Have Large Vision-Language Models Mastered Art History?

0
Sign in to get full access
Overview
- This paper provides instructions for authors on how to prepare an anonymous submission and camera-ready article for the AAAI Press.
- The instructions cover guidelines for ensuring anonymity, preparing the camera-ready version, and copyright information.
Plain English Explanation
The paper outlines the steps authors need to follow when submitting a paper to the AAAI Press. The key points are:
-
Anonymity: Authors must take care to remove any identifying information from their submission to keep it anonymous during the review process. This includes removing author names, affiliations, acknowledgments, and other potentially identifying details.
-
Camera-Ready Guidelines: Once a paper is accepted, authors will need to prepare a camera-ready version that adheres to specific formatting requirements. This includes using the provided LaTeX template, ensuring proper section headings, figure/table placement, and other layout details.
-
Copyright: Authors are required to transfer the copyright of their work to the AAAI Press upon acceptance. This allows the AAAI to publish and distribute the paper.
The purpose of these instructions is to ensure a standardized submission and publication process for the AAAI conference proceedings. Following these guidelines helps maintain the anonymity of the review process and ensures a consistent, high-quality final product.
Technical Explanation
The paper outlines the steps authors must take when submitting a paper to the AAAI Press using LaTeX:
-
Anonymity: Authors are required to remove all identifying information from their LaTeX source files, including author names, affiliations, acknowledgments, and other potentially identifying details. This is to ensure the anonymity of the review process.
-
Camera-Ready Guidelines: For the accepted camera-ready version, authors must use the provided AAAI Press LaTeX template and adhere to specific formatting requirements. This includes using the correct section headings, properly placing figures and tables, and ensuring the overall layout meets the AAAI Press standards.
-
Copyright: Upon acceptance of their paper, authors must transfer the copyright of their work to the AAAI Press. This allows the AAAI to publish and distribute the paper through their proceedings.
The goal of these instructions is to streamline the submission and publication process for the AAAI conference, while maintaining the integrity of the double-blind review process and ensuring a consistent, high-quality final product.
Critical Analysis
The instructions provided in this paper are comprehensive and well-designed to meet the needs of the AAAI conference. The emphasis on anonymity during the review process is important for maintaining the integrity of the peer review system. The camera-ready guidelines ensure a consistent formatting and layout across all accepted papers, which enhances the overall quality and readability of the proceedings.
One potential limitation is the reliance on LaTeX as the required typesetting system. While LaTeX is a powerful and widely-used tool, some authors may be more comfortable with other word processing software, which could create additional barriers to entry. Additionally, the copyright transfer requirement may be a concern for some authors, who may prefer to retain more control over their work.
Overall, the instructions provided in this paper are well-thought-out and serve the needs of the AAAI conference effectively. Authors should carefully review and follow these guidelines to ensure a smooth submission and publication process.
Conclusion
The AAAI Press Instructions for Authors Using LaTeX outline the key requirements for submitting and publishing papers in the AAAI conference proceedings. By focusing on anonymity, camera-ready formatting, and copyright, the instructions help maintain the integrity and quality of the AAAI publication process. While there are some potential limitations, the guidelines are comprehensive and well-designed to serve the needs of the AAAI community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Have Large Vision-Language Models Mastered Art History?
Ombretta Strafforello, Derya Soydaner, Michiel Willems, Anne-Sofie Maerten, Stefanie De Winter
The emergence of large Vision-Language Models (VLMs) has recently established new baselines in image classification across multiple domains. However, the performance of VLMs in the specific task of artwork classification, particularly art style classification of paintings - a domain traditionally mastered by art historians - has not been explored yet. Artworks pose a unique challenge compared to natural images due to their inherently complex and diverse structures, characterized by variable compositions and styles. Art historians have long studied the unique aspects of artworks, with style prediction being a crucial component of their discipline. This paper investigates whether large VLMs, which integrate visual and textual data, can effectively predict the art historical attributes of paintings. We conduct an in-depth analysis of four VLMs, namely CLIP, LLaVA, OpenFlamingo, and GPT-4o, focusing on zero-shot classification of art style, author and time period using two public benchmarks of artworks. Additionally, we present ArTest, a well-curated test set of artworks, including pivotal paintings studied by art historians.
Read more9/6/2024

0
Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Read more4/16/2024

1
An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Read more5/28/2024
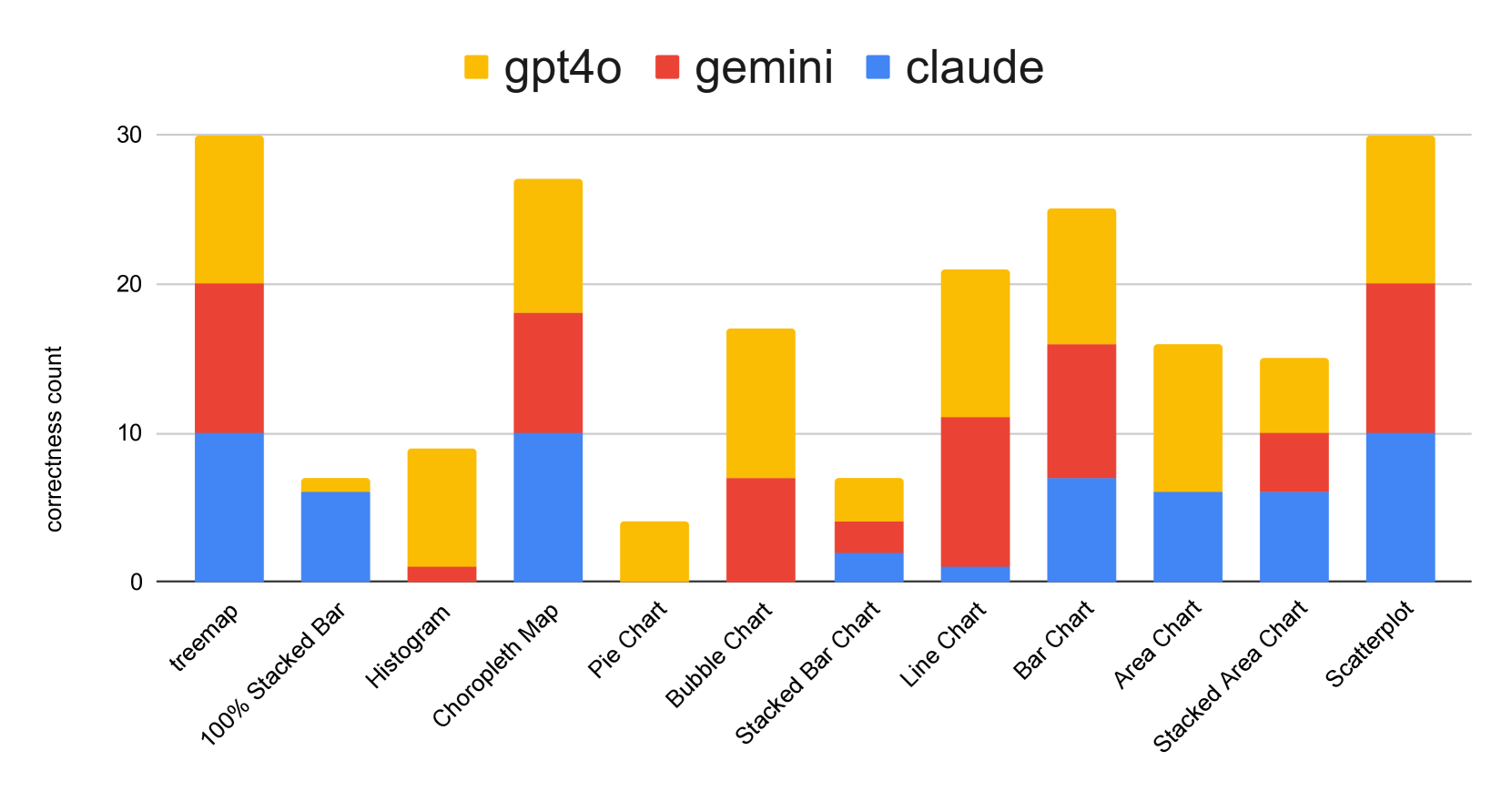
0
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024