that followed a new workflow of LLM-assisted multimodal content analysis. The workflow encompasses codebook design, prompt engineering, LLM processing, and human evaluation. We strategically crafted annotation prompts to get LLM Annotations in structured form and explanation prompts to generate LLM Explanations for a better understanding of LLM reasoning and transparency. To test LLM's video annotation capabilities, we analyzed 203 keyframes extracted from 25 YouTube short videos about depression. We compared the LLM Annotations with those of two human coders and found that LLM has higher accuracy in object and activity Annotations than emotion and genre Annotations. Moreover, we identified the potential and limitations of LLM's capabilities in annotating videos. Based on the findings, we explore opportunities and challenges for future research and improvements to the workflow. We also discuss ethical concerns surrounding future studies based on LLM-assisted video analysis.
Read more7/31/2024

0
Video Understanding with Large Language Models: A Survey
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, Ali Vosoughi, Chao Huang, Zeliang Zhang, Pinxin Liu, Mingqian Feng, Feng Zheng, Jianguo Zhang, Ping Luo, Jiebo Luo, Chenliang Xu
With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of large language models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of recent advancements in video understanding that harness the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended multi-granularity (general, temporal, and spatiotemporal) reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into three main types: Video Analyzer x LLM, Video Embedder x LLM, and (Analyzer + Embedder) x LLM. Furthermore, we identify five sub-types based on the functions of LLMs in Vid-LLMs: LLM as Summarizer, LLM as Manager, LLM as Text Decoder, LLM as Regressor, and LLM as Hidden Layer. Furthermore, this survey presents a comprehensive study of the tasks, datasets, benchmarks, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding.
Read more7/25/2024
0
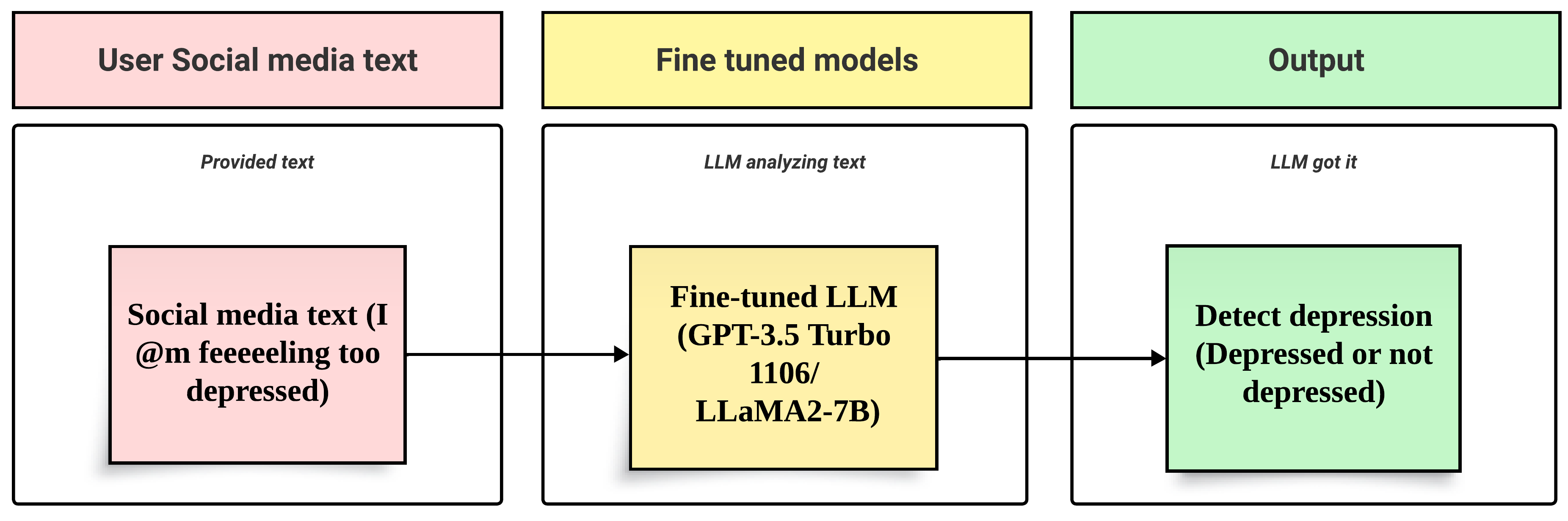
Advancing Depression Detection on Social Media Platforms Through Fine-Tuned Large Language Models
Shahid Munir Shah, Syeda Anshrah Gillani, Mirza Samad Ahmed Baig, Muhammad Aamer Saleem, Muhammad Hamzah Siddiqui
This study investigates the use of Large Language Models (LLMs) for improved depression detection from users social media data. Through the use of fine-tuned GPT 3.5 Turbo 1106 and LLaMA2-7B models and a sizable dataset from earlier studies, we were able to identify depressed content in social media posts with a high accuracy of nearly 96.0 percent. The comparative analysis of the obtained results with the relevant studies in the literature shows that the proposed fine-tuned LLMs achieved enhanced performance compared to existing state of the-art systems. This demonstrates the robustness of LLM-based fine-tuned systems to be used as potential depression detection systems. The study describes the approach in depth, including the parameters used and the fine-tuning procedure, and it addresses the important implications of our results for the early diagnosis of depression on several social media platforms.
Read more9/24/2024

0
MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
Zhende Song, Chenchen Wang, Jiamu Sheng, Chi Zhang, Gang Yu, Jiayuan Fan, Tao Chen
Development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short. The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In face of these challenges, we propose MovieLLM, a novel framework designed to synthesize consistent and high-quality video data for instruction tuning. The pipeline is carefully designed to control the style of videos by improving textual inversion technique with powerful text generation capability of GPT-4. As the first framework to do such thing, our approach stands out for its flexibility and scalability, empowering users to create customized movies with only one description. This makes it a superior alternative to traditional data collection methods. Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.
Read more6/26/2024