HiddenSpeaker: Generate Imperceptible Unlearnable Audios for Speaker Verification System

0
Sign in to get full access
Overview
- The paper introduces a new method called "HiddenSpeaker" that can generate imperceptible yet unlearnable audio samples for speaker verification systems.
- The goal is to protect speaker privacy by creating audio samples that can evade speaker verification models without being noticeable to human listeners.
- The method leverages adversarial training and optimization techniques to generate these imperceptible yet unlearnable audio samples.
Plain English Explanation
Privacy Protection for Speaker Verification Speaker verification systems are used to authenticate a person's identity based on their voice. However, these systems can pose a privacy risk by capturing and storing sensitive voice data. The HiddenSpeaker method addresses this by generating audio samples that can fool the verification system without being heard by humans.
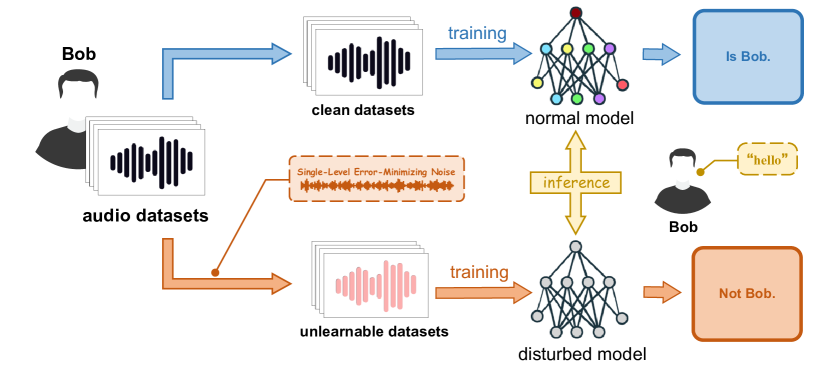
Imperceptible, Unlearnable Audios The key idea is to create audio samples that sound normal to people but are "unlearnable" by the speaker verification model. This means the model will not be able to correctly identify the speaker, even though the audio is indistinguishable from normal speech to human listeners.
This is achieved through a specialized training process that optimizes the audio samples to be imperceptible while also confusing the verification model. The end result is audio that protects privacy without compromising usability.
Potential Applications The HiddenSpeaker method could be used to protect user privacy in various voice-based applications, such as voice assistants, speaker identification, and speech synthesis. It could also help improve the robustness of speaker verification models by exposing them to these types of adversarial examples during training.
Technical Explanation
The HiddenSpeaker method consists of two main components:
-
Adversarial Audio Generation: The researchers use an optimization-based approach to generate audio samples that are imperceptible to humans but can fool the speaker verification model. This involves defining a perceptual similarity metric to ensure the generated audio sounds natural, while also incorporating a loss function to make the samples "unlearnable" by the verification model.
-
Unlearnable Audio Training: The researchers then use these adversarially generated audio samples to train the speaker verification model. This exposes the model to a diverse set of examples that are challenging to learn, helping to improve its robustness against these types of attacks.
The paper demonstrates the effectiveness of HiddenSpeaker through experiments on various speaker verification datasets. The results show that the generated audio samples can significantly degrade the performance of state-of-the-art speaker verification models while remaining imperceptible to human listeners.
Critical Analysis
The HiddenSpeaker approach presents an interesting solution to the privacy challenges of speaker verification systems. By generating imperceptible yet unlearnable audio samples, it offers a way to protect user privacy without compromising the usability of these systems.
However, the paper does not fully address some potential limitations and concerns:
-
Generalization Capabilities: The paper focuses on evaluating HiddenSpeaker on specific speaker verification datasets and models. It's unclear how well the method would generalize to other verification systems or real-world deployment scenarios.
-
Robustness to Countermeasures: The paper does not consider how speaker verification models might adapt to defend against these types of adversarial attacks. More research is needed to understand the long-term viability of this approach.
-
Ethical Considerations: While the goal of protecting user privacy is noble, the use of adversarial examples raises ethical concerns. Potential misuse of this technology, such as deceiving verification systems for malicious purposes, should be carefully considered.
-
Certification of Speaker Recognition Models to Additive Perturbations: The HiddenSpeaker approach could potentially be combined with techniques for certifying the robustness of speaker verification models to better understand the security guarantees of this approach.
Overall, the HiddenSpeaker method is a promising step towards balancing privacy and usability in speaker verification systems, but further research is needed to address its limitations and potential misuse.
Conclusion
The HiddenSpeaker paper introduces a novel approach to generating imperceptible yet unlearnable audio samples for speaker verification systems. This technique aims to protect user privacy by creating adversarial examples that can fool the verification models without being noticeable to human listeners.
The key contributions of this work include the optimization-based method for generating these imperceptible yet unlearnable audio samples, as well as the proposed training approach to improve the robustness of speaker verification models. The experimental results demonstrate the effectiveness of HiddenSpeaker in degrading the performance of state-of-the-art speaker verification systems.
While the HiddenSpeaker method shows promise, there are still open challenges and ethical considerations that require further research. Nonetheless, this work represents an important step towards balancing the privacy and usability of speaker verification technologies, with potential applications in voice assistants, speaker identification, and speech synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HiddenSpeaker: Generate Imperceptible Unlearnable Audios for Speaker Verification System
Zhisheng Zhang, Pengyang Huang
In recent years, the remarkable advancements in deep neural networks have brought tremendous convenience. However, the training process of a highly effective model necessitates a substantial quantity of samples, which brings huge potential threats, like unauthorized exploitation with privacy leakage. In response, we propose a framework named HiddenSpeaker, embedding imperceptible perturbations within the training speech samples and rendering them unlearnable for deep-learning-based speaker verification systems that employ large-scale speakers for efficient training. The HiddenSpeaker utilizes a simplified error-minimizing method named Single-Level Error-Minimizing (SLEM) to generate specific and effective perturbations. Additionally, a hybrid objective function is employed for human perceptual optimization, ensuring the perturbation is indistinguishable from human listeners. We conduct extensive experiments on multiple state-of-the-art (SOTA) models in the speaker verification domain to evaluate HiddenSpeaker. Our results demonstrate that HiddenSpeaker not only deceives the model with unlearnable samples but also enhances the imperceptibility of the perturbations, showcasing strong transferability across different models.
Read more5/28/2024

0
Attentive Merging of Hidden Embeddings from Pre-trained Speech Model for Anti-spoofing Detection
Zihan Pan, Tianchi Liu, Hardik B. Sailor, Qiongqiong Wang
Self-supervised learning (SSL) speech representation models, trained on large speech corpora, have demonstrated effectiveness in extracting hierarchical speech embeddings through multiple transformer layers. However, the behavior of these embeddings in specific tasks remains uncertain. This paper investigates the multi-layer behavior of the WavLM model in anti-spoofing and proposes an attentive merging method to leverage the hierarchical hidden embeddings. Results demonstrate the feasibility of fine-tuning WavLM to achieve the best equal error rate (EER) of 0.65%, 3.50%, and 3.19% on the ASVspoof 2019LA, 2021LA, and 2021DF evaluation sets, respectively. Notably, We find that the early hidden transformer layers of the WavLM large model contribute significantly to anti-spoofing task, enabling computational efficiency by utilizing a partial pre-trained model.
Read more6/18/2024
0
Personalized Speech Enhancement Without a Separate Speaker Embedding Model
Tanel Parnamaa, Ando Saabas
Personalized speech enhancement (PSE) models can improve the audio quality of teleconferencing systems by adapting to the characteristics of a speaker's voice. However, most existing methods require a separate speaker embedding model to extract a vector representation of the speaker from enrollment audio, which adds complexity to the training and deployment process. We propose to use the internal representation of the PSE model itself as the speaker embedding, thereby avoiding the need for a separate model. We show that our approach performs equally well or better than the standard method of using a pre-trained speaker embedding model on noise suppression and echo cancellation tasks. Moreover, our approach surpasses the ICASSP 2023 Deep Noise Suppression Challenge winner by 0.15 in Mean Opinion Score.
Read more6/17/2024

0
Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
Rui Wang, Liping Chen, Kong AiK Lee, Zhen-Hua Ling
Voice anonymization has been developed as a technique for preserving privacy by replacing the speaker's voice in a speech signal with that of a pseudo-speaker, thereby obscuring the original voice attributes from machine recognition and human perception. In this paper, we focus on altering the voice attributes against machine recognition while retaining human perception. We referred to this as the asynchronous voice anonymization. To this end, a speech generation framework incorporating a speaker disentanglement mechanism is employed to generate the anonymized speech. The speaker attributes are altered through adversarial perturbation applied on the speaker embedding, while human perception is preserved by controlling the intensity of perturbation. Experiments conducted on the LibriSpeech dataset showed that the speaker attributes were obscured with their human perception preserved for 60.71% of the processed utterances.
Read more6/14/2024