Modality Agnostic Heterogeneous Face Recognition with Switch Style Modulators

0
Sign in to get full access
Overview
- This paper presents a modality-agnostic heterogeneous face recognition system that uses switch-style modulators to handle different data modalities.
- The proposed approach aims to address the domain gap between heterogeneous face modalities, such as visible and infrared images, without requiring modality-specific training.
- The system utilizes a shared backbone network with modality-specific switch-style modulators to extract and combine task-relevant features from different input types.
Plain English Explanation
The paper describes a way to build a face recognition system that can work with different types of face images, like visible light photos and infrared (heat) images, without needing to train separate models for each type. This is helpful because often face recognition systems struggle when presented with data that is very different from what they were trained on.
The key idea is to use a single main neural network as the backbone, but then attach special "modulator" components that can adjust how the network processes each different type of input data. These modulators essentially learn to extract the most relevant features from each modality, and then combine them in a way that allows the overall system to work well across all the different input types.
This modular design means the system is "modality agnostic" - it doesn't care what type of face image you give it, it can handle them all. This makes the system more flexible and robust compared to having separate models for visible and infrared faces, for example. The authors show this approach outperforms previous methods on several heterogeneous face recognition benchmarks.
Technical Explanation
The paper introduces a Modality Agnostic Heterogeneous Face Recognition with Switch Style Modulators system that can effectively handle different face modalities, such as visible and infrared images, without needing modality-specific training.
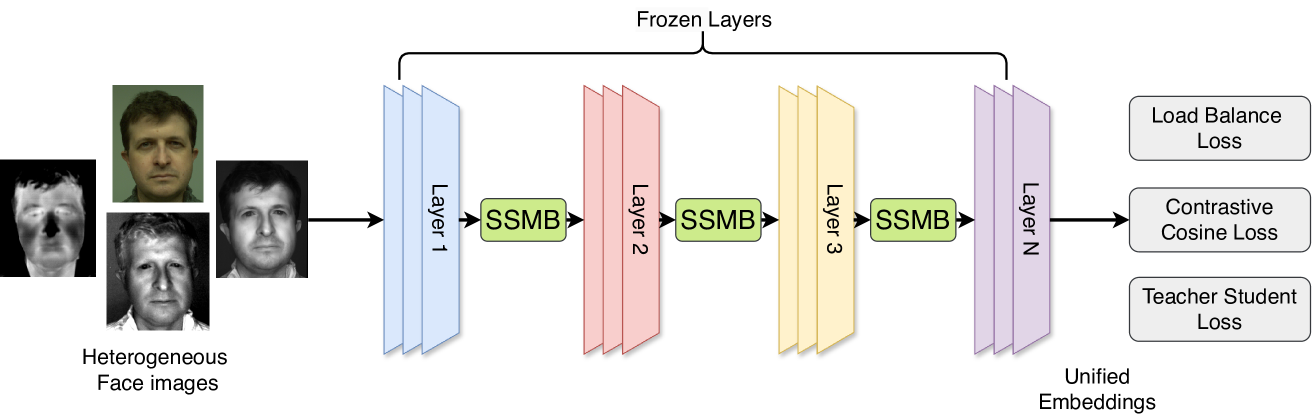
The proposed architecture consists of a shared backbone network with modality-specific switch-style modulators that are responsible for extracting relevant features from each input type and combining them in a way that allows for effective cross-modal face recognition.
The switch-style modulators learn to adaptively modulate the shared representation based on the input modality, enabling the system to handle the domain gap between heterogeneous face data sources. This modular design allows the backbone network to remain generic while the modulators specialize in processing different modalities.
The authors evaluate their approach on several heterogeneous face recognition benchmarks and demonstrate its superiority over previous methods that rely on modality-specific training or complex domain adaptation techniques.
Critical Analysis
The paper presents a compelling approach to address the challenge of heterogeneous face recognition, which is an important problem in real-world applications where face data can come from diverse sources. The authors' use of switch-style modulators is a novel and interesting solution to handle the domain gap between different face modalities.
One potential limitation of the approach is that it may require additional training data and compute resources to learn the modality-specific modulators, compared to a single-modality system. The authors acknowledge this tradeoff and suggest that the increased flexibility and robustness of their modality-agnostic system outweigh the added complexity.
It would also be valuable to see the performance of the proposed method on an even wider range of modalities, such as 3D face scans or low-resolution images, to further demonstrate its generalization capabilities. Additionally, exploring the interpretability of the modulator components and their learned behaviors could provide deeper insights into the inner workings of the system.
Overall, the paper presents a well-designed and promising solution for heterogeneous face recognition, which has significant practical implications for deploying face recognition systems in real-world scenarios with diverse data sources.
Conclusion
This paper introduces a modality-agnostic heterogeneous face recognition system that uses switch-style modulators to effectively handle different face data modalities, such as visible and infrared images, without requiring modality-specific training. The key innovation is the use of a shared backbone network with specialized modulators that learn to extract and combine relevant features from each input type.
The authors demonstrate the superiority of their approach over previous methods on several benchmark tasks, highlighting the flexibility and robustness of the proposed system. This work has important implications for building face recognition systems that can reliably operate in a wide range of real-world scenarios with diverse data sources, which is a crucial requirement for many practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Modality Agnostic Heterogeneous Face Recognition with Switch Style Modulators
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) systems aim to enhance the capability of face recognition in challenging cross-modal authentication scenarios. However, the significant domain gap between the source and target modalities poses a considerable challenge for cross-domain matching. Existing literature primarily focuses on developing HFR approaches for specific pairs of face modalities, necessitating the explicit training of models for each source-target combination. In this work, we introduce a novel framework designed to train a modality-agnostic HFR method capable of handling multiple modalities during inference, all without explicit knowledge of the target modality labels. We achieve this by implementing a computationally efficient automatic routing mechanism called Switch Style Modulation Blocks (SSMB) that trains various domain expert modulators which transform the feature maps adaptively reducing the domain gap. Our proposed SSMB can be trained end-to-end and seamlessly integrated into pre-trained face recognition models, transforming them into modality-agnostic HFR models. We have performed extensive evaluations on HFR benchmark datasets to demonstrate its effectiveness. The source code and protocols will be made publicly available.
Read more7/12/2024

0
From Modalities to Styles: Rethinking the Domain Gap in Heterogeneous Face Recognition
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) focuses on matching faces from different domains, for instance, thermal to visible images, making Face Recognition (FR) systems more versatile for challenging scenarios. However, the domain gap between these domains and the limited large-scale datasets in the target HFR modalities make it challenging to develop robust HFR models from scratch. In our work, we view different modalities as distinct styles and propose a method to modulate feature maps of the target modality to address the domain gap. We present a new Conditional Adaptive Instance Modulation (CAIM ) module that seamlessly fits into existing FR networks, turning them into HFR-ready systems. The CAIM block modulates intermediate feature maps, efficiently adapting to the style of the source modality and bridging the domain gap. Our method enables end-to-end training using a small set of paired samples. We extensively evaluate the proposed approach on various challenging HFR benchmarks, showing that it outperforms state-of-the-art methods. The source code and protocols for reproducing the findings will be made publicly available
Read more4/23/2024

0
Heterogeneous Face Recognition Using Domain Invariant Units
Anjith George, Sebastien Marcel
Heterogeneous Face Recognition (HFR) aims to expand the applicability of Face Recognition (FR) systems to challenging scenarios, enabling the matching of face images across different domains, such as matching thermal images to visible spectra. However, the development of HFR systems is challenging because of the significant domain gap between modalities and the lack of availability of large-scale paired multi-channel data. In this work, we leverage a pretrained face recognition model as a teacher network to learn domaininvariant network layers called Domain-Invariant Units (DIU) to reduce the domain gap. The proposed DIU can be trained effectively even with a limited amount of paired training data, in a contrastive distillation framework. This proposed approach has the potential to enhance pretrained models, making them more adaptable to a wider range of variations in data. We extensively evaluate our approach on multiple challenging benchmarks, demonstrating superior performance compared to state-of-the-art methods.
Read more4/23/2024
0
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
Read more4/16/2024