HIRO: Hierarchical Information Retrieval Optimization

0
Sign in to get full access
Overview
- Introduces a novel information retrieval optimization technique called HIRO (Hierarchical Information Retrieval Optimization)
- Aims to improve the performance of retrieval-augmented generation models, which combine large language models with information retrieval systems
- Proposes a hierarchical approach to optimize the retrieval component, resulting in more relevant and informative retrieved content
Plain English Explanation
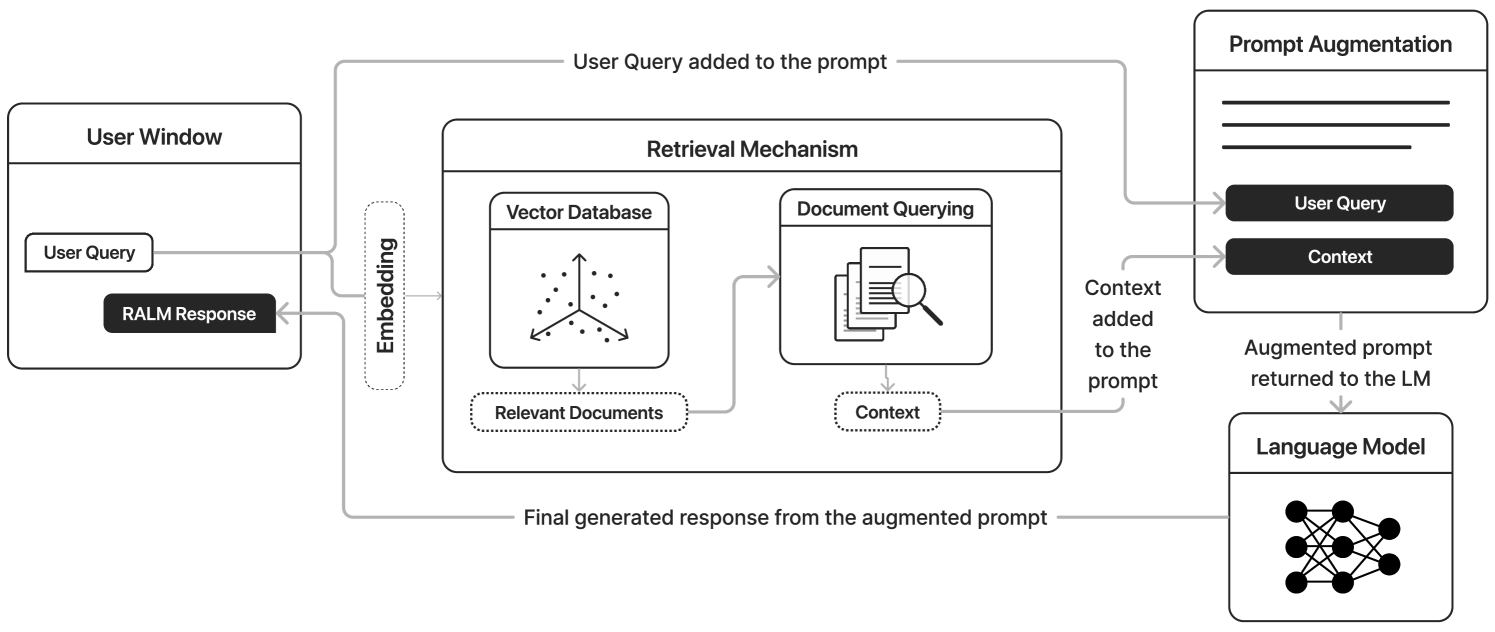
HIRO is a new way to make information retrieval systems work better with large language models. Large language models are powerful AI systems that can generate human-like text, but they sometimes struggle to access the most relevant information. HIRO tries to fix this by organizing the information in a hierarchical way, which helps the language model find the most important and useful information more easily.
This is important because large language models are being used for all kinds of tasks, from answering questions to generating reports and stories. If the language model can access the right information, it can produce much better results. HIRO is designed to make that information retrieval process more efficient and effective.
Technical Explanation
The core idea of HIRO is to organize the information being retrieved into a hierarchical structure, rather than a flat list. This allows the language model to navigate the information in a more structured way, focusing first on the most relevant high-level concepts and then drilling down into more specific details as needed.
The HIRO approach involves two key components:
-
Hierarchical Retrieval: The information retrieval system is modified to return results in a hierarchical format, with broad, high-level concepts at the top and more granular, detailed information further down the hierarchy.
-
Hierarchical Optimization: The language model is trained to effectively navigate this hierarchical information structure, learning which high-level concepts to focus on first and how to efficiently explore the deeper levels of the hierarchy to find the most relevant details.
By combining these hierarchical retrieval and optimization techniques, HIRO is able to provide large language models with more relevant and useful information, leading to improvements in the quality and coherence of the generated output.
Critical Analysis
The HIRO approach addresses an important challenge in the field of retrieval-augmented generation, where language models struggle to effectively leverage the information from retrieval systems. The hierarchical structure proposed in this work is a promising solution, as it aligns well with how humans naturally organize and process information.
However, the paper does not provide a deep exploration of the potential limitations or edge cases of the HIRO approach. For example, it's unclear how well the hierarchical retrieval and optimization techniques would scale to very large or complex information domains, or how robust the system would be to noise or incomplete information in the retrieval results.
Additionally, the paper does not compare HIRO to alternative approaches, such as DR-RAG, Unsupervised Information Refinement, Empowering Large Language Models to Set Up, or T-RAG, which also aim to improve the integration of information retrieval and language models. A more comprehensive comparison to these related approaches would help readers understand the unique benefits and tradeoffs of the HIRO technique.
Conclusion
The HIRO paper presents a novel approach to improving the performance of retrieval-augmented generation models by introducing a hierarchical structure to the information retrieval process. This hierarchical optimization aligns well with how humans process information and can help language models access more relevant and useful content.
While the paper does not fully explore the potential limitations of the HIRO approach, it represents an important step forward in the ongoing efforts to seamlessly integrate information retrieval and large language models. As research in this area continues to evolve, techniques like HIRO will likely play a key role in unlocking the full potential of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HIRO: Hierarchical Information Retrieval Optimization
Krish Goel, Mahek Chandak
Retrieval-Augmented Generation (RAG) has revolutionized natural language processing by dynamically integrating external knowledge into Large Language Models (LLMs), addressing their limitation of static training datasets. Recent implementations of RAG leverage hierarchical data structures, which organize documents at various levels of summarization and information density. This complexity, however, can cause LLMs to choke on information overload, necessitating more sophisticated querying mechanisms. In this context, we introduce Hierarchical Information Retrieval Optimization (HIRO), a novel querying approach that employs a Depth-First Search (DFS)-based recursive similarity score calculation and branch pruning. This method uniquely minimizes the context delivered to the LLM without informational loss, effectively managing the challenge of excessive data. HIRO's refined approach is validated by a 10.85% improvement in performance on the NarrativeQA dataset.
Read more9/5/2024

0
Hierarchical Retrieval-Augmented Generation Model with Rethink for Multi-hop Question Answering
Xiaoming Zhang, Ming Wang, Xiaocui Yang, Daling Wang, Shi Feng, Yifei Zhang
Multi-hop Question Answering (QA) necessitates complex reasoning by integrating multiple pieces of information to resolve intricate questions. However, existing QA systems encounter challenges such as outdated information, context window length limitations, and an accuracy-quantity trade-off. To address these issues, we propose a novel framework, the Hierarchical Retrieval-Augmented Generation Model with Rethink (HiRAG), comprising Decomposer, Definer, Retriever, Filter, and Summarizer five key modules. We introduce a new hierarchical retrieval strategy that incorporates both sparse retrieval at the document level and dense retrieval at the chunk level, effectively integrating their strengths. Additionally, we propose a single-candidate retrieval method to mitigate the limitations of multi-candidate retrieval. We also construct two new corpora, Indexed Wikicorpus and Profile Wikicorpus, to address the issues of outdated and insufficient knowledge. Our experimental results on four datasets demonstrate that HiRAG outperforms state-of-the-art models across most metrics, and our Indexed Wikicorpus is effective. The code for HiRAG is available at https://github.com/2282588541a/HiRAG
Read more8/23/2024
0
Optimizing Query Generation for Enhanced Document Retrieval in RAG
Hamin Koo, Minseon Kim, Sung Ju Hwang
Large Language Models (LLMs) excel in various language tasks but they often generate incorrect information, a phenomenon known as hallucinations. Retrieval-Augmented Generation (RAG) aims to mitigate this by using document retrieval for accurate responses. However, RAG still faces hallucinations due to vague queries. This study aims to improve RAG by optimizing query generation with a query-document alignment score, refining queries using LLMs for better precision and efficiency of document retrieval. Experiments have shown that our approach improves document retrieval, resulting in an average accuracy gain of 1.6%.
Read more7/18/2024

0
Hierarchical Indexing for Retrieval-Augmented Opinion Summarization
Tom Hosking, Hao Tang, Mirella Lapata
We propose a method for unsupervised abstractive opinion summarization, that combines the attributability and scalability of extractive approaches with the coherence and fluency of Large Language Models (LLMs). Our method, HIRO, learns an index structure that maps sentences to a path through a semantically organized discrete hierarchy. At inference time, we populate the index and use it to identify and retrieve clusters of sentences containing popular opinions from input reviews. Then, we use a pretrained LLM to generate a readable summary that is grounded in these extracted evidential clusters. The modularity of our approach allows us to evaluate its efficacy at each stage. We show that HIRO learns an encoding space that is more semantically structured than prior work, and generates summaries that are more representative of the opinions in the input reviews. Human evaluation confirms that HIRO generates significantly more coherent, detailed and accurate summaries.
Read more7/18/2024