HiDiff: Hybrid Diffusion Framework for Medical Image Segmentation

0

Sign in to get full access
Overview
- A novel hybrid diffusion framework called HiDiff for medical image segmentation
- Combines transformer-based models and diffusion models to leverage their respective strengths
- Achieves state-of-the-art performance on several medical image segmentation benchmarks
Plain English Explanation
The research paper introduces a new approach called HiDiff for segmenting medical images. Medical image segmentation is the process of identifying and separating different structures or regions within medical images, such as organs or tumors.
HiDiff combines two powerful machine learning techniques - transformer-based models and diffusion models. Transformer-based models are known for their ability to capture complex contextual relationships in data, while diffusion models excel at generating high-quality, realistic-looking images. By bringing these two approaches together, HiDiff can leverage the strengths of each to achieve better performance on medical image segmentation tasks.
The researchers tested HiDiff on several standard medical image segmentation benchmarks and found that it outperformed other state-of-the-art methods. This suggests that the hybrid approach of combining transformers and diffusion models can be a powerful tool for analyzing and understanding medical images, with potential applications in areas like disease diagnosis and treatment planning.
Technical Explanation
The HiDiff framework consists of two main components: a transformer-based encoder and a diffusion-based decoder. The encoder takes a medical image as input and generates a latent representation that captures the relevant features and contextual information. The decoder then uses this latent representation to generate a segmented output image, where each pixel is assigned a label corresponding to a specific anatomical structure or region of interest.
The key innovation in HiDiff is the way it integrates the transformer and diffusion components. The transformer encoder leverages the ability of transformer models to model long-range dependencies and capture the complex relationships between different parts of the medical image. The diffusion decoder, on the other hand, is well-suited for generating high-quality, realistic-looking segmented outputs by iteratively refining the image based on the learned latent representation.
The researchers trained and evaluated HiDiff on several medical image segmentation datasets, including CT scans of the abdomen and MRI scans of the brain. They compared the performance of HiDiff to other state-of-the-art segmentation methods, such as FreeSegDiff and DiffSeg, and found that HiDiff achieved significantly better results in terms of segmentation accuracy and other relevant metrics.
Critical Analysis
The paper provides a thorough evaluation of the HiDiff framework and its performance on various medical image segmentation tasks. The researchers have done a commendable job of demonstrating the effectiveness of their hybrid approach and comparing it to other state-of-the-art methods.
However, the paper does not address some potential limitations or areas for further research. For example, the performance of HiDiff on smaller or more challenging medical image datasets is not explored, which could be an important consideration for real-world applications. Additionally, the computational complexity and training time of the HiDiff model are not discussed, which could be important factors when considering the practical deployment of the system.
It would also be interesting to see how HiDiff performs on other medical imaging modalities, such as ultrasound or digital pathology images, and whether the hybrid approach can be generalized to other medical image analysis tasks beyond segmentation, such as disease detection or classification.
Conclusion
The HiDiff framework presented in this paper is a promising approach to medical image segmentation that combines the strengths of transformer-based and diffusion-based models. The researchers have demonstrated that this hybrid approach can achieve state-of-the-art performance on several benchmark datasets, suggesting that it could be a valuable tool for healthcare professionals in areas like disease diagnosis and treatment planning.
While the paper provides a solid technical foundation, further research is needed to address potential limitations and explore the broader applicability of the HiDiff framework. Overall, this work represents an exciting step forward in the field of medical image analysis and highlights the potential of combining different deep learning techniques to tackle complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HiDiff: Hybrid Diffusion Framework for Medical Image Segmentation
Tao Chen, Chenhui Wang, Zhihao Chen, Yiming Lei, Hongming Shan
Medical image segmentation has been significantly advanced with the rapid development of deep learning (DL) techniques. Existing DL-based segmentation models are typically discriminative; i.e., they aim to learn a mapping from the input image to segmentation masks. However, these discriminative methods neglect the underlying data distribution and intrinsic class characteristics, suffering from unstable feature space. In this work, we propose to complement discriminative segmentation methods with the knowledge of underlying data distribution from generative models. To that end, we propose a novel hybrid diffusion framework for medical image segmentation, termed HiDiff, which can synergize the strengths of existing discriminative segmentation models and new generative diffusion models. HiDiff comprises two key components: discriminative segmentor and diffusion refiner. First, we utilize any conventional trained segmentation models as discriminative segmentor, which can provide a segmentation mask prior for diffusion refiner. Second, we propose a novel binary Bernoulli diffusion model (BBDM) as the diffusion refiner, which can effectively, efficiently, and interactively refine the segmentation mask by modeling the underlying data distribution. Third, we train the segmentor and BBDM in an alternate-collaborative manner to mutually boost each other. Extensive experimental results on abdomen organ, brain tumor, polyps, and retinal vessels segmentation datasets, covering four widely-used modalities, demonstrate the superior performance of HiDiff over existing medical segmentation algorithms, including the state-of-the-art transformer- and diffusion-based ones. In addition, HiDiff excels at segmenting small objects and generalizing to new datasets. Source codes are made available at https://github.com/takimailto/HiDiff.
Read more7/8/2024
0
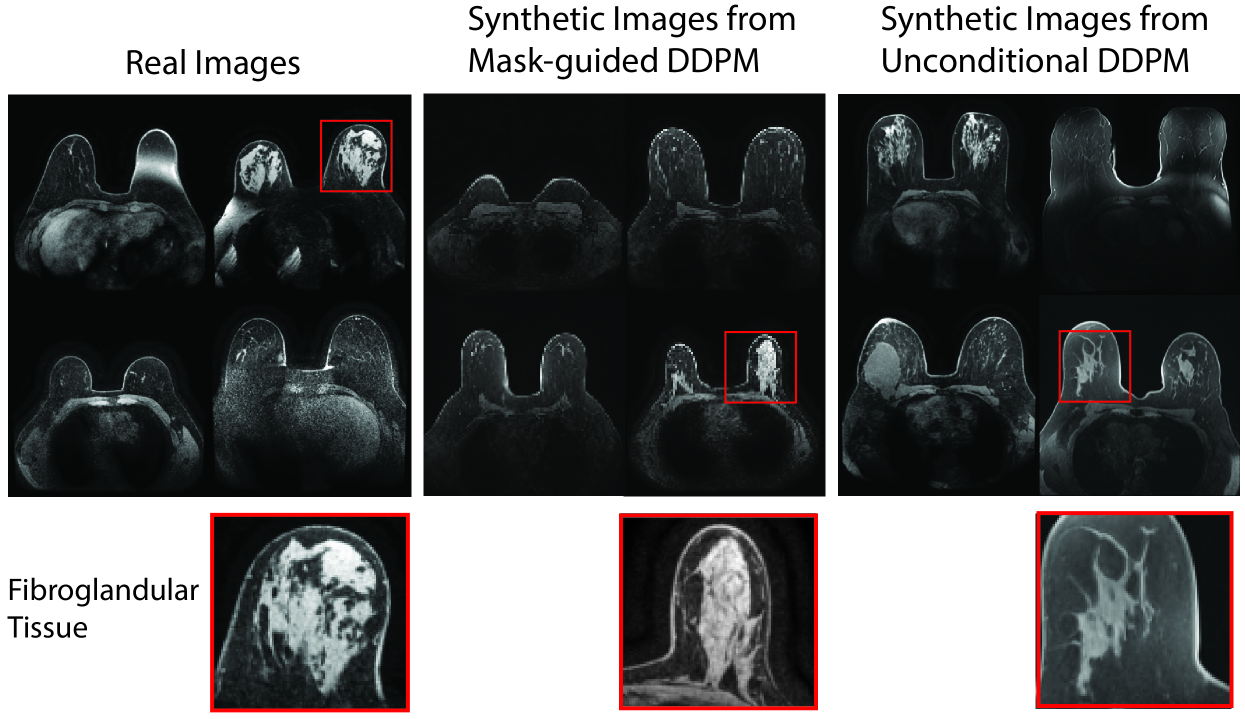
Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
Nicholas Konz, Yuwen Chen, Haoyu Dong, Maciej A. Mazurowski
Diffusion models have enabled remarkably high-quality medical image generation, yet it is challenging to enforce anatomical constraints in generated images. To this end, we propose a diffusion model-based method that supports anatomically-controllable medical image generation, by following a multi-class anatomical segmentation mask at each sampling step. We additionally introduce a random mask ablation training algorithm to enable conditioning on a selected combination of anatomical constraints while allowing flexibility in other anatomical areas. We compare our method (SegGuidedDiff) to existing methods on breast MRI and abdominal/neck-to-pelvis CT datasets with a wide range of anatomical objects. Results show that our method reaches a new state-of-the-art in the faithfulness of generated images to input anatomical masks on both datasets, and is on par for general anatomical realism. Finally, our model also enjoys the extra benefit of being able to adjust the anatomical similarity of generated images to real images of choice through interpolation in its latent space. SegGuidedDiff has many applications, including cross-modality translation, and the generation of paired or counterfactual data. Our code is available at https://github.com/mazurowski-lab/segmentation-guided-diffusion.
Read more6/21/2024
📈
0
DiffSeg: A Segmentation Model for Skin Lesions Based on Diffusion Difference
Zhihao Shuai, Yinan Chen, Shunqiang Mao, Yihan Zho, Xiaohong Zhang
Weakly supervised medical image segmentation (MIS) using generative models is crucial for clinical diagnosis. However, the accuracy of the segmentation results is often limited by insufficient supervision and the complex nature of medical imaging. Existing models also only provide a single outcome, which does not allow for the measurement of uncertainty. In this paper, we introduce DiffSeg, a segmentation model for skin lesions based on diffusion difference which exploits diffusion model principles to ex-tract noise-based features from images with diverse semantic information. By discerning difference between these noise features, the model identifies diseased areas. Moreover, its multi-output capability mimics doctors' annotation behavior, facilitating the visualization of segmentation result consistency and ambiguity. Additionally, it quantifies output uncertainty using Generalized Energy Distance (GED), aiding interpretability and decision-making for physicians. Finally, the model integrates outputs through the Dense Conditional Random Field (DenseCRF) algorithm to refine the segmentation boundaries by considering inter-pixel correlations, which improves the accuracy and optimizes the segmentation results. We demonstrate the effectiveness of DiffSeg on the ISIC 2018 Challenge dataset, outperforming state-of-the-art U-Net-based methods.
Read more4/26/2024
📉
0
Re-DiffiNet: Modeling discrepancies in tumor segmentation using diffusion models
Tianyi Ren, Abhishek Sharma, Juampablo Heras Rivera, Harshitha Rebala, Ethan Honey, Agamdeep Chopra, Jacob Ruzevick, Mehmet Kurt
Identification of tumor margins is essential for surgical decision-making for glioblastoma patients and provides reliable assistance for neurosurgeons. Despite improvements in deep learning architectures for tumor segmentation over the years, creating a fully autonomous system suitable for clinical floors remains a formidable challenge because the model predictions have not yet reached the desired level of accuracy and generalizability for clinical applications. Generative modeling techniques have seen significant improvements in recent times. Specifically, Generative Adversarial Networks (GANs) and Denoising-diffusion-based models (DDPMs) have been used to generate higher-quality images with fewer artifacts and finer attributes. In this work, we introduce a framework called Re-Diffinet for modeling the discrepancy between the outputs of a segmentation model like U-Net and the ground truth, using DDPMs. By explicitly modeling the discrepancy, the results show an average improvement of 0.55% in the Dice score and 16.28% in HD95 from cross-validation over 5-folds, compared to the state-of-the-art U-Net segmentation model.
Read more4/11/2024