HexGen: Generative Inference of Large Language Model over Heterogeneous Environment

0
🤯
Sign in to get full access
Overview
- This paper presents a distributed inference engine called HexGen that can efficiently serve large language models across heterogeneous GPU hardware and network infrastructure.
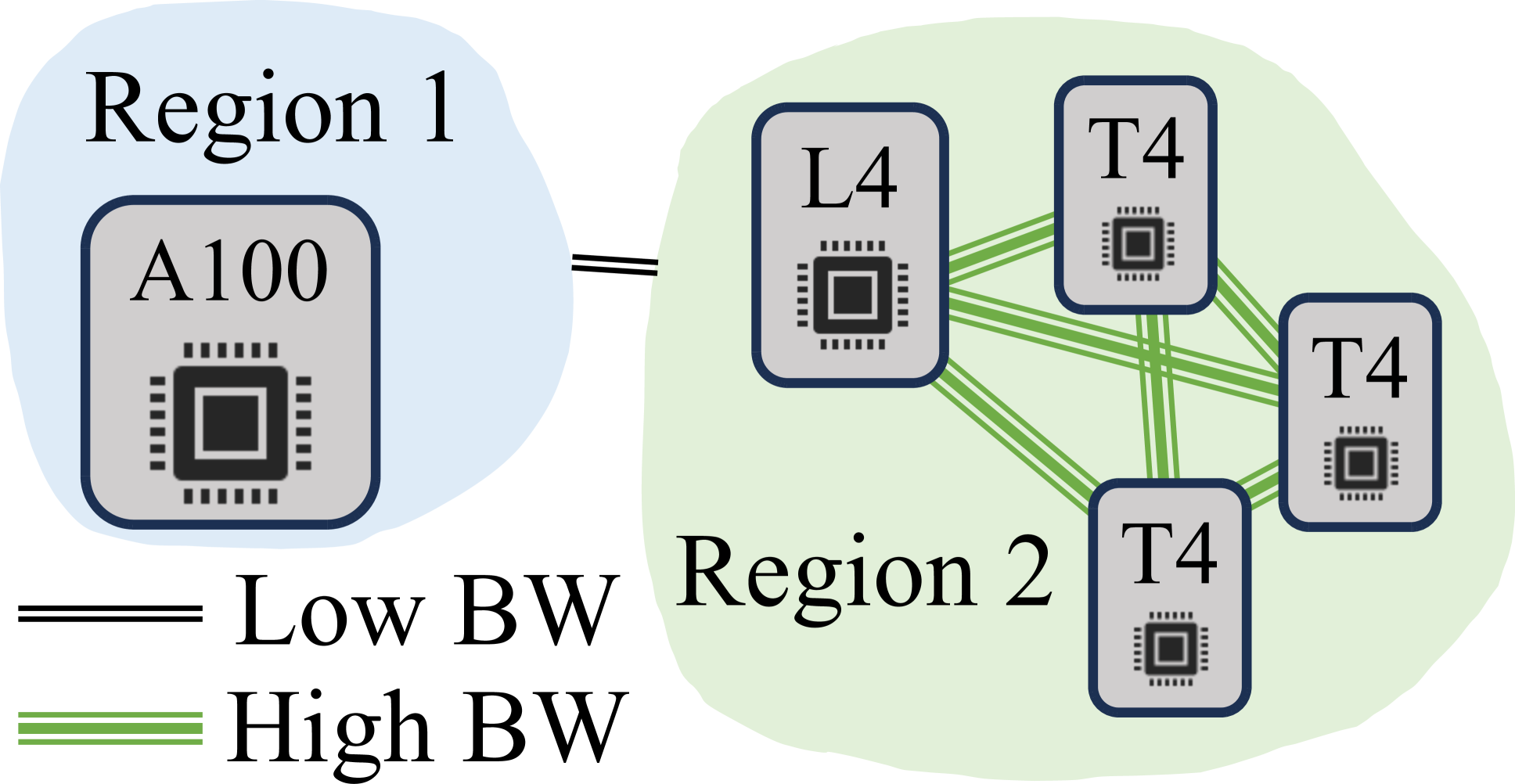
- HexGen supports both tensor model parallelism and pipeline parallelism to partition inference computations, allowing it to be deployed in diverse GPU setups.
- The paper also introduces a scheduling algorithm that can adaptively assign inference tasks across the available GPUs to meet latency requirements and handle high request volumes.
- The authors evaluate HexGen by serving the state-of-the-art Llama-2 (70B) model, showing it can achieve up to 2.3 times lower latency or handle up to 4 times more requests compared to a homogeneous baseline.
Plain English Explanation
Large language models like LLaMA-2 have become crucial components of modern AI applications. However, serving these models for real-time inference can be prohibitively expensive, especially when relying on a single centralized data center.
To address this challenge, the researchers have developed a flexible distributed inference engine called HexGen. HexGen can efficiently partition the inference computations across a heterogeneous network of GPUs using both tensor model parallelism and pipeline parallelism. This allows HexGen to be deployed in diverse GPU setups, rather than being limited to a homogeneous infrastructure.
Additionally, HexGen employs a sophisticated scheduling algorithm that can dynamically assign inference tasks to the available GPUs. This helps HexGen meet latency requirements and handle high volumes of inference requests, even with a limited budget.
The researchers evaluated HexGen by using it to serve the large LLaMA-2 (70B) language model. The results show that HexGen can either achieve up to 2.3 times lower latency or handle up to 4 times more requests compared to a baseline system, given the same overall resource budget.
Technical Explanation
The paper presents HexGen, a distributed inference engine designed to efficiently serve large language models like LLaMA-2 across heterogeneous GPU hardware and network infrastructure.
HexGen supports both tensor model parallelism and pipeline parallelism to partition the inference computations. This allows the system to be deployed in diverse GPU setups, unlike a homogeneous baseline that would be limited to a single type of GPU.
The paper also introduces a sophisticated scheduling algorithm that can adaptively assign the asymmetric inference computations across the available GPUs. This scheduling approach is grounded in constrained optimization and helps HexGen fulfill inference requests while maintaining acceptable latency levels, even when faced with high request volumes.
The authors extensively evaluate the performance of HexGen by using it to serve the state-of-the-art LLaMA-2 (70B) language model. The results demonstrate that HexGen can either achieve up to 2.3 times lower latency deadlines or tolerate up to 4 times more request rates compared to a homogeneous baseline, given the same overall resource budget.
Critical Analysis
The paper presents a compelling solution to the challenge of efficiently serving large language models in a distributed, heterogeneous setting. The HexGen system and its accompanying scheduling algorithm appear to be well-designed and effective based on the reported results.
However, the paper does not delve deeply into potential limitations or areas for further research. For example, it would be valuable to understand how HexGen's performance scales as the number of GPUs or the size of the language model increases. Additionally, the paper does not address potential issues related to fault tolerance, load balancing, or dynamic resource allocation that may arise in a real-world production environment.
Furthermore, the authors could have provided more insight into the trade-offs involved in their design choices, such as the relative merits and drawbacks of tensor model parallelism versus pipeline parallelism, or the implications of their constrained optimization-based scheduling approach.
Overall, the paper makes a valuable contribution by demonstrating the feasibility and benefits of a distributed inference engine like HexGen. However, further research and analysis would be needed to fully understand the system's limitations and its broader applicability in the context of large-scale AI deployments.
Conclusion
This paper presents HexGen, a flexible distributed inference engine that can efficiently serve large language models like LLaMA-2 across heterogeneous GPU hardware and network infrastructure.
HexGen's unique support for both tensor model parallelism and pipeline parallelism allows it to be deployed in diverse GPU setups, unlike a homogeneous baseline. The paper also introduces a sophisticated scheduling algorithm that can adaptively assign inference computations to the available GPUs, helping to meet latency requirements and handle high request volumes.
The extensive evaluation of HexGen serving the LLaMA-2 (70B) model demonstrates its potential to significantly improve the cost-efficiency and scalability of large language model serving, with the ability to either achieve lower latency or handle more requests compared to a homogeneous baseline.
While the paper does not address all potential limitations, it represents an important step forward in enabling the widespread deployment of large language models in real-world AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
HexGen: Generative Inference of Large Language Model over Heterogeneous Environment
Youhe Jiang, Ran Yan, Xiaozhe Yao, Yang Zhou, Beidi Chen, Binhang Yuan
Serving generative inference of the large language model is a crucial component of contemporary AI applications. This paper focuses on deploying such services in a heterogeneous and cross-datacenter setting to mitigate the substantial inference costs typically associated with a single centralized datacenter. Towards this end, we propose HexGen, a flexible distributed inference engine that uniquely supports the asymmetric partition of generative inference computations over both tensor model parallelism and pipeline parallelism and allows for effective deployment across diverse GPUs interconnected by a fully heterogeneous network. We further propose a sophisticated scheduling algorithm grounded in constrained optimization that can adaptively assign asymmetric inference computation across the GPUs to fulfill inference requests while maintaining acceptable latency levels. We conduct an extensive evaluation to verify the efficiency of HexGen by serving the state-of-the-art Llama-2 (70B) model. The results suggest that HexGen can choose to achieve up to 2.3 times lower latency deadlines or tolerate up to 4 times more request rates compared with the homogeneous baseline given the same budget.
Read more5/28/2024
0
Helix: Distributed Serving of Large Language Models via Max-Flow on Heterogeneous GPUs
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, Rashmi Vinayak
This paper introduces Helix, a distributed system for high-throughput, low-latency large language model (LLM) serving on heterogeneous GPU clusters. A key idea behind Helix is to formulate inference computation of LLMs over heterogeneous GPUs and network connections as a max-flow problem for a directed, weighted graph, whose nodes represent GPU instances and edges capture both GPU and network heterogeneity through their capacities. Helix then uses a mixed integer linear programming (MILP) algorithm to discover highly optimized strategies to serve LLMs. This approach allows Helix to jointly optimize model placement and request scheduling, two highly entangled tasks in heterogeneous LLM serving. Our evaluation on several heterogeneous cluster settings ranging from 24 to 42 GPU nodes shows that Helix improves serving throughput by up to 2.7$times$ and reduces prompting and decoding latency by up to 2.8$times$ and 1.3$times$, respectively, compared to best existing approaches.
Read more6/4/2024
0
InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management
Wonbeom Lee, Jungi Lee, Junghwan Seo, Jaewoong Sim
Transformer-based large language models (LLMs) demonstrate impressive performance across various natural language processing tasks. Serving LLM inference for generating long contents, however, poses a challenge due to the enormous memory footprint of the transient state, known as the key-value (KV) cache, which scales with the sequence length and batch size. In this paper, we present InfiniGen, a novel KV cache management framework tailored for long-text generation, which synergistically works with modern offloading-based inference systems. InfiniGen leverages the key insight that a few important tokens that are essential for computing the subsequent attention layer in the Transformer can be speculated by performing a minimal rehearsal with the inputs of the current layer and part of the query weight and key cache of the subsequent layer. This allows us to prefetch only the essential KV cache entries (without fetching them all), thereby mitigating the fetch overhead from the host memory in offloading-based LLM serving systems. Our evaluation on several representative LLMs shows that InfiniGen improves the overall performance of a modern offloading-based system by up to 3.00x compared to prior KV cache management methods while offering substantially better model accuracy.
Read more7/1/2024
🤯
0
Fast Distributed Inference Serving for Large Language Models
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, Xin Jin
Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demands low latency for LLM inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long latency. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize latency with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi-information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate state between GPU memory and host memory for LLM inference. We build a system prototype of FastServe and experimental results show that compared to the state-of-the-art solution vLLM, FastServe improves the throughput by up to 31.4x and 17.9x under the same average and tail latency requirements, respectively.
Read more9/26/2024