From Modalities to Styles: Rethinking the Domain Gap in Heterogeneous Face Recognition

0

Sign in to get full access
Related work
Prior research has explored various approaches to addressing the domain gap in heterogeneous face recognition. Some studies have focused on developing domain-invariant feature representations, which aim to learn features that are insensitive to modality-specific variations. Other work has looked at using visualization techniques to better understand how CNN-based models adapt to changes in data domains. Multimodal adaptation methods have also been proposed, which leverage information from multiple modalities to improve unimodal model performance. Adapter-based approaches have shown promise in enabling effective cross-domain face recognition with limited training data. Domain rectifying adapters have also been explored to facilitate cross-domain few-shot learning.
While these existing methods have made progress in addressing the domain gap, the authors of the current paper argue that there are still opportunities to rethink the problem from a new perspective by focusing on style transfer between modalities.
Plain English Explanation
This research paper explores a different approach to tackling the challenge of heterogeneous face recognition, where the goal is to match faces captured in different modalities, such as photos and sketches.
Previous work has tried to address this problem by developing specialized feature representations that are robust to modality-specific variations, or by using techniques like multimodal adaptation and domain-adaptive methods. However, the authors of this paper believe there is room for a fresh perspective.
The key idea is to reframe the problem of heterogeneous face recognition not as a matter of bridging a "domain gap" between modalities, but rather as a style transfer challenge. The premise is that faces captured in different modalities can be viewed as having distinct "styles" - for example, a photo vs. a sketch have very different visual characteristics. So rather than trying to eliminate these style differences, the researchers propose embracing them and developing techniques to translate between these styles.
By treating the problem through the lens of style transfer, the authors believe new solutions can emerge that are more effective at handling the challenges of heterogeneous face recognition. The paper explores specific technical approaches along these lines and evaluates their performance, offering a novel perspective on this important computer vision challenge.
Technical Explanation
The paper proposes a new approach to heterogeneous face recognition that frames the problem as one of "style transfer" between modalities, rather than simply bridging a "domain gap."
The key technical components include:
-
Style Extractor: The authors develop a network module that can extract the "style" of a face image, capturing modality-specific visual characteristics.
-
Style Translator: A separate network component is trained to translate face images between different modalities by transferring the extracted style. This allows cross-modal face matching without the need to eliminate style differences.
-
Modality-Invariant Representation: In parallel, the model also learns a modality-invariant face representation that captures identity-relevant features regardless of the input style.
-
Joint Training: The style extractor, style translator, and modality-invariant representation are trained in an end-to-end fashion, leveraging both cross-modal and within-modal supervision signals.
Experiments on heterogeneous face recognition benchmarks demonstrate that this style-based approach outperforms prior domain-bridging methods, highlighting the potential benefits of reframing the problem in this way. The authors also analyze the learned style representations and translation capabilities to provide insights into the model's inner workings.
Critical Analysis
The paper presents a compelling new perspective on heterogeneous face recognition by shifting the focus from domain adaptation to style transfer. This reframing allows the model to explicitly account for and leverage the distinct visual characteristics of different modalities, rather than just trying to eliminate them.
One potential limitation is that the technique may struggle with highly divergent modalities, where the style gap is too large for effective translation. The authors acknowledge this and suggest that incorporating additional prior knowledge or architectural innovations may be needed to handle extreme cases.
Additionally, the style-based approach relies on the model's ability to accurately extract and translate the relevant style information. Further research may be needed to understand the practical limits of this approach and how it compares to alternative techniques in real-world deployment scenarios with diverse data and use cases.
Overall, the work offers a fresh take on a long-standing challenge in computer vision and biometrics. By encouraging readers to think critically about the problem framing, the paper opens up new avenues for exploration and innovation in the field of heterogeneous face recognition.
Conclusion
This research paper introduces a novel approach to heterogeneous face recognition that reframes the problem as one of style transfer between modalities, rather than simply bridging a domain gap.
The key technical contributions include a style extractor, style translator, and modality-invariant representation, which are trained jointly to enable cross-modal face matching while preserving style-specific characteristics. Experiments demonstrate the effectiveness of this style-based approach compared to prior domain adaptation methods.
While the technique shows promise, the authors acknowledge potential limitations and areas for further investigation, such as handling highly divergent modalities. Nevertheless, the paper offers a valuable new perspective that challenges the conventional framing of the heterogeneous face recognition problem, paving the way for further advancements in this important area of computer vision and biometrics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Modalities to Styles: Rethinking the Domain Gap in Heterogeneous Face Recognition
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) focuses on matching faces from different domains, for instance, thermal to visible images, making Face Recognition (FR) systems more versatile for challenging scenarios. However, the domain gap between these domains and the limited large-scale datasets in the target HFR modalities make it challenging to develop robust HFR models from scratch. In our work, we view different modalities as distinct styles and propose a method to modulate feature maps of the target modality to address the domain gap. We present a new Conditional Adaptive Instance Modulation (CAIM ) module that seamlessly fits into existing FR networks, turning them into HFR-ready systems. The CAIM block modulates intermediate feature maps, efficiently adapting to the style of the source modality and bridging the domain gap. Our method enables end-to-end training using a small set of paired samples. We extensively evaluate the proposed approach on various challenging HFR benchmarks, showing that it outperforms state-of-the-art methods. The source code and protocols for reproducing the findings will be made publicly available
Read more4/23/2024
0
Modality Agnostic Heterogeneous Face Recognition with Switch Style Modulators
Anjith George, Sebastien Marcel
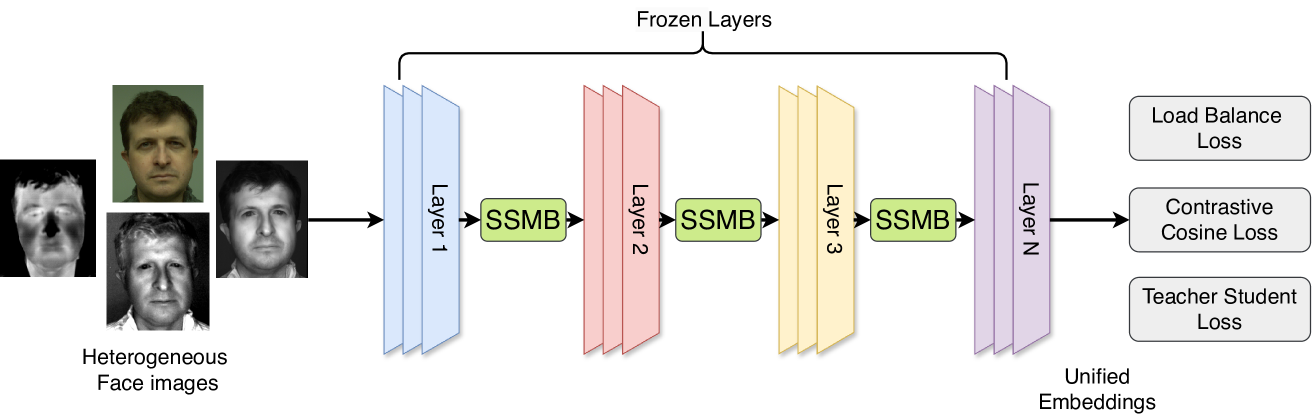
Heterogeneous Face Recognition (HFR) systems aim to enhance the capability of face recognition in challenging cross-modal authentication scenarios. However, the significant domain gap between the source and target modalities poses a considerable challenge for cross-domain matching. Existing literature primarily focuses on developing HFR approaches for specific pairs of face modalities, necessitating the explicit training of models for each source-target combination. In this work, we introduce a novel framework designed to train a modality-agnostic HFR method capable of handling multiple modalities during inference, all without explicit knowledge of the target modality labels. We achieve this by implementing a computationally efficient automatic routing mechanism called Switch Style Modulation Blocks (SSMB) that trains various domain expert modulators which transform the feature maps adaptively reducing the domain gap. Our proposed SSMB can be trained end-to-end and seamlessly integrated into pre-trained face recognition models, transforming them into modality-agnostic HFR models. We have performed extensive evaluations on HFR benchmark datasets to demonstrate its effectiveness. The source code and protocols will be made publicly available.
Read more7/12/2024

0
Heterogeneous Face Recognition Using Domain Invariant Units
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) aims to expand the applicability of Face Recognition (FR) systems to challenging scenarios, enabling the matching of face images across different domains, such as matching thermal images to visible spectra. However, the development of HFR systems is challenging because of the significant domain gap between modalities and the lack of availability of large-scale paired multi-channel data. In this work, we leverage a pretrained face recognition model as a teacher network to learn domaininvariant network layers called Domain-Invariant Units (DIU) to reduce the domain gap. The proposed DIU can be trained effectively even with a limited amount of paired training data, in a contrastive distillation framework. This proposed approach has the potential to enhance pretrained models, making them more adaptable to a wider range of variations in data. We extensively evaluate our approach on multiple challenging benchmarks, demonstrating superior performance compared to state-of-the-art methods.
Read more4/23/2024
👁️
0
Learning with Alignments: Tackling the Inter- and Intra-domain Shifts for Cross-multidomain Facial Expression Recognition
Yuxiang Yang, Lu Wen, Xinyi Zeng, Yuanyuan Xu, Xi Wu, Jiliu Zhou, Yan Wang
Facial Expression Recognition (FER) holds significant importance in human-computer interactions. Existing cross-domain FER methods often transfer knowledge solely from a single labeled source domain to an unlabeled target domain, neglecting the comprehensive information across multiple sources. Nevertheless, cross-multidomain FER (CMFER) is very challenging for (i) the inherent inter-domain shifts across multiple domains and (ii) the intra-domain shifts stemming from the ambiguous expressions and low inter-class distinctions. In this paper, we propose a novel Learning with Alignments CMFER framework, named LA-CMFER, to handle both inter- and intra-domain shifts. Specifically, LA-CMFER is constructed with a global branch and a local branch to extract features from the full images and local subtle expressions, respectively. Based on this, LA-CMFER presents a dual-level inter-domain alignment method to force the model to prioritize hard-to-align samples in knowledge transfer at a sample level while gradually generating a well-clustered feature space with the guidance of class attributes at a cluster level, thus narrowing the inter-domain shifts. To address the intra-domain shifts, LA-CMFER introduces a multi-view intra-domain alignment method with a multi-view clustering consistency constraint where a prediction similarity matrix is built to pursue consistency between the global and local views, thus refining pseudo labels and eliminating latent noise. Extensive experiments on six benchmark datasets have validated the superiority of our LA-CMFER.
Read more7/31/2024