HiPose: Hierarchical Binary Surface Encoding and Correspondence Pruning for RGB-D 6DoF Object Pose Estimation
2311.12588
0
0
🛠️
Abstract
In this work, we present a novel dense-correspondence method for 6DoF object pose estimation from a single RGB-D image. While many existing data-driven methods achieve impressive performance, they tend to be time-consuming due to their reliance on rendering-based refinement approaches. To circumvent this limitation, we present HiPose, which establishes 3D-3D correspondences in a coarse-to-fine manner with a hierarchical binary surface encoding. Unlike previous dense-correspondence methods, we estimate the correspondence surface by employing point-to-surface matching and iteratively constricting the surface until it becomes a correspondence point while gradually removing outliers. Extensive experiments on public benchmarks LM-O, YCB-V, and T-Less demonstrate that our method surpasses all refinement-free methods and is even on par with expensive refinement-based approaches. Crucially, our approach is computationally efficient and enables real-time critical applications with high accuracy requirements.
Create account to get full access
Overview
- Presents a novel 6DoF object pose estimation method from a single RGB-D image
- Addresses limitations of existing data-driven methods that rely on time-consuming rendering-based refinement
- Introduces HiPose, a hierarchical binary surface encoding approach to establish 3D-3D correspondences in a coarse-to-fine manner
- Demonstrates state-of-the-art performance on public benchmarks while enabling real-time critical applications
Plain English Explanation
The paper describes a new way to estimate the 6 Degrees of Freedom (6DoF) pose of objects from a single RGB-D image. Many existing methods use machine learning models trained on large datasets, but these can be slow because they often require additional refinement steps.
To address this, the researchers developed a method called HiPose that establishes 3D-3D correspondences between the image and a 3D model of the object in a hierarchical, step-by-step manner. It starts with a coarse correspondence and gradually refines it, removing any outliers along the way. This allows for fast and accurate 6DoF pose estimation without the need for expensive refinement.
The method was tested on several public benchmarks and outperformed other refinement-free approaches. Importantly, it was also able to match the performance of more complex, refinement-based methods, while being much more computationally efficient. This makes HiPose suitable for real-time applications that require accurate 6DoF pose estimation, such as robotic manipulation or dynamic scene reconstruction.
Technical Explanation
The paper proposes a novel dense-correspondence method for 6DoF object pose estimation from a single RGB-D image. Unlike many existing data-driven approaches that rely on time-consuming rendering-based refinement, the authors introduce HiPose, which establishes 3D-3D correspondences in a coarse-to-fine manner using a hierarchical binary surface encoding.
Unlike previous dense-correspondence methods, HiPose estimates the correspondence surface by employing point-to-surface matching and iteratively constricting the surface until it becomes a correspondence point, while gradually removing outliers. This allows for efficient and accurate 6DoF pose estimation without the need for expensive refinement.
Extensive experiments on public benchmarks, including LM-O, YCB-V, and T-Less, demonstrate that HiPose surpasses all refinement-free methods and is even on par with more complex, refinement-based approaches. Crucially, the method is computationally efficient, enabling real-time critical applications with high accuracy requirements.
Critical Analysis
The paper presents a compelling solution to the challenge of efficient and accurate 6DoF object pose estimation from single RGB-D images. The authors' approach of hierarchical 3D-3D correspondence establishment is novel and effective, as demonstrated by the strong performance on public benchmarks.
One potential limitation of the method is its reliance on having access to a 3D model of the object, which may not always be available in real-world scenarios. The authors acknowledge this and suggest that future work could explore ways to extend the method to handle cases where only a single image of the object is available.
Additionally, the paper does not provide a detailed analysis of the method's robustness to occlusions, lighting changes, or other common real-world challenges. Further research could investigate the performance of HiPose in more realistic and complex environments.
Overall, the paper presents a valuable contribution to the field of 6DoF object pose estimation and demonstrates the potential of hierarchical correspondence-based approaches to address the limitations of existing data-driven methods.
Conclusion
This work introduces HiPose, a novel dense-correspondence method for 6DoF object pose estimation from a single RGB-D image. By leveraging a hierarchical binary surface encoding to establish 3D-3D correspondences in a coarse-to-fine manner, the method achieves state-of-the-art performance on public benchmarks while being computationally efficient enough for real-time applications.
The key innovation of HiPose is its ability to accurately estimate object poses without relying on time-consuming rendering-based refinement, which has been a limitation of many existing data-driven approaches. This makes the method a promising solution for a wide range of robotic and computer vision applications that require fast and precise 6DoF pose estimation, such as robotic manipulation and dynamic scene reconstruction.
Future research could explore ways to further improve the method's robustness and generalizability, as well as investigate its potential for integration with other computer vision and robotics techniques to create more comprehensive and versatile systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Resolving Symmetry Ambiguity in Correspondence-based Methods for Instance-level Object Pose Estimation
Yongliang Lin, Yongzhi Su, Sandeep Inuganti, Yan Di, Naeem Ajilforoushan, Hanqing Yang, Yu Zhang, Jason Rambach
0
0
Estimating the 6D pose of an object from a single RGB image is a critical task that becomes additionally challenging when dealing with symmetric objects. Recent approaches typically establish one-to-one correspondences between image pixels and 3D object surface vertices. However, the utilization of one-to-one correspondences introduces ambiguity for symmetric objects. To address this, we propose SymCode, a symmetry-aware surface encoding that encodes the object surface vertices based on one-to-many correspondences, eliminating the problem of one-to-one correspondence ambiguity. We also introduce SymNet, a fast end-to-end network that directly regresses the 6D pose parameters without solving a PnP problem. We demonstrate faster runtime and comparable accuracy achieved by our method on the T-LESS and IC-BIN benchmarks of mostly symmetric objects. Our source code will be released upon acceptance.
5/20/2024
🌐
RDPN6D: Residual-based Dense Point-wise Network for 6Dof Object Pose Estimation Based on RGB-D Images
Zong-Wei Hong, Yen-Yang Hung, Chu-Song Chen
0
0
In this work, we introduce a novel method for calculating the 6DoF pose of an object using a single RGB-D image. Unlike existing methods that either directly predict objects' poses or rely on sparse keypoints for pose recovery, our approach addresses this challenging task using dense correspondence, i.e., we regress the object coordinates for each visible pixel. Our method leverages existing object detection methods. We incorporate a re-projection mechanism to adjust the camera's intrinsic matrix to accommodate cropping in RGB-D images. Moreover, we transform the 3D object coordinates into a residual representation, which can effectively reduce the output space and yield superior performance. We conducted extensive experiments to validate the efficacy of our approach for 6D pose estimation. Our approach outperforms most previous methods, especially in occlusion scenarios, and demonstrates notable improvements over the state-of-the-art methods. Our code is available on https://github.com/AI-Application-and-Integration-Lab/RDPN6D.
5/15/2024
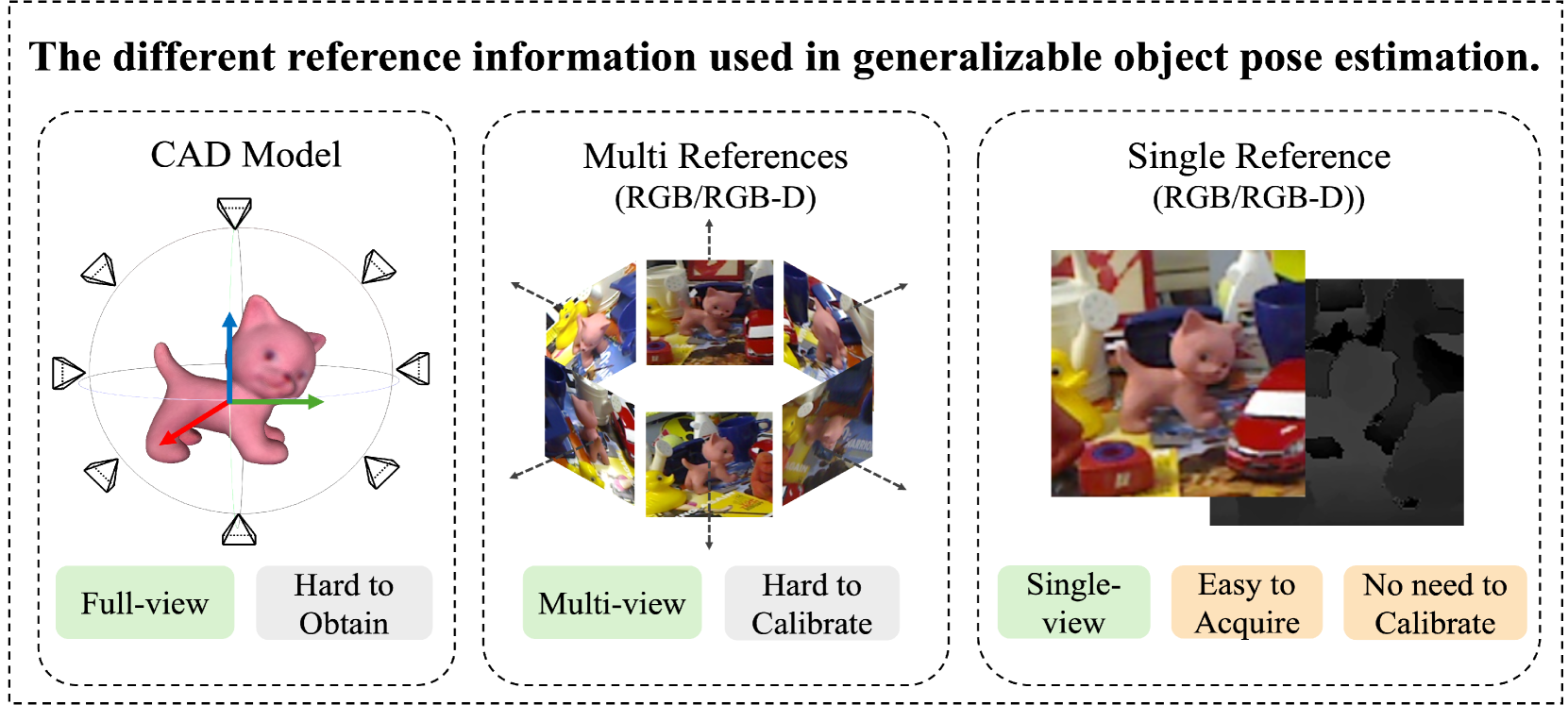
Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference
Yuan Gao, Yajing Luo, Junhong Wang, Kui Jia, Gui-Song Xia
0
0
Humans can easily deduce the relative pose of an unseen object, without label/training, given only a single query-reference image pair. This is arguably achieved by incorporating (i) 3D/2.5D shape perception from a single image, (ii) render-and-compare simulation, and (iii) rich semantic cue awareness to furnish (coarse) reference-query correspondence. Existing methods implement (i) by a 3D CAD model or well-calibrated multiple images and (ii) by training a network on specific objects, which necessitate laborious ground-truth labeling and tedious training, potentially leading to challenges in generalization. Moreover, (iii) was less exploited in the paradigm of (ii), despite that the coarse correspondence from (iii) enhances the compare process by filtering out non-overlapped parts under substantial pose differences/occlusions. Motivated by this, we propose a novel 3D generalizable relative pose estimation method by elaborating (i) with a 2.5D shape from an RGB-D reference, (ii) with an off-the-shelf differentiable renderer, and (iii) with semantic cues from a pretrained model like DINOv2. Specifically, our differentiable renderer takes the 2.5D rotatable mesh textured by the RGB and the semantic maps (obtained by DINOv2 from the RGB input), then renders new RGB and semantic maps (with back-surface culling) under a novel rotated view. The refinement loss comes from comparing the rendered RGB and semantic maps with the query ones, back-propagating the gradients through the differentiable renderer to refine the 3D relative pose. As a result, our method can be readily applied to unseen objects, given only a single RGB-D reference, without label/training. Extensive experiments on LineMOD, LM-O, and YCB-V show that our training-free method significantly outperforms the SOTA supervised methods, especially under the rigorous Acc@5/10/15{deg} metrics and the challenging cross-dataset settings.
6/27/2024
🛸
One Point, One Object: Simultaneous 3D Object Segmentation and 6-DOF Pose Estimation
Hongsen Liu
0
0
We propose a single-shot method for simultaneous 3D object segmentation and 6-DOF pose estimation in pure 3D point clouds scenes based on a consensus that emph{one point only belongs to one object}, i.e., each point has the potential power to predict the 6-DOF pose of its corresponding object. Unlike the recently proposed methods of the similar task, which rely on 2D detectors to predict the projection of 3D corners of the 3D bounding boxes and the 6-DOF pose must be estimated by a PnP like spatial transformation method, ours is concise enough not to require additional spatial transformation between different dimensions. Due to the lack of training data for many objects, the recently proposed 2D detection methods try to generate training data by using rendering engine and achieve good results. However, rendering in 3D space along with 6-DOF is relatively difficult. Therefore, we propose an augmented reality technology to generate the training data in semi-virtual reality 3D space. The key component of our method is a multi-task CNN architecture that can simultaneously predicts the 3D object segmentation and 6-DOF pose estimation in pure 3D point clouds. For experimental evaluation, we generate expanded training data for two state-of-the-arts 3D object datasets cite{PLCHF}cite{TLINEMOD} by using Augmented Reality technology (AR). We evaluate our proposed method on the two datasets. The results show that our method can be well generalized into multiple scenarios and provide performance comparable to or better than the state-of-the-arts.
6/7/2024