Hierarchical Indexing for Retrieval-Augmented Opinion Summarization

0

Sign in to get full access
Overview
- This paper introduces a hierarchical indexing approach to improve retrieval-augmented opinion summarization.
- The proposed method leverages a hierarchical structure to organize and retrieve relevant information for opinion summarization tasks.
- The authors evaluate their approach on benchmark datasets and demonstrate improvements over state-of-the-art opinion summarization models.
Plain English Explanation
Opinion summarization is the task of automatically generating concise summaries that capture the key opinions and sentiments expressed in a collection of text, such as product reviews or social media posts. This paper presents a novel technique called "Hierarchical Indexing for Retrieval-Augmented Opinion Summarization" (HIRO) that aims to improve the performance of opinion summarization systems.
The core idea behind HIRO is to organize the information used for summarization in a hierarchical manner. Instead of treating all the text as a flat collection, HIRO structures the information into a tree-like hierarchy. This allows the system to more efficiently retrieve the most relevant snippets of text when generating a summary. For example, the hierarchy might group reviews by product category, then by specific product, and finally by individual reviewer comments.
By leveraging this hierarchical structure, the HIRO system can better understand the context and relationships between different opinions, leading to more coherent and comprehensive summaries. The authors demonstrate that HIRO outperforms other state-of-the-art opinion summarization approaches on standard benchmark datasets, highlighting the benefits of their hierarchical indexing approach.
Technical Explanation
The HIRO system proposed in this paper aims to improve retrieval-augmented opinion summarization by introducing a hierarchical indexing mechanism. Traditional opinion summarization models often treat the input text as a flat collection, which can make it challenging to efficiently retrieve the most relevant information for generating the summary.
To address this issue, the authors of HIRO construct a hierarchical index that organizes the input text into a tree-like structure. This hierarchy might group reviews by product category, then by specific product, and finally by individual reviewer comments. By modeling the relationships and context between different opinions in this way, the HIRO system can more effectively retrieve the most salient information when generating the summary.
The HIRO model consists of two main components: a hierarchical indexer and a retrieval-augmented summarizer. The hierarchical indexer is responsible for building the tree-like structure that represents the input text, while the retrieval-augmented summarizer leverages this hierarchy to select the most relevant snippets of text to include in the final summary.
The authors evaluate HIRO on several benchmark datasets for opinion summarization and compare its performance to state-of-the-art models. Their results demonstrate that the hierarchical indexing approach employed by HIRO leads to improved summarization quality, as measured by standard evaluation metrics. The authors attribute these improvements to HIRO's ability to better understand the context and relationships between different opinions, which allows the system to generate more coherent and comprehensive summaries.
Critical Analysis
The HIRO paper presents a novel and promising approach to improving opinion summarization, but it also has some potential limitations that could be addressed in future research.
One key aspect of the HIRO system is its reliance on a hierarchical indexing structure to organize the input text. While this hierarchical approach has shown to be effective, it may be challenging to construct such a hierarchy automatically, especially for more complex or diverse datasets. The authors do not provide details on how the hierarchy is constructed in practice, which could be an area for further investigation.
Additionally, the HIRO model is evaluated on standard benchmark datasets, which may not fully capture the real-world challenges and diversity of opinion summarization tasks. It would be valuable to see how the HIRO system performs on a broader range of datasets, including those with more complex structures or noisier input data.
Another potential limitation of the HIRO approach is its focus on retrieval-augmented summarization, which relies on the availability of a large corpus of relevant text. In situations where such a corpus is not readily available, the HIRO system may not be as effective, and alternative summarization techniques may be more appropriate.
Despite these potential limitations, the HIRO paper represents a significant contribution to the field of opinion summarization. The authors' insights into the benefits of hierarchical indexing and their empirical results suggest that this approach warrants further exploration and refinement.
Conclusion
The HIRO paper introduces a novel hierarchical indexing approach to improve retrieval-augmented opinion summarization. By organizing the input text into a tree-like structure, the HIRO system is able to better understand the context and relationships between different opinions, leading to more coherent and comprehensive summaries.
The authors' empirical evaluation demonstrates the effectiveness of the HIRO approach, with the system outperforming state-of-the-art opinion summarization models on benchmark datasets. While the HIRO system has some potential limitations, such as the complexity of hierarchy construction and its reliance on a large corpus of relevant text, the paper represents an important step forward in the field of opinion summarization.
As the volume of opinionated text continues to grow, techniques like HIRO that can efficiently extract and summarize the key insights will become increasingly valuable. The insights and findings presented in this paper could inspire further research and development in this important area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Indexing for Retrieval-Augmented Opinion Summarization
Tom Hosking, Hao Tang, Mirella Lapata
We propose a method for unsupervised abstractive opinion summarization, that combines the attributability and scalability of extractive approaches with the coherence and fluency of Large Language Models (LLMs). Our method, HIRO, learns an index structure that maps sentences to a path through a semantically organized discrete hierarchy. At inference time, we populate the index and use it to identify and retrieve clusters of sentences containing popular opinions from input reviews. Then, we use a pretrained LLM to generate a readable summary that is grounded in these extracted evidential clusters. The modularity of our approach allows us to evaluate its efficacy at each stage. We show that HIRO learns an encoding space that is more semantically structured than prior work, and generates summaries that are more representative of the opinions in the input reviews. Human evaluation confirms that HIRO generates significantly more coherent, detailed and accurate summaries.
Read more7/18/2024
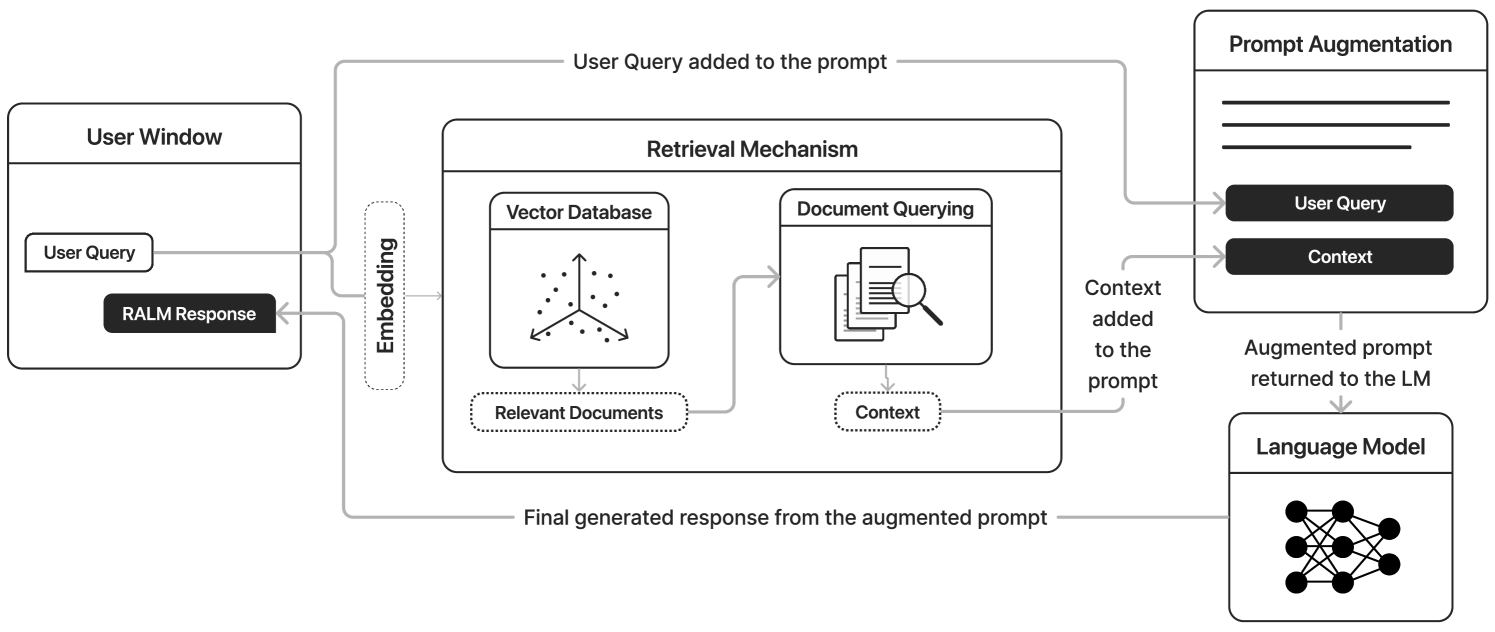
0
HIRO: Hierarchical Information Retrieval Optimization
Krish Goel, Mahek Chandak
Retrieval-Augmented Generation (RAG) has revolutionized natural language processing by dynamically integrating external knowledge into Large Language Models (LLMs), addressing their limitation of static training datasets. Recent implementations of RAG leverage hierarchical data structures, which organize documents at various levels of summarization and information density. This complexity, however, can cause LLMs to choke on information overload, necessitating more sophisticated querying mechanisms. In this context, we introduce Hierarchical Information Retrieval Optimization (HIRO), a novel querying approach that employs a Depth-First Search (DFS)-based recursive similarity score calculation and branch pruning. This method uniquely minimizes the context delivered to the LLM without informational loss, effectively managing the challenge of excessive data. HIRO's refined approach is validated by a 10.85% improvement in performance on the NarrativeQA dataset.
Read more9/5/2024
0
Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space
Seongmin Park, Kyungho Kim, Jaejin Seo, Jihwa Lee
We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions (blessing of dimensionality) to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.
Read more5/17/2024
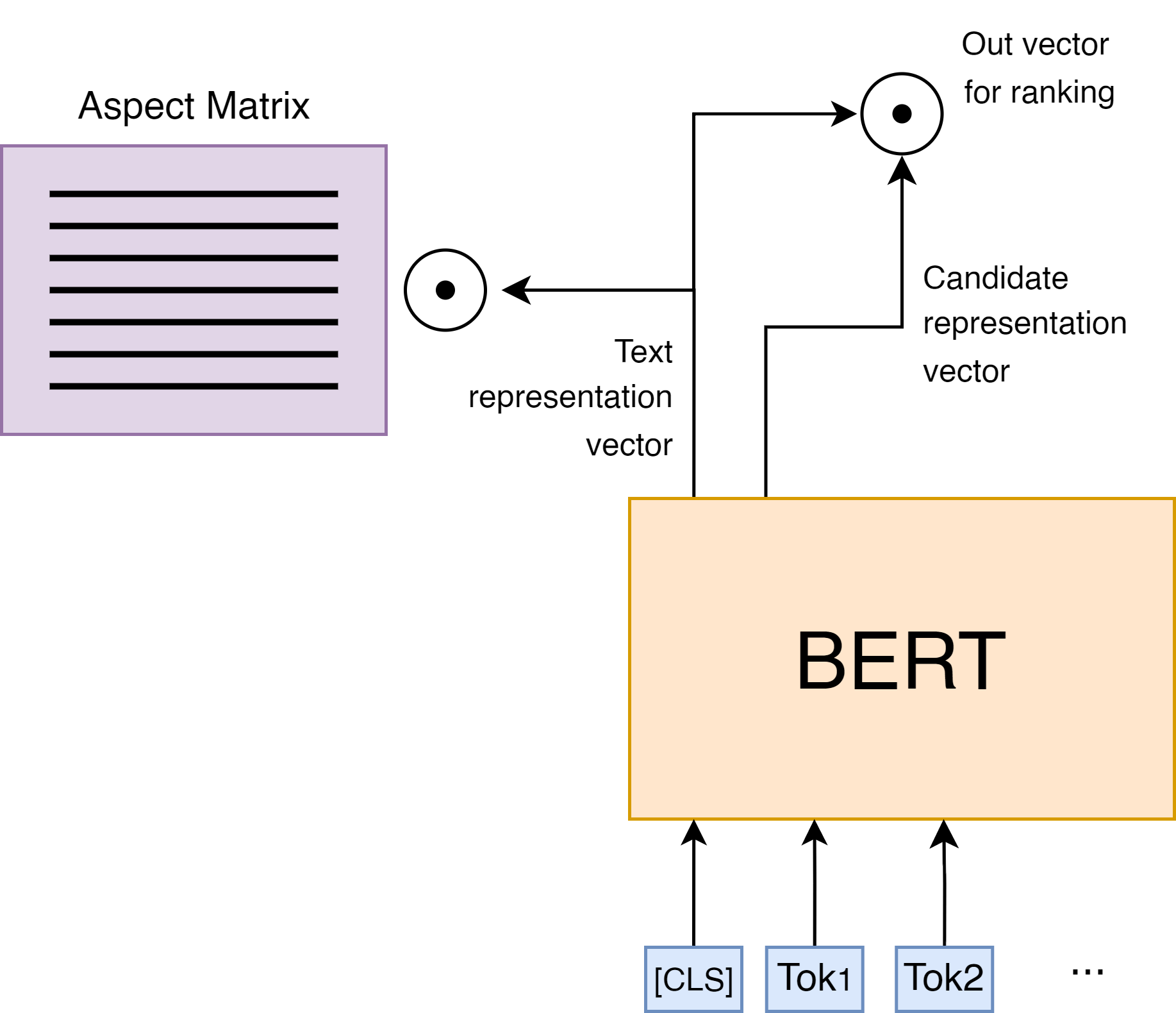
0
SumHiS: Extractive Summarization Exploiting Hidden Structure
Tikhonov Pavel, Anastasiya Ianina, Valentin Malykh
Extractive summarization is a task of highlighting the most important parts of the text. We introduce a new approach to extractive summarization task using hidden clustering structure of the text. Experimental results on CNN/DailyMail demonstrate that our approach generates more accurate summaries than both extractive and abstractive methods, achieving state-of-the-art results in terms of ROUGE-2 metric exceeding the previous approaches by 10%. Additionally, we show that hidden structure of the text could be interpreted as aspects.
Read more6/13/2024