Look Once to Hear: Target Speech Hearing with Noisy Examples
2405.06289
1
0
🗣️
Abstract
In crowded settings, the human brain can focus on speech from a target speaker, given prior knowledge of how they sound. We introduce a novel intelligent hearable system that achieves this capability, enabling target speech hearing to ignore all interfering speech and noise, but the target speaker. A naive approach is to require a clean speech example to enroll the target speaker. This is however not well aligned with the hearable application domain since obtaining a clean example is challenging in real world scenarios, creating a unique user interface problem. We present the first enrollment interface where the wearer looks at the target speaker for a few seconds to capture a single, short, highly noisy, binaural example of the target speaker. This noisy example is used for enrollment and subsequent speech extraction in the presence of interfering speakers and noise. Our system achieves a signal quality improvement of 7.01 dB using less than 5 seconds of noisy enrollment audio and can process 8 ms of audio chunks in 6.24 ms on an embedded CPU. Our user studies demonstrate generalization to real-world static and mobile speakers in previously unseen indoor and outdoor multipath environments. Finally, our enrollment interface for noisy examples does not cause performance degradation compared to clean examples, while being convenient and user-friendly. Taking a step back, this paper takes an important step towards enhancing the human auditory perception with artificial intelligence. We provide code and data at: https://github.com/vb000/LookOnceToHear.
Create account to get full access
Overview
- This paper introduces a novel intelligent hearable system that can isolate and enhance a target speaker's voice in crowded, noisy environments.
- The system uses a short, noisy audio example of the target speaker's voice, obtained by having the user look at them for a few seconds, to train the system.
- This is a significant advancement over previous approaches that required a clean speech sample for enrollment, which is challenging in real-world scenarios.
- The system achieves a 7.01 dB signal quality improvement using less than 5 seconds of noisy enrollment audio and can process audio in real-time on an embedded CPU.
- The research demonstrates the system's generalization to various indoor and outdoor environments with static and mobile speakers.
- This work represents an important step towards enhancing human auditory perception using artificial intelligence.
Plain English Explanation
In crowded situations, like a noisy party or a busy street, it can be difficult for the human brain to focus on and understand the speech of a particular person you're talking to, especially if there are other people talking around you. This new intelligent hearable system solves this problem by allowing you to isolate and enhance the voice of the person you're trying to listen to, while filtering out all the other voices and background noise.
The key innovation is that the system only needs a short, noisy sample of the target speaker's voice to get started. You simply look at the person you want to focus on for a few seconds, and the system captures that brief, imperfect audio example. It then uses that sample to learn the characteristics of that person's voice and can subsequently extract and boost their speech, even in the midst of a crowd.
This is much more convenient than previous approaches, which required a clean, high-quality recording of the target speaker's voice to set up the system. Obtaining such a clean sample is often difficult in real-world, noisy environments. By using a quick, messy sample instead, this new system is much easier to use in practical situations.
The system is also able to process the audio in real-time, enhancing the target speaker's voice with a 7 dB improvement in signal quality. And it works equally well for static speakers and those who are moving around, in both indoor and outdoor settings.
Overall, this research represents an important step forward in using artificial intelligence to augment human hearing and attention, making it easier for people to focus on the conversations that matter to them, even in chaotic surroundings.
Technical Explanation
The paper presents a novel intelligent hearable system that can isolate and enhance a target speaker's voice in the presence of interfering speech and background noise. The key innovation is the system's enrollment interface, which only requires a short, highly noisy, binaural audio example of the target speaker's voice, obtained by having the user look at them for a few seconds.
Previous approaches required a clean speech sample for enrollment, which is challenging to obtain in real-world scenarios. The researchers show that their system can achieve a 7.01 dB signal quality improvement using less than 5 seconds of noisy enrollment audio, and can process 8 ms audio chunks in 6.24 ms on an embedded CPU, enabling real-time performance.
The system's architecture leverages multi-channel speech enhancement techniques and a novel target speaker extraction model. User studies demonstrate the system's generalization to various indoor and outdoor environments with static and mobile speakers.
Importantly, the researchers found that their noisy enrollment interface does not degrade performance compared to using clean examples, while being more convenient and user-friendly. This represents a significant advancement over prior work, which required carefully curated speech samples for enrollment.
Critical Analysis
The paper makes a compelling case for the practical benefits of this intelligent hearable system, particularly its ability to work with noisy, real-world enrollment samples. This is a significant step forward compared to previous approaches that relied on clean speech examples, which are often difficult to obtain in realistic scenarios.
However, the paper does not delve into potential limitations or areas for further research. For example, it would be interesting to understand how the system performs with a diverse range of speakers, accents, and languages, as well as its robustness to different types and levels of background noise and interference.
Additionally, the paper does not address potential privacy concerns or ethical considerations around the use of such a system, particularly in sensitive situations where individuals may not want their speech to be isolated and enhanced without their knowledge or consent.
Further research could also explore how this technology could be combined with other advancements in speech processing and enhancement, such as universal speaker adaptation or multi-lingual few-shot learning, to create even more robust and versatile intelligent hearing systems.
Conclusion
This paper introduces a novel intelligent hearable system that can effectively isolate and enhance a target speaker's voice in the presence of interfering speech and background noise. The key innovation is the system's ability to work with a short, noisy audio example of the target speaker's voice, obtained by having the user look at them for a few seconds.
This represents a significant advancement over previous approaches that required clean speech samples for enrollment, which are often challenging to obtain in real-world scenarios. The system's performance, real-time processing capabilities, and generalization to various environments demonstrate its potential to enhance human auditory perception and attention in crowded, noisy settings.
While the paper does not address potential limitations or ethical considerations, this research represents an important step forward in the field of intelligent audio processing and its application to improving human-centric experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
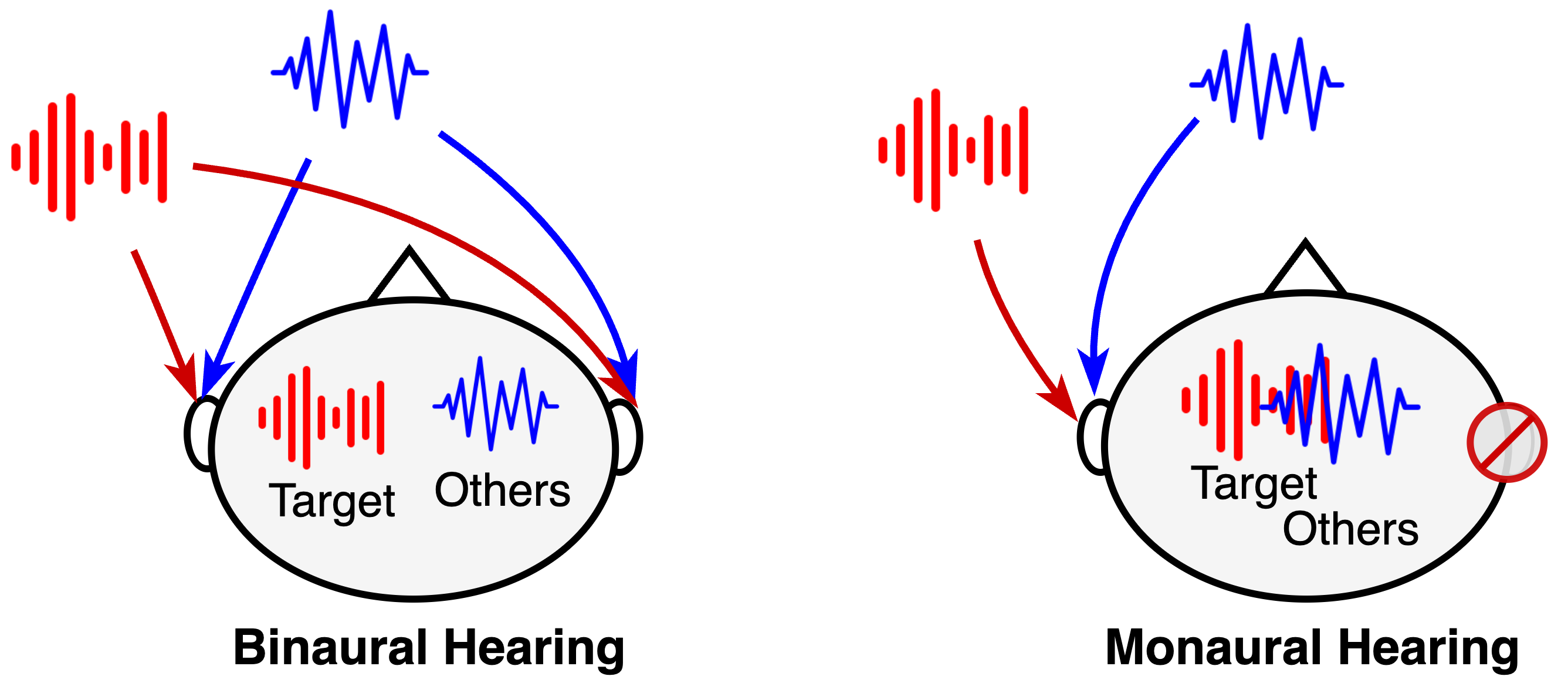
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
0
0
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
6/19/2024
💬
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Xiaofei Wang, Sefik Emre Eskimez, Manthan Thakker, Hemin Yang, Zirun Zhu, Min Tang, Yufei Xia, Jinzhu Li, Sheng Zhao, Jinyu Li, Naoyuki Kanda
0
0
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
6/11/2024
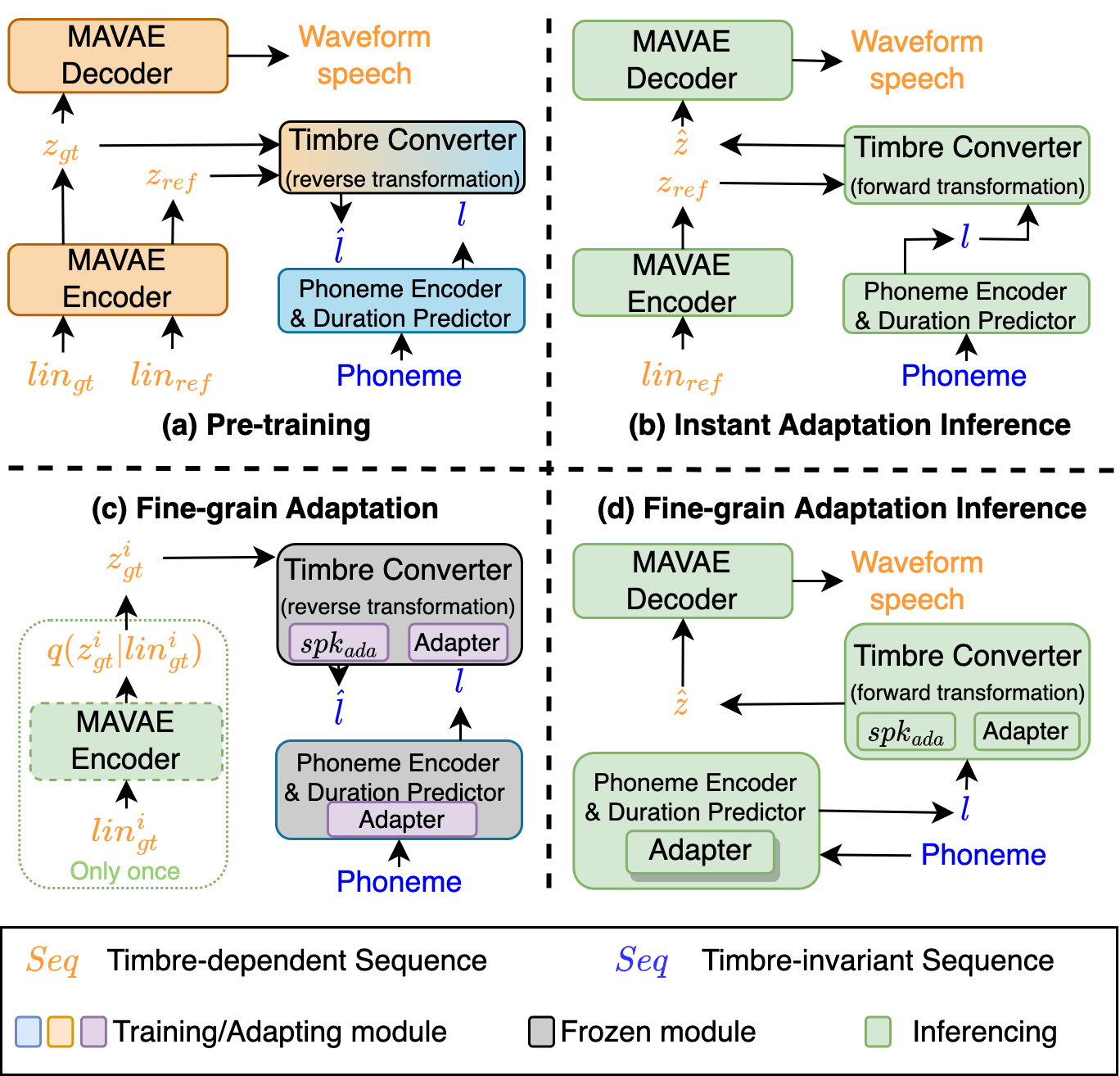
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024
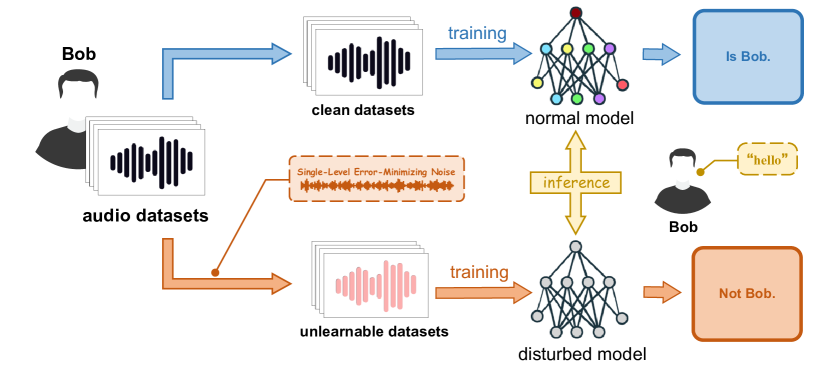
HiddenSpeaker: Generate Imperceptible Unlearnable Audios for Speaker Verification System
Zhisheng Zhang, Pengyang Huang
0
0
In recent years, the remarkable advancements in deep neural networks have brought tremendous convenience. However, the training process of a highly effective model necessitates a substantial quantity of samples, which brings huge potential threats, like unauthorized exploitation with privacy leakage. In response, we propose a framework named HiddenSpeaker, embedding imperceptible perturbations within the training speech samples and rendering them unlearnable for deep-learning-based speaker verification systems that employ large-scale speakers for efficient training. The HiddenSpeaker utilizes a simplified error-minimizing method named Single-Level Error-Minimizing (SLEM) to generate specific and effective perturbations. Additionally, a hybrid objective function is employed for human perceptual optimization, ensuring the perturbation is indistinguishable from human listeners. We conduct extensive experiments on multiple state-of-the-art (SOTA) models in the speaker verification domain to evaluate HiddenSpeaker. Our results demonstrate that HiddenSpeaker not only deceives the model with unlearnable samples but also enhances the imperceptibility of the perturbations, showcasing strong transferability across different models.
5/28/2024