Helix: Distributed Serving of Large Language Models via Max-Flow on Heterogeneous GPUs

0
Sign in to get full access
Overview
- This paper presents Helix, a distributed serving system for large language models (LLMs) that uses max-flow optimization on heterogeneous GPUs to improve cost-efficiency and performance.
- Helix addresses the challenges of serving increasingly large and complex LLMs, including high inference latency and significant resource requirements.
- The system utilizes a max-flow algorithm to dynamically allocate resources and distribute workloads across a cluster of heterogeneous GPUs, optimizing for throughput and cost-efficiency.
Plain English Explanation
Helix is a new system designed to help companies and researchers more efficiently use and run large language models (LLMs) - the complex artificial intelligence systems that can understand and generate human-like text. As LLMs continue to grow in size and complexity, it's become increasingly challenging and expensive to serve them, meaning to run them and provide their capabilities to users.
Melange: Cost-Efficient Large Language Model Serving and MuxServe: Flexible Multiplexing for Efficient Multiple LLM Serving have explored ways to make LLM serving more efficient, but Helix takes a novel approach.
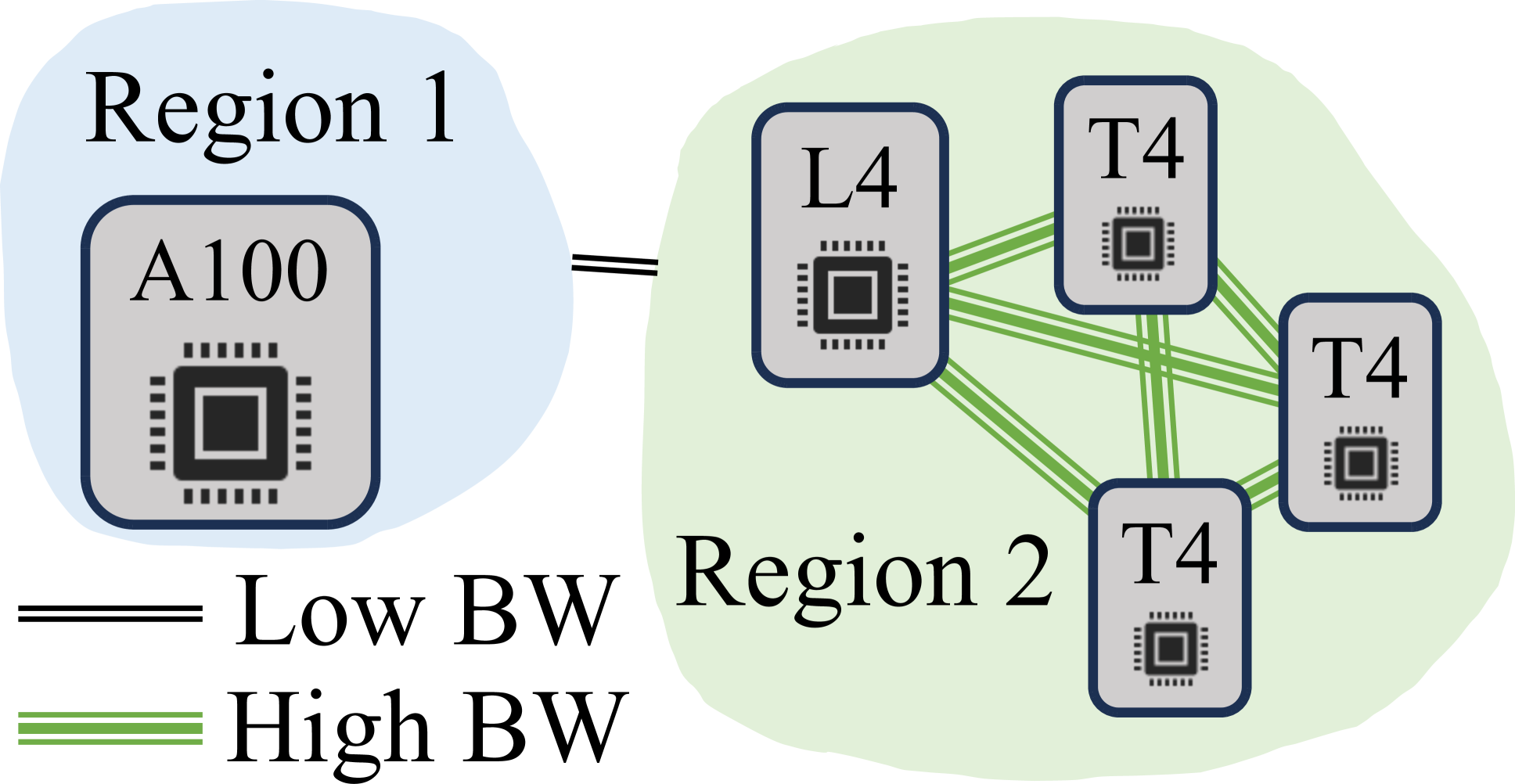
Helix uses a technique called "max-flow optimization" to dynamically allocate computing resources, like graphics processing units (GPUs), across a cluster to best handle the workload. This helps Helix serve LLMs more quickly and at a lower cost compared to other systems. The key insight is that different types of GPUs excel at different parts of the LLM inference process, so Helix can intelligently distribute the work to get the most out of the available hardware.
Technical Explanation
Helix addresses the challenge of efficiently serving large language models (LLMs) by leveraging a max-flow optimization algorithm to dynamically allocate resources across a cluster of heterogeneous GPUs.
The system is motivated by the growing complexity and resource requirements of modern LLMs, which can make it difficult and expensive to serve them at scale. Prior work like Melange: Cost-Efficient Large Language Model Serving and MuxServe: Flexible Multiplexing for Efficient Multiple LLM Serving has explored ways to improve LLM serving efficiency, but Helix takes a novel approach.
The key innovation in Helix is the use of a max-flow algorithm to dynamically allocate GPUs to different stages of the LLM inference process. The intuition is that different GPU architectures excel at different aspects of LLM inference, such as tensor operations or memory access patterns. By intelligently distributing the workload across a heterogeneous GPU cluster, Helix can optimize for both throughput and cost-efficiency.
The Helix architecture consists of three main components:
- Task Scheduler: Responsible for decomposing LLM inference requests into fine-grained tasks and managing their execution.
- Resource Allocator: Uses a max-flow optimization algorithm to dynamically assign tasks to the available GPU resources, balancing throughput and cost.
- Distributed Runtime: Coordinates the execution of tasks across the heterogeneous GPU cluster.
Through extensive experimentation, the authors demonstrate that Helix can achieve up to 2.5x higher throughput and 40% lower cost compared to existing LLM serving systems, while also providing better load balancing and resource utilization.
Critical Analysis
The Helix paper presents a promising approach to the challenge of efficiently serving large language models, but there are a few potential limitations and areas for further research:
-
Heterogeneous GPU Assumptions: Helix assumes the availability of a diverse GPU cluster, which may not always be the case, especially for smaller organizations or research labs. The benefits of Helix's max-flow optimization may be less pronounced in more homogeneous GPU environments.
-
Generalization to Other AI Models: While the paper focuses on LLMs, the techniques used in Helix could potentially be applied to other types of AI models, such as computer vision or reinforcement learning models. Exploring the generalizability of the approach would be an interesting area for future work.
-
Real-World Deployment Challenges: The paper does not address some of the practical challenges that may arise when deploying Helix in a production environment, such as handling failures, managing multi-tenant workloads, or integrating with existing infrastructure.
-
Fairness and Equity Considerations: As with any AI system, there are potential concerns around the fairness and equity of Helix's resource allocation decisions, especially if the system is serving a diverse set of users or applications. Understanding and mitigating these issues would be an important area of further research.
Overall, the Helix paper presents a well-designed and promising approach to the challenge of serving large language models efficiently. With further research and real-world deployment, the techniques developed in this work could have a significant impact on the field of AI infrastructure and serve as a foundation for more advanced distributed serving systems.
Conclusion
The Helix paper introduces a novel distributed serving system for large language models that uses max-flow optimization to efficiently allocate resources across a heterogeneous GPU cluster. By leveraging the unique capabilities of different GPU architectures, Helix can achieve significant improvements in throughput and cost-efficiency compared to existing LLM serving systems.
HexGen: Generative Inference for Large Language Model over Heterogeneous Clusters, HetHub: Heterogeneous Distributed Hybrid Training System for Large, and Holmes: Towards Distributed Training Across Clusters of Heterogeneous hardware represent other promising directions in the field of distributed AI systems that could complement and build upon the innovations introduced in Helix.
As LLMs continue to grow in size and complexity, the need for efficient and scalable serving systems will only increase. The Helix paper demonstrates the value of careful resource management and heterogeneous hardware utilization in addressing this challenge, and its insights could have far-reaching implications for the future of large-scale AI deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Helix: Distributed Serving of Large Language Models via Max-Flow on Heterogeneous GPUs
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, Rashmi Vinayak
This paper introduces Helix, a distributed system for high-throughput, low-latency large language model (LLM) serving on heterogeneous GPU clusters. A key idea behind Helix is to formulate inference computation of LLMs over heterogeneous GPUs and network connections as a max-flow problem for a directed, weighted graph, whose nodes represent GPU instances and edges capture both GPU and network heterogeneity through their capacities. Helix then uses a mixed integer linear programming (MILP) algorithm to discover highly optimized strategies to serve LLMs. This approach allows Helix to jointly optimize model placement and request scheduling, two highly entangled tasks in heterogeneous LLM serving. Our evaluation on several heterogeneous cluster settings ranging from 24 to 42 GPU nodes shows that Helix improves serving throughput by up to 2.7$times$ and reduces prompting and decoding latency by up to 2.8$times$ and 1.3$times$, respectively, compared to best existing approaches.
Read more6/4/2024

0
FlashFlex: Accommodating Large Language Model Training over Heterogeneous Environment
Ran Yan, Youhe Jiang, Wangcheng Tao, Xiaonan Nie, Bin Cui, Binhang Yuan
Training large language model (LLM) is a computationally intensive task, which is typically conducted in data centers with homogeneous high-performance GPUs. This paper explores an alternative approach by deploying the training computation across heterogeneous GPUs to enable better flexibility and efficiency for heterogeneous resource utilization. To achieve this goal, we propose a novel system, FlashFlex, that can flexibly support an asymmetric partition of the parallel training computations across the scope of data-, pipeline-, and tensor model parallelism. We further formalize the allocation of asymmetric partitioned training computations over a set of heterogeneous GPUs as a constrained optimization problem and propose an efficient solution based on a hierarchical graph partitioning algorithm. Our approach can adaptively allocate asymmetric training computations across GPUs, fully leveraging the available computational power. We conduct extensive empirical studies to evaluate the performance of FlashFlex, where we find that when training LLMs at different scales (from 7B to 30B), FlashFlex can achieve comparable training MFU when running over a set of heterogeneous GPUs compared with the state of the art training systems running over a set of homogeneous high-performance GPUs with the same amount of total peak FLOPS. The achieved smallest gaps in MFU are 11.61% and 0.30%, depending on whether the homogeneous setting is equipped with and without RDMA. Our implementation is available at https://github.com/Relaxed-System-Lab/FlashFlex.
Read more9/4/2024
💬
0
M'elange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity
Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, Ion Stoica
Large language models (LLMs) are increasingly integrated into many online services, yet they remain cost-prohibitive to deploy due to the requirement of expensive GPU instances. Prior work has addressed the high cost of LLM serving by improving the inference engine, but less attention has been given to selecting the most cost-efficient GPU type(s) for a specific LLM service. There is a large and growing landscape of GPU types and, within these options, higher cost does not always lead to increased performance. Instead, through a comprehensive investigation, we find that three key LLM service characteristics (request size, request rate, SLO) strongly influence GPU cost efficiency, and differing GPU types are most cost efficient for differing LLM service settings. As a result, the most cost-efficient allocation for a given service is typically a mix of heterogeneous GPU types. Based on this analysis, we introduce M'elange, a GPU allocation framework that navigates these diverse LLM service characteristics and heterogeneous GPU option space to automatically and efficiently derive the minimal-cost GPU allocation for a given LLM service. We formulate the GPU allocation task as a cost-aware bin packing problem where GPUs are bins and items are slices of the service workload. Our formulation's constraints account for a service's unique characteristics, allowing M'elange to be flexible to support diverse service settings and heterogeneity-aware to adapt the GPU allocation to a specific service. Compared to using only a single GPU type, M'elange reduces deployment costs by up to 77% in conversational settings, 33% in document-based settings, and 51% in a mixed setting.
Read more7/23/2024
🤯
0
HexGen: Generative Inference of Large Language Model over Heterogeneous Environment
Youhe Jiang, Ran Yan, Xiaozhe Yao, Yang Zhou, Beidi Chen, Binhang Yuan
Serving generative inference of the large language model is a crucial component of contemporary AI applications. This paper focuses on deploying such services in a heterogeneous and cross-datacenter setting to mitigate the substantial inference costs typically associated with a single centralized datacenter. Towards this end, we propose HexGen, a flexible distributed inference engine that uniquely supports the asymmetric partition of generative inference computations over both tensor model parallelism and pipeline parallelism and allows for effective deployment across diverse GPUs interconnected by a fully heterogeneous network. We further propose a sophisticated scheduling algorithm grounded in constrained optimization that can adaptively assign asymmetric inference computation across the GPUs to fulfill inference requests while maintaining acceptable latency levels. We conduct an extensive evaluation to verify the efficiency of HexGen by serving the state-of-the-art Llama-2 (70B) model. The results suggest that HexGen can choose to achieve up to 2.3 times lower latency deadlines or tolerate up to 4 times more request rates compared with the homogeneous baseline given the same budget.
Read more5/28/2024