Heterogeneous Face Recognition Using Domain Invariant Units

0

Sign in to get full access
Overview
- This paper proposes a novel approach for heterogeneous face recognition, which is the task of matching faces across different modalities or domains.
- The key innovation is the use of "domain invariant units" - neural network features that are robust to variations in factors like lighting, angle, and sensor type.
- The authors demonstrate the effectiveness of their method through experiments on several face recognition benchmarks, showing improvements over existing techniques.
Plain English Explanation
Imagine you have two photos of the same person - one taken with a high-quality DSLR camera, and another captured on a grainy smartphone. Matching these two faces can be very challenging, as the differences in image quality, lighting, and other factors can make them appear quite different.
The researchers behind this paper have developed a new technique to address this "heterogeneous face recognition" problem. Their key insight is to train a neural network to extract features from faces that are invariant to these types of domain shifts - that is, the features remain consistent even as the underlying image characteristics change.
By learning these "domain invariant units," the network can more effectively match faces across modalities, like DSLR and smartphone photos. The authors show through extensive experiments that this approach outperforms previous methods on several benchmark datasets, bringing us closer to the goal of robust, cross-domain face recognition.
Technical Explanation
The paper introduces a novel neural network architecture and training procedure for heterogeneous face recognition. At the core of their approach is the concept of "domain invariant units" - features extracted by the network that are robust to variations in factors like lighting, angle, and sensor type.
To learn these domain-invariant representations, the authors propose a multi-task training scheme. The network is tasked not only with recognizing individual identities, but also predicting the underlying domain (e.g. DSLR vs. smartphone) of each input face image. This "domain classification" objective encourages the network to discover features that are discriminative for identity but insensitive to domain shifts.
The authors evaluate their method, dubbed "DIU-Net," on several heterogeneous face recognition benchmarks, including VisualFace and IJB-C. They show consistent improvements over previous state-of-the-art techniques, particularly in scenarios with large domain gaps between probe and gallery images.
Critical Analysis
The key strength of this work is the novel concept of domain-invariant units, which provides a principled way to address the challenge of heterogeneous face recognition. By explicitly modeling and disentangling domain-specific and identity-related features, the authors demonstrate significant performance gains over prior methods.
That said, the paper does not provide much insight into the internal workings of the domain-invariant units or how they differ from standard face recognition features. Further analysis and visualization, as explored in this related work, could shed more light on what these units have learned and why they are effective.
Additionally, the experiments are limited to two-domain scenarios (e.g. DSLR vs. smartphone). It would be valuable to see how the method scales to more diverse and realistic multi-domain face recognition settings, as investigated in this paper.
Finally, the authors do not discuss the computational complexity or inference speed of their DIU-Net architecture, which are crucial practical considerations for real-world face recognition systems. Comparisons to more efficient techniques, like the adapters proposed in related work, would help contextualize the trade-offs of this approach.
Conclusion
This paper presents a promising new direction for heterogeneous face recognition through the use of domain-invariant neural network features. By learning representations that are robust to modality shifts, the authors demonstrate significant performance improvements over existing methods on several benchmark datasets.
While further research is needed to fully understand the inner workings of the domain-invariant units and to evaluate the scalability and efficiency of the approach, this work represents an important step forward in addressing the practical challenges of face recognition in the real world. As the field continues to evolve, techniques like this will be crucial for developing reliable and inclusive face recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Heterogeneous Face Recognition Using Domain Invariant Units
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) aims to expand the applicability of Face Recognition (FR) systems to challenging scenarios, enabling the matching of face images across different domains, such as matching thermal images to visible spectra. However, the development of HFR systems is challenging because of the significant domain gap between modalities and the lack of availability of large-scale paired multi-channel data. In this work, we leverage a pretrained face recognition model as a teacher network to learn domaininvariant network layers called Domain-Invariant Units (DIU) to reduce the domain gap. The proposed DIU can be trained effectively even with a limited amount of paired training data, in a contrastive distillation framework. This proposed approach has the potential to enhance pretrained models, making them more adaptable to a wider range of variations in data. We extensively evaluate our approach on multiple challenging benchmarks, demonstrating superior performance compared to state-of-the-art methods.
Read more4/23/2024

0
From Modalities to Styles: Rethinking the Domain Gap in Heterogeneous Face Recognition
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) focuses on matching faces from different domains, for instance, thermal to visible images, making Face Recognition (FR) systems more versatile for challenging scenarios. However, the domain gap between these domains and the limited large-scale datasets in the target HFR modalities make it challenging to develop robust HFR models from scratch. In our work, we view different modalities as distinct styles and propose a method to modulate feature maps of the target modality to address the domain gap. We present a new Conditional Adaptive Instance Modulation (CAIM ) module that seamlessly fits into existing FR networks, turning them into HFR-ready systems. The CAIM block modulates intermediate feature maps, efficiently adapting to the style of the source modality and bridging the domain gap. Our method enables end-to-end training using a small set of paired samples. We extensively evaluate the proposed approach on various challenging HFR benchmarks, showing that it outperforms state-of-the-art methods. The source code and protocols for reproducing the findings will be made publicly available
Read more4/23/2024
0
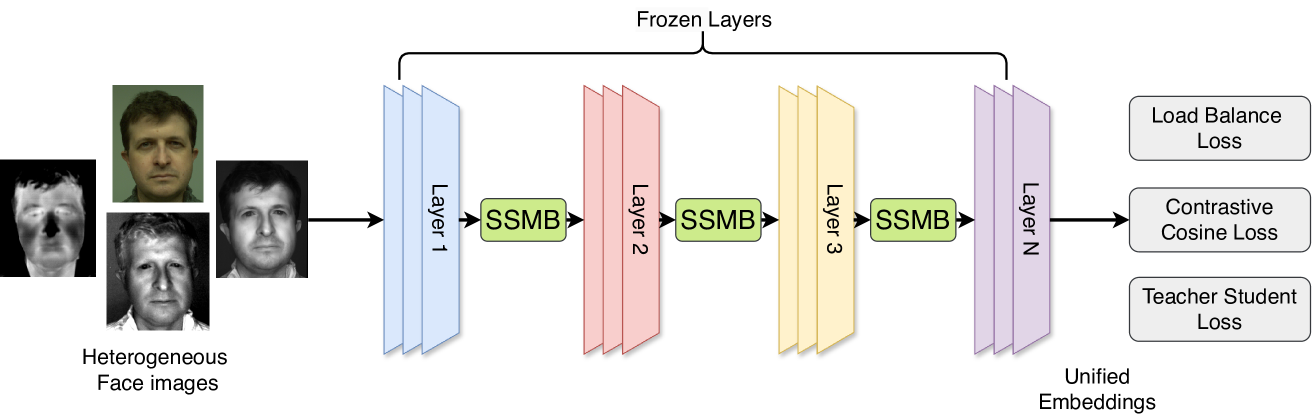
Modality Agnostic Heterogeneous Face Recognition with Switch Style Modulators
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) systems aim to enhance the capability of face recognition in challenging cross-modal authentication scenarios. However, the significant domain gap between the source and target modalities poses a considerable challenge for cross-domain matching. Existing literature primarily focuses on developing HFR approaches for specific pairs of face modalities, necessitating the explicit training of models for each source-target combination. In this work, we introduce a novel framework designed to train a modality-agnostic HFR method capable of handling multiple modalities during inference, all without explicit knowledge of the target modality labels. We achieve this by implementing a computationally efficient automatic routing mechanism called Switch Style Modulation Blocks (SSMB) that trains various domain expert modulators which transform the feature maps adaptively reducing the domain gap. Our proposed SSMB can be trained end-to-end and seamlessly integrated into pre-trained face recognition models, transforming them into modality-agnostic HFR models. We have performed extensive evaluations on HFR benchmark datasets to demonstrate its effectiveness. The source code and protocols will be made publicly available.
Read more7/12/2024

0
Template-based Multi-Domain Face Recognition
Anirudh Nanduri, Rama Chellappa
Despite the remarkable performance of deep neural networks for face detection and recognition tasks in the visible spectrum, their performance on more challenging non-visible domains is comparatively still lacking. While significant research has been done in the fields of domain adaptation and domain generalization, in this paper we tackle scenarios in which these methods have limited applicability owing to the lack of training data from target domains. We focus on the problem of single-source (visible) and multi-target (SWIR, long-range/remote, surveillance, and body-worn) face recognition task. We show through experiments that a good template generation algorithm becomes crucial as the complexity of the target domain increases. In this context, we introduce a template generation algorithm called Norm Pooling (and a variant known as Sparse Pooling) and show that it outperforms average pooling across different domains and networks, on the IARPA JANUS Benchmark Multi-domain Face (IJB-MDF) dataset.
Read more9/17/2024