High-level Stream Processing: A Complementary Analysis of Fault Recovery

0
❗
Sign in to get full access
Overview
- Parallel computing is crucial for accelerating software systems
- Stream processing is a paradigm for handling high-volume, continuous data
- Open-source frameworks provide abstractions and parallelism for stream processing
- Fault tolerance, a key feature of stream processing, needs more comprehensive analysis
Plain English Explanation
Parallel computing is very important for making software run faster. Parallel computing is when a computer uses multiple processors at the same time to solve a problem. This is helpful for processing large amounts of data quickly.
One way to handle lots of continuous data is through stream processing. Stream processing is a way of processing data as it comes in, rather than waiting for all the data to be collected first. Open-source software frameworks provide tools to make stream processing easier and more parallel.
While the performance of stream processing has been studied a lot, the ability of these systems to handle errors and failures (called "fault tolerance") hasn't been measured as thoroughly. Fault tolerance is an important feature that lets stream processing systems keep working even if part of the system fails.
Technical Explanation
This paper extends previous research on measuring the fault recovery capabilities of stream processing frameworks. The researchers performed an exploratory analysis of different configuration settings, did additional experiments, and looked for ways to improve fault tolerance and performance.
The focus was on setting up stream processing systems that can handle real-time analytics for a large cloud monitoring platform. The results show there is significant potential to improve fault recovery and performance, but this requires dealing with complex configuration settings. Identifying the right configurations to tune and finding the appropriate values is challenging.
The researchers argue that new abstractions are needed to make configuration tuning more straightforward, especially for large-scale industrial use cases. They also suggest the stream processing community could benefit from closer collaboration with the parallel programming community, whose expertise in making parallel systems efficient and productive could be valuable.
Critical Analysis
The paper provides a comprehensive analysis of fault tolerance in stream processing frameworks, but acknowledges that dealing with the configuration complexity is a significant challenge. While the researchers identify opportunities for improvement, actually implementing those changes may require substantial engineering effort.
One potential limitation is the focus on a specific cloud observability use case. The insights may not generalize perfectly to other stream processing domains with different requirements. Broader testing across a variety of applications and workloads could help validate the findings.
Additionally, the paper does not delve deeply into the root causes of the configuration challenges. Further research into the fundamental architectural and design tradeoffs that lead to this complexity could inform the development of better abstractions and tooling.
Overall, the work provides a valuable contribution by highlighting an important, but underexplored, aspect of stream processing systems. Continued collaboration between researchers and industry practitioners will be crucial to address the challenges identified and improve the state of the art in fault-tolerant stream processing.
Conclusion
This paper explores the fault tolerance capabilities of stream processing frameworks, an important but understudied aspect of these systems. The researchers conducted an in-depth analysis, identifying significant potential for improving fault recovery and performance, but also highlighting the challenges of managing complex configuration settings.
The findings suggest that new abstractions and closer collaboration between the stream processing and parallel programming communities could help address these challenges. By making fault-tolerant stream processing more accessible and efficient, the industry and research community can enable more robust, scalable solutions for processing high-volume, continuous data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
High-level Stream Processing: A Complementary Analysis of Fault Recovery
Adriano Vogel, Soren Henning, Esteban Perez-Wohlfeil, Otmar Ertl, Rick Rabiser
Parallel computing is very important to accelerate the performance of software systems. Additionally, considering that a recurring challenge is to process high data volumes continuously, stream processing emerged as a paradigm and software architectural style. Several software systems rely on stream processing to deliver scalable performance, whereas open-source frameworks provide coding abstraction and high-level parallel computing. Although stream processing's performance is being extensively studied, the measurement of fault tolerance--a key abstraction offered by stream processing frameworks--has still not been adequately measured with comprehensive testbeds. In this work, we extend the previous fault recovery measurements with an exploratory analysis of the configuration space, additional experimental measurements, and analysis of improvement opportunities. We focus on robust deployment setups inspired by requirements for near real-time analytics of a large cloud observability platform. The results indicate significant potential for improving fault recovery and performance. However, these improvements entail grappling with configuration complexities, particularly in identifying and selecting the configurations to be fine-tuned and determining the appropriate values for them. Therefore, new abstractions for transparent configuration tuning are also needed for large-scale industry setups. We believe that more software engineering efforts are needed to provide insights into potential abstractions and how to achieve them. The stream processing community and industry practitioners could also benefit from more interactions with the high-level parallel programming community, whose expertise and insights on making parallel programming more productive and efficient could be extended.
Read more5/14/2024

0
A Comprehensive Benchmarking Analysis of Fault Recovery in Stream Processing Frameworks
Adriano Vogel, Soren Henning, Esteban Perez-Wohlfeil, Otmar Ertl, Rick Rabiser
Nowadays, several software systems rely on stream processing architectures to deliver scalable performance and handle large volumes of data in near real-time. Stream processing frameworks facilitate scalable computing by distributing the application's execution across multiple machines. Despite performance being extensively studied, the measurement of fault tolerance-a key feature offered by stream processing frameworks-has still not been measured properly with updated and comprehensive testbeds. Moreover, the impact that fault recovery can have on performance is mostly ignored. This paper provides a comprehensive analysis of fault recovery performance, stability, and recovery time in a cloud-native environment with modern open-source frameworks, namely Flink, Kafka Streams, and Spark Structured Streaming. Our benchmarking analysis is inspired by chaos engineering to inject failures. Generally, our results indicate that much has changed compared to previous studies on fault recovery in distributed stream processing. In particular, the results indicate that Flink is the most stable and has one of the best fault recovery. Moreover, Kafka Streams shows performance instabilities after failures, which is due to its current rebalancing strategy that can be suboptimal in terms of load balancing. Spark Structured Streaming shows suitable fault recovery performance and stability, but with higher event latency. Our study intends to (i) help industry practitioners in choosing the most suitable stream processing framework for efficient and reliable executions of data-intensive applications; (ii) support researchers in applying and extending our research method as well as our benchmark; (iii) identify, prevent, and assist in solving potential issues in production deployments.
Read more5/30/2024

0
Streaming Technologies and Serialization Protocols: Empirical Performance Analysis
Samuel Jackson, Nathan Cummings, Saiful Khan
Efficiently streaming high-volume data is essential for real-time data analytics, visualization, and AI and machine learning model training. Various streaming technologies and serialization protocols have been developed to meet different streaming needs. Together, they perform differently across various tasks and datasets. Therefore, when developing a streaming system, it can be challenging to make an informed decision on the suitable combination, as we encountered when implementing streaming for the UKAEA's MAST data or SKA's radio astronomy data. This study addresses this gap by proposing an empirical study of widely used data streaming technologies and serialization protocols. We introduce an extensible and open-source software framework to benchmark their efficiency across various performance metrics. Our findings reveal significant performance differences and trade-offs between these technologies. These insights can help in choosing suitable streaming and serialization solutions for contemporary data challenges. We aim to provide the scientific community and industry professionals with the knowledge to optimize data streaming for better data utilization and real-time analysis.
Read more7/19/2024
0
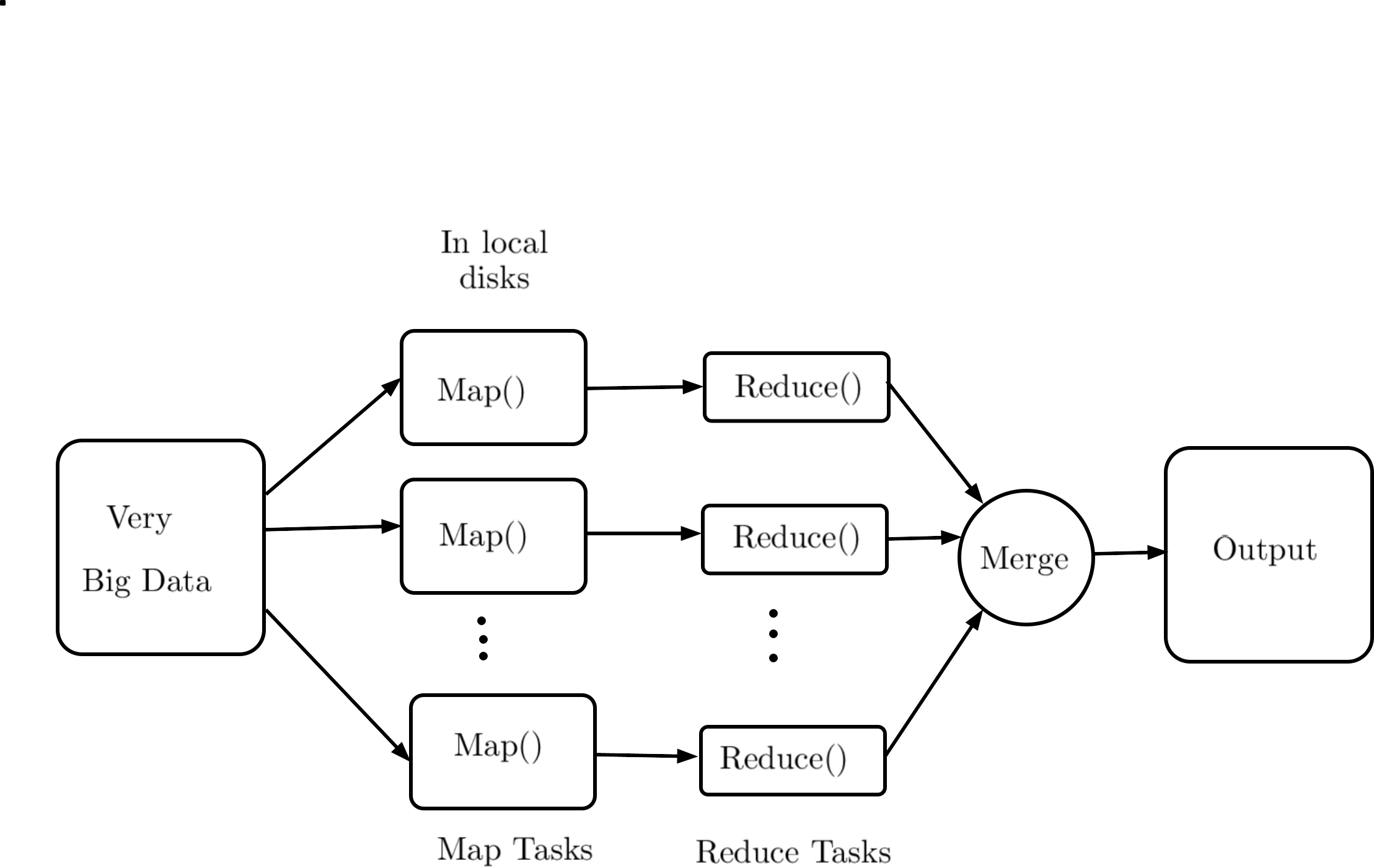
Analysis of Distributed Algorithms for Big-data
Rajendra Purohit, K R Chowdhary, S D Purohit
The parallel and distributed processing are becoming de facto industry standard, and a large part of the current research is targeted on how to make computing scalable and distributed, dynamically, without allocating the resources on permanent basis. The present article focuses on the study and performance of distributed and parallel algorithms their file systems, to achieve scalability at local level (OpenMP platform), and at global level where computing and file systems are distributed. Various applications, algorithms,file systems have been used to demonstrate the areas, and their performance studies have been presented. The systems and applications chosen here are of open-source nature, due to their wider applicability.
Read more4/10/2024