Hierarchical Memory for Long Video QA

0
Sign in to get full access
Overview
- Introduces a novel hierarchical memory architecture for long-form video understanding
- Combines a streaming visual encoder with a hierarchical memory module to efficiently process and remember information from long videos
- Demonstrates state-of-the-art performance on the challenging MovieChat dataset for long-form video question answering
Plain English Explanation
This paper presents a new approach for understanding and answering questions about long videos. Many existing video understanding models struggle with lengthy videos, as they can only remember a limited amount of information at a time. The researchers introduce a "hierarchical memory" system that can efficiently store and retrieve key details from across an entire video.
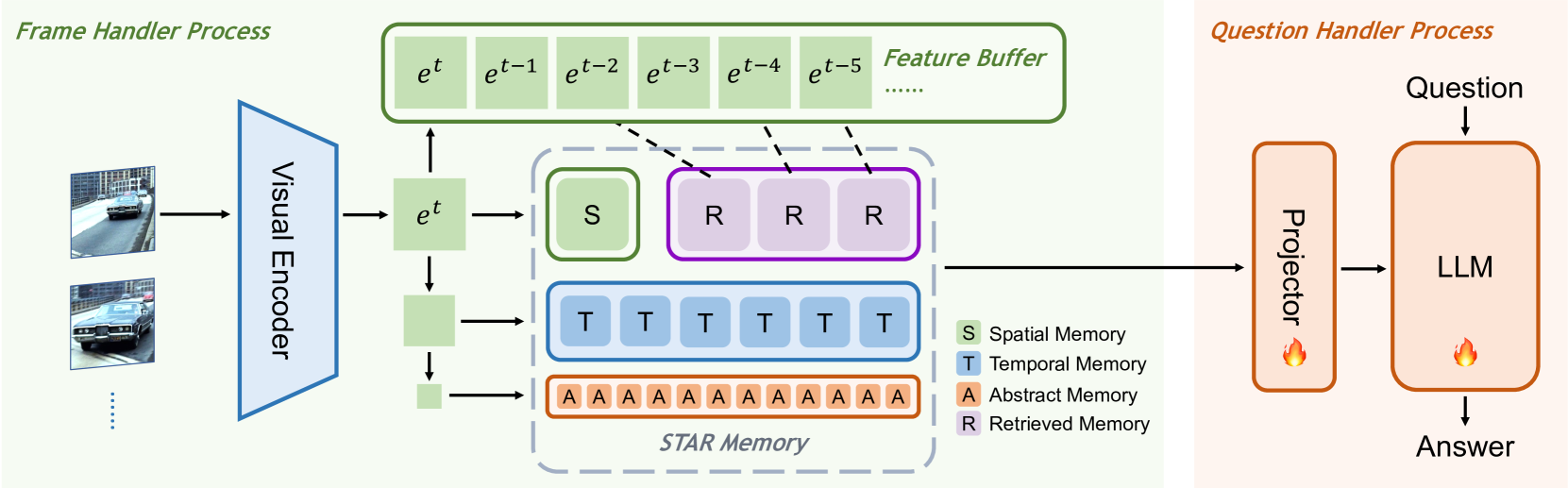
The model works by first using a "streaming" visual encoder to process the video frame-by-frame. This allows it to continuously update its understanding as the video plays, rather than trying to remember the whole thing at once. The encoded visual information is then stored in a multi-level memory system, which organizes it hierarchically based on its temporal relationships.
When answering a question about the video, the model can quickly locate and retrieve the most relevant information from this structured memory, without getting bogged down in irrelevant details. This hierarchical approach helps the model understand long videos more effectively than previous approaches that treated the entire video as a single unit.
The researchers test their model on the challenging MovieChat dataset, which contains lengthy movie clips and complex, open-ended questions about them. The hierarchical memory model achieves state-of-the-art performance, demonstrating its ability to efficiently encode and retrieve information from long video inputs.
Technical Explanation
The core of the model is a Streaming Visual Encoder that processes the video frame-by-frame, continuously updating its representation. This allows the model to maintain a dynamic understanding of the video content, rather than trying to encapsulate the entire sequence at once.
The encoded visual features are then stored in a Hierarchical Memory module, which organizes them based on their temporal relationships. This involves creating a multi-level memory structure, with higher-level nodes representing longer-range temporal contexts and lower-level nodes representing more granular, short-term details.
When answering a question, the model retrieves relevant information from this hierarchical memory by first locating the high-level nodes that capture the overall video context, and then drilling down to retrieve more specific details as needed. This allows the model to efficiently focus on the most salient information, without getting bogged down in irrelevant details.
The researchers evaluate their model on the MovieChat dataset, which contains lengthy movie clips and open-ended questions that require understanding the full video context. The hierarchical memory model achieves state-of-the-art performance, demonstrating its ability to effectively process and reason about long-form video content.
Critical Analysis
The hierarchical memory approach proposed in this paper represents an important step forward for long-form video understanding. By organizing video information in a structured, temporally-aware manner, the model is able to overcome the limitations of previous approaches that struggled with lengthy inputs.
That said, the paper does not address certain potential limitations or areas for future work. For example, the hierarchical memory structure is manually designed, rather than learned end-to-end. Developing a more flexible, self-organizing memory system could further improve the model's ability to capture relevant video semantics.
Additionally, the evaluation is focused on a specific task (video question answering) and dataset (MovieChat). It would be valuable to see how the hierarchical memory approach generalizes to other long-form video understanding problems, such as video summarization or video-grounded dialogue.
Overall, this work makes a compelling case for the importance of developing sophisticated memory mechanisms to handle the complexity of long-form video data. By continuing to build on these insights, future research may unlock even more powerful video understanding capabilities.
Conclusion
This paper introduces a novel hierarchical memory architecture that enables efficient processing and understanding of long video inputs. By combining a streaming visual encoder with a structured memory module, the model can effectively capture and retrieve relevant information from lengthy video sequences.
Evaluated on the challenging MovieChat dataset, the hierarchical memory model achieves state-of-the-art performance on the video question answering task. This demonstrates the potential of this approach to advance the field of long-form video understanding, which has important applications in areas like video summarization, video-grounded dialogue, and beyond.
While the paper highlights several promising directions, continued research is needed to further develop and generalize these techniques. By building on these foundations, future work may uncover even more powerful ways to make sense of the rich and complex information contained in long videos.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Memory for Long Video QA
Yiqin Wang, Haoji Zhang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, Xiaojie Jin
This paper describes our champion solution to the LOVEU Challenge @ CVPR'24, Track 1 (Long Video VQA). Processing long sequences of visual tokens is computationally expensive and memory-intensive, making long video question-answering a challenging task. The key is to compress visual tokens effectively, reducing memory footprint and decoding latency, while preserving the essential information for accurate question-answering. We adopt a hierarchical memory mechanism named STAR Memory, proposed in Flash-VStream, that is capable of processing long videos with limited GPU memory (VRAM). We further utilize the video and audio data of MovieChat-1K training set to fine-tune the pretrained weight released by Flash-VStream, achieving 1st place in the challenge. Code is available at project homepage https://invinciblewyq.github.io/vstream-page
Read more7/2/2024
0
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
Read more4/29/2024

0
Flash-VStream: Memory-Based Real-Time Understanding for Long Video Streams
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, Xiaojie Jin
Benefiting from the advancements in large language models and cross-modal alignment, existing multi-modal video understanding methods have achieved prominent performance in offline scenario. However, online video streams, as one of the most common media forms in the real world, have seldom received attention. Compared to offline videos, the 'dynamic' nature of online video streams poses challenges for the direct application of existing models and introduces new problems, such as the storage of extremely long-term information, interaction between continuous visual content and 'asynchronous' user questions. Therefore, in this paper we present Flash-VStream, a video-language model that simulates the memory mechanism of human. Our model is able to process extremely long video streams in real-time and respond to user queries simultaneously. Compared to existing models, Flash-VStream achieves significant reductions in inference latency and VRAM consumption, which is intimately related to performing understanding of online streaming video. In addition, given that existing video understanding benchmarks predominantly concentrate on offline scenario, we propose VStream-QA, a novel question answering benchmark specifically designed for online video streaming understanding. Comparisons with popular existing methods on the proposed benchmark demonstrate the superiority of our method for such challenging setting. To verify the generalizability of our approach, we further evaluate it on existing video understanding benchmarks and achieves state-of-the-art performance in offline scenarios as well. All code, models, and datasets are available at the https://invinciblewyq.github.io/vstream-page/
Read more7/2/2024

0
Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, Michael S. Ryoo
Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely related. Therefore, when performing long-form video question answering (LVQA), all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection that can significantly reduce these redundancies, namely Hierarchical Keyframe Selector. Our proposed framework, LVNet, achieves state-of-the-art performance at a comparable caption scale across three benchmark LVQA datasets: EgoSchema, IntentQA, NExT-QA. The code can be found at https://github.com/jongwoopark7978/LVNet
Read more9/25/2024