M'elange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) are becoming increasingly common in online services
- A major challenge in using LLMs is their high cost, primarily due to the use of expensive GPU hardware
- This paper explores how the diversity of GPU types can be leveraged to reduce LLM deployment costs
Plain English Explanation
Large language models (LLMs) are powerful AI systems that are being integrated into many online applications, such as chatbots, content generation tools, and search engines. However, a key challenge with using LLMs is their high cost. This is largely due to the need for expensive GPU hardware to run the computationally intensive models.
The authors of this paper recognized an opportunity to address this issue by taking advantage of the significant diversity in available GPU types. The GPU market has grown substantially, offering a wide range of options with varying capabilities and price points. The researchers found that there is not always a linear relationship between a GPU's cost and its performance. Certain GPU types may be more cost-effective than others, depending on the specific characteristics of the LLM service, such as the size of the model requests, the request rate, and the desired latency service-level objective (SLO).
To help navigate this complex GPU landscape, the researchers developed a framework called M'elange. M'elange treats the task of selecting the optimal GPU configuration as a cost-aware bin-packing problem. It analyzes the LLM service requirements and the available GPU options to determine the minimal-cost GPU allocation that still meets the specified latency SLO.
The researchers evaluated M'elange using both real-world and synthetic datasets, and found that it can reduce LLM deployment costs by up to 77% compared to using a single GPU type. This highlights the importance of making informed, heterogeneity-aware decisions when provisioning GPUs for LLM serving.
Technical Explanation
The paper starts by recognizing the growing prevalence of large language models (LLMs) in online services, and the significant challenge of their high deployment costs, which are primarily driven by the use of expensive GPU hardware.
To address this problem, the researchers leverage the substantial heterogeneity observed in the GPU market. The broad and growing selection of GPU types, each with varying cost and hardware specifications, presents an opportunity to increase the cost-efficiency of LLM deployment.
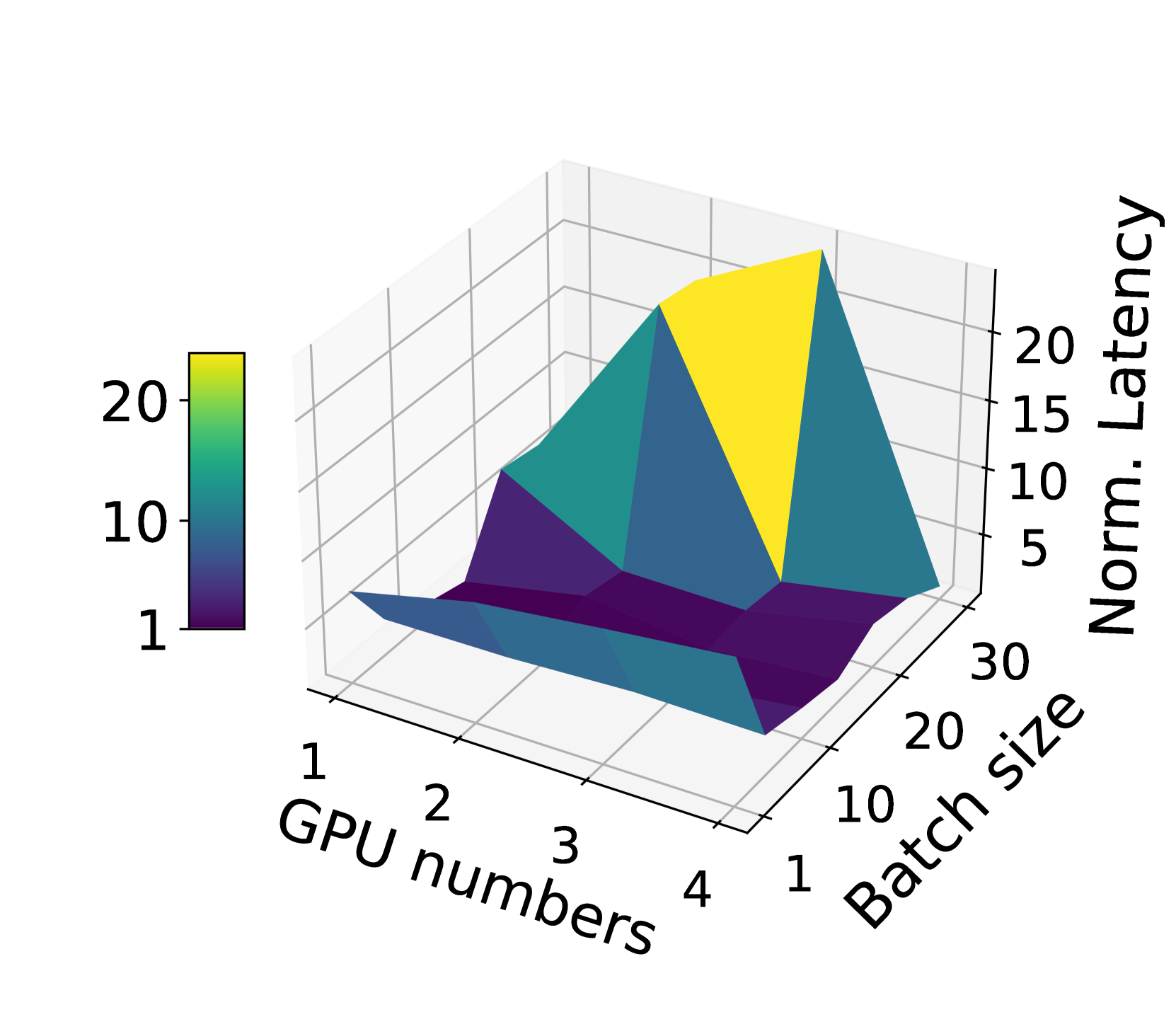
Through their analysis, the authors find that there is not a linear relationship between GPU cost and performance. Instead, they identify three key LLM service characteristics that significantly impact which GPU type is the most cost-effective: model request size, request rate, and latency service-level objective (SLO).
Building on these insights, the researchers present M'elange, a framework for navigating the diverse GPU options and LLM service specifications to derive the most cost-efficient GPU allocation. M'elange frames the GPU selection task as a cost-aware bin-packing problem, where GPUs are bins with a capacity and cost, and model requests are items with a defined size and rate.
The evaluations conducted by the authors, using both real-world and synthetic datasets, demonstrate that M'elange can significantly reduce LLM deployment costs, with savings of up to 77% compared to using a single GPU type. This underscores the importance of making heterogeneity-aware decisions when provisioning GPUs for LLM serving.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing the high cost of LLM deployment, which is a crucial challenge in the field. The researchers' recognition of the opportunity presented by GPU heterogeneity and their subsequent development of the M'elange framework are both innovative and practical.
One potential limitation of the study is the use of synthetic datasets in addition to real-world data. While the synthetic data allowed for more controlled experimentation, it would be valuable to see the performance of M'elange evaluated on an even wider range of real-world LLM services and workloads.
Additionally, the paper could have delved deeper into the potential implications of their findings, both for the LLM research community and for the broader impact on AI-powered services and their users. Exploring how M'elange's approach could influence the development of more cost-efficient and energy-efficient LLMs would be a valuable addition to the analysis.
Despite these minor points, the paper represents a significant contribution to the field of LLM deployment and serves as a strong example of how leveraging hardware heterogeneity can lead to substantial cost savings and efficiency improvements.
Conclusion
This paper tackles the critical challenge of high deployment costs for large language models (LLMs), which are becoming increasingly prevalent in various online services. By recognizing the opportunity presented by the significant heterogeneity in the GPU market, the researchers developed the M'elange framework to navigate this diverse landscape and derive the most cost-efficient GPU allocation for a given LLM service.
The evaluations conducted by the authors demonstrate that M'elange can reduce LLM deployment costs by up to 77% compared to using a single GPU type. This highlights the importance of making informed, heterogeneity-aware decisions when provisioning hardware resources for LLM serving.
The insights and approaches presented in this paper have the potential to significantly impact the deployment of LLMs, making them more accessible and cost-effective for a wider range of applications and services. As the demand for powerful language models continues to grow, the work done in this study will help pave the way for more energy-efficient and cost-effective LLM integration across the industry.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
M'elange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity
Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, Ion Stoica
Large language models (LLMs) are increasingly integrated into many online services, yet they remain cost-prohibitive to deploy due to the requirement of expensive GPU instances. Prior work has addressed the high cost of LLM serving by improving the inference engine, but less attention has been given to selecting the most cost-efficient GPU type(s) for a specific LLM service. There is a large and growing landscape of GPU types and, within these options, higher cost does not always lead to increased performance. Instead, through a comprehensive investigation, we find that three key LLM service characteristics (request size, request rate, SLO) strongly influence GPU cost efficiency, and differing GPU types are most cost efficient for differing LLM service settings. As a result, the most cost-efficient allocation for a given service is typically a mix of heterogeneous GPU types. Based on this analysis, we introduce M'elange, a GPU allocation framework that navigates these diverse LLM service characteristics and heterogeneous GPU option space to automatically and efficiently derive the minimal-cost GPU allocation for a given LLM service. We formulate the GPU allocation task as a cost-aware bin packing problem where GPUs are bins and items are slices of the service workload. Our formulation's constraints account for a service's unique characteristics, allowing M'elange to be flexible to support diverse service settings and heterogeneity-aware to adapt the GPU allocation to a specific service. Compared to using only a single GPU type, M'elange reduces deployment costs by up to 77% in conversational settings, 33% in document-based settings, and 51% in a mixed setting.
Read more7/23/2024
0
UELLM: A Unified and Efficient Approach for LLM Inference Serving
Yiyuan He, Minxian Xu, Jingfeng Wu, Wanyi Zheng, Kejiang Ye, Chengzhong Xu
In the context of Machine Learning as a Service (MLaaS) clouds, the extensive use of Large Language Models (LLMs) often requires efficient management of significant query loads. When providing real-time inference services, several challenges arise. Firstly, increasing the number of GPUs may lead to a decrease in inference speed due to heightened communication overhead, while an inadequate number of GPUs can lead to out-of-memory errors. Secondly, different deployment strategies need to be evaluated to guarantee optimal utilization and minimal inference latency. Lastly, inefficient orchestration of inference queries can easily lead to significant Service Level Objective (SLO) violations. Lastly, inefficient orchestration of inference queries can easily lead to significant Service Level Objective (SLO) violations. To address these challenges, we propose a Unified and Efficient approach for Large Language Model inference serving (UELLM), which consists of three main components: 1) resource profiler, 2) batch scheduler, and 3) LLM deployer. UELLM minimizes resource overhead, reduces inference latency, and lowers SLO violation rates. Compared with state-of-the-art (SOTA) techniques, UELLM reduces the inference latency by 72.3% to 90.3%, enhances GPU utilization by 1.2X to 4.1X, and increases throughput by 1.92X to 4.98X, it can also serve without violating the inference latency SLO.
Read more9/25/2024

0
FlashFlex: Accommodating Large Language Model Training over Heterogeneous Environment
Ran Yan, Youhe Jiang, Wangcheng Tao, Xiaonan Nie, Bin Cui, Binhang Yuan
Training large language model (LLM) is a computationally intensive task, which is typically conducted in data centers with homogeneous high-performance GPUs. This paper explores an alternative approach by deploying the training computation across heterogeneous GPUs to enable better flexibility and efficiency for heterogeneous resource utilization. To achieve this goal, we propose a novel system, FlashFlex, that can flexibly support an asymmetric partition of the parallel training computations across the scope of data-, pipeline-, and tensor model parallelism. We further formalize the allocation of asymmetric partitioned training computations over a set of heterogeneous GPUs as a constrained optimization problem and propose an efficient solution based on a hierarchical graph partitioning algorithm. Our approach can adaptively allocate asymmetric training computations across GPUs, fully leveraging the available computational power. We conduct extensive empirical studies to evaluate the performance of FlashFlex, where we find that when training LLMs at different scales (from 7B to 30B), FlashFlex can achieve comparable training MFU when running over a set of heterogeneous GPUs compared with the state of the art training systems running over a set of homogeneous high-performance GPUs with the same amount of total peak FLOPS. The achieved smallest gaps in MFU are 11.61% and 0.30%, depending on whether the homogeneous setting is equipped with and without RDMA. Our implementation is available at https://github.com/Relaxed-System-Lab/FlashFlex.
Read more9/4/2024

0
Deploying Open-Source Large Language Models: A performance Analysis
Yannis Bendi-Ouis, Dan Dutarte, Xavier Hinaut
Since the release of ChatGPT in November 2022, large language models (LLMs) have seen considerable success, including in the open-source community, with many open-weight models available. However, the requirements to deploy such a service are often unknown and difficult to evaluate in advance. To facilitate this process, we conducted numerous tests at the Centre Inria de l'Universit'e de Bordeaux. In this article, we propose a comparison of the performance of several models of different sizes (mainly Mistral and LLaMa) depending on the available GPUs, using vLLM, a Python library designed to optimize the inference of these models. Our results provide valuable information for private and public groups wishing to deploy LLMs, allowing them to evaluate the performance of different models based on their available hardware. This study thus contributes to facilitating the adoption and use of these large language models in various application domains.
Read more9/26/2024