How Does Code Pretraining Affect Language Model Task Performance?

0
Sign in to get full access
Overview
- This paper investigates how pretraining language models on programming code data affects their performance on various language tasks.
- The researchers trained several language models with different pretraining data, including code-only, text-only, and a combination of the two.
- They then evaluated the models' performance on a diverse set of language understanding benchmarks.
Plain English Explanation
The researchers in this study wanted to understand how pretraining language models on programming code data, rather than just regular text, might impact the models' abilities to perform various language-related tasks.
They trained several different language models, each with a different type of pretraining data:
- Some were trained only on programming code
- Some were trained only on regular text
- And some were trained on a mix of code and text
After training, the researchers tested how well each model performed on a wide range of language understanding tests. This allowed them to see if the code-trained models were better at certain tasks compared to the text-trained models, and vice versa.
The key idea is that the way a language model is initially trained (or "pretrained") on data can shape its capabilities and how it understands and uses language. By pretraining on code, the researchers hoped to give the models some special skills that could be useful for certain language-related applications.
Technical Explanation
The paper presents an empirical study on the effects of pretraining language models on programming code data versus natural language text. The researchers trained several variants of the BERT model, a popular language model, using different pretraining data:
- Code-only pretraining: The models were trained exclusively on a large corpus of programming code.
- Text-only pretraining: The models were trained only on a corpus of natural language text.
- Code+text pretraining: The models were trained on a mix of code and text data.
After pretraining, the models were evaluated on a diverse suite of language understanding benchmarks, including question answering, natural language inference, sentiment analysis, and more. This allowed the researchers to assess how the pretraining data affected the models' performance across a range of language tasks.
The results showed that the code-trained models generally outperformed the text-trained models on programming-related tasks, such as code completion and code summarization. However, the text-trained models were superior on many general language understanding tasks. The models trained on a mix of code and text data tended to perform well on both sets of tasks, suggesting that combined pretraining can be an effective strategy.
Critical Analysis
The paper provides a rigorous and well-designed empirical study on an important question in language model research. The researchers' systematic approach of training multiple model variants and evaluating them on a diverse set of benchmarks yields valuable insights.
One potential limitation is that the study focuses on a specific language model architecture (BERT) and a particular type of programming code (likely from GitHub). It would be interesting to see if the findings generalize to other model types and code domains.
Additionally, the paper does not deeply explore the underlying mechanisms by which code pretraining affects language model capabilities. Further research could investigate the learned representations and attention patterns to shed light on the reasons behind the observed performance differences.
Another area for potential future work is to explore more nuanced strategies for combining code and text pretraining, such as dynamically adjusting the pretraining ratio based on the target task or using specialized pretraining objectives.
Overall, this paper makes an important contribution to our understanding of how the choice of pretraining data can shape the capabilities of language models. The findings have implications for the development of models that can effectively work with both natural language and programming code.
Conclusion
This study demonstrates that pretraining language models on programming code data can confer specific advantages for tasks related to code understanding and generation, compared to models trained only on natural language text. However, text-only pretraining remains superior for many general language understanding tasks.
The results suggest that a combined pretraining approach, using both code and text data, may be an effective strategy to develop language models that are broadly capable across a wide range of applications. This could have significant implications for the development of AI systems that need to work seamlessly with both human language and computer code.
The insights from this paper highlight the importance of carefully considering the pretraining data and objectives when designing language models for real-world use cases. As the capabilities of these models continue to advance, understanding their strengths, limitations, and biases will be crucial for responsible and effective deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Does Code Pretraining Affect Language Model Task Performance?
Jackson Petty, Sjoerd van Steenkiste, Tal Linzen
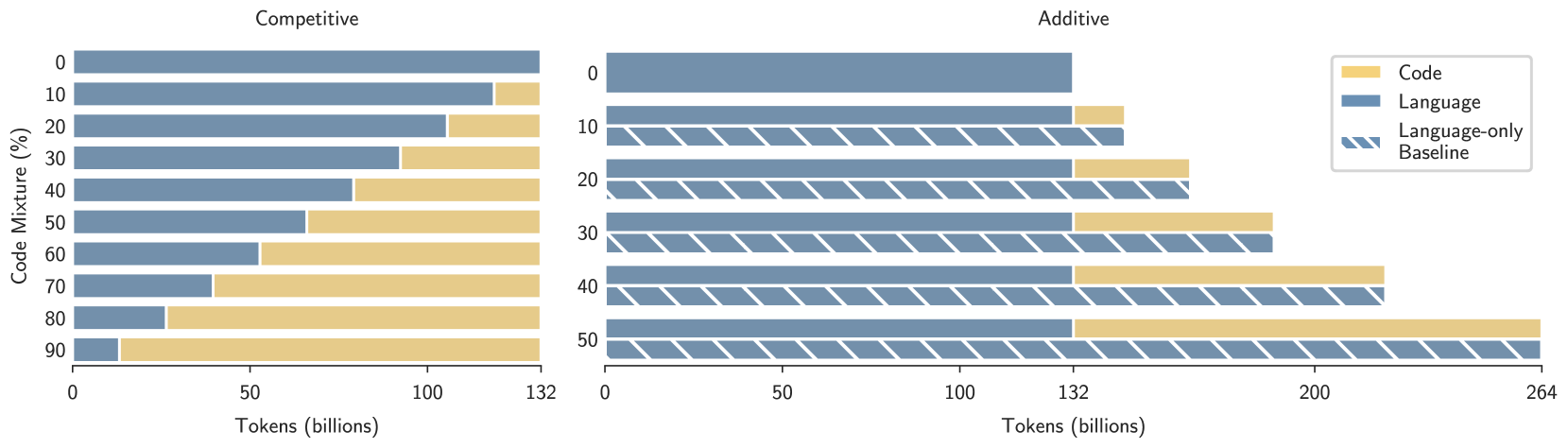
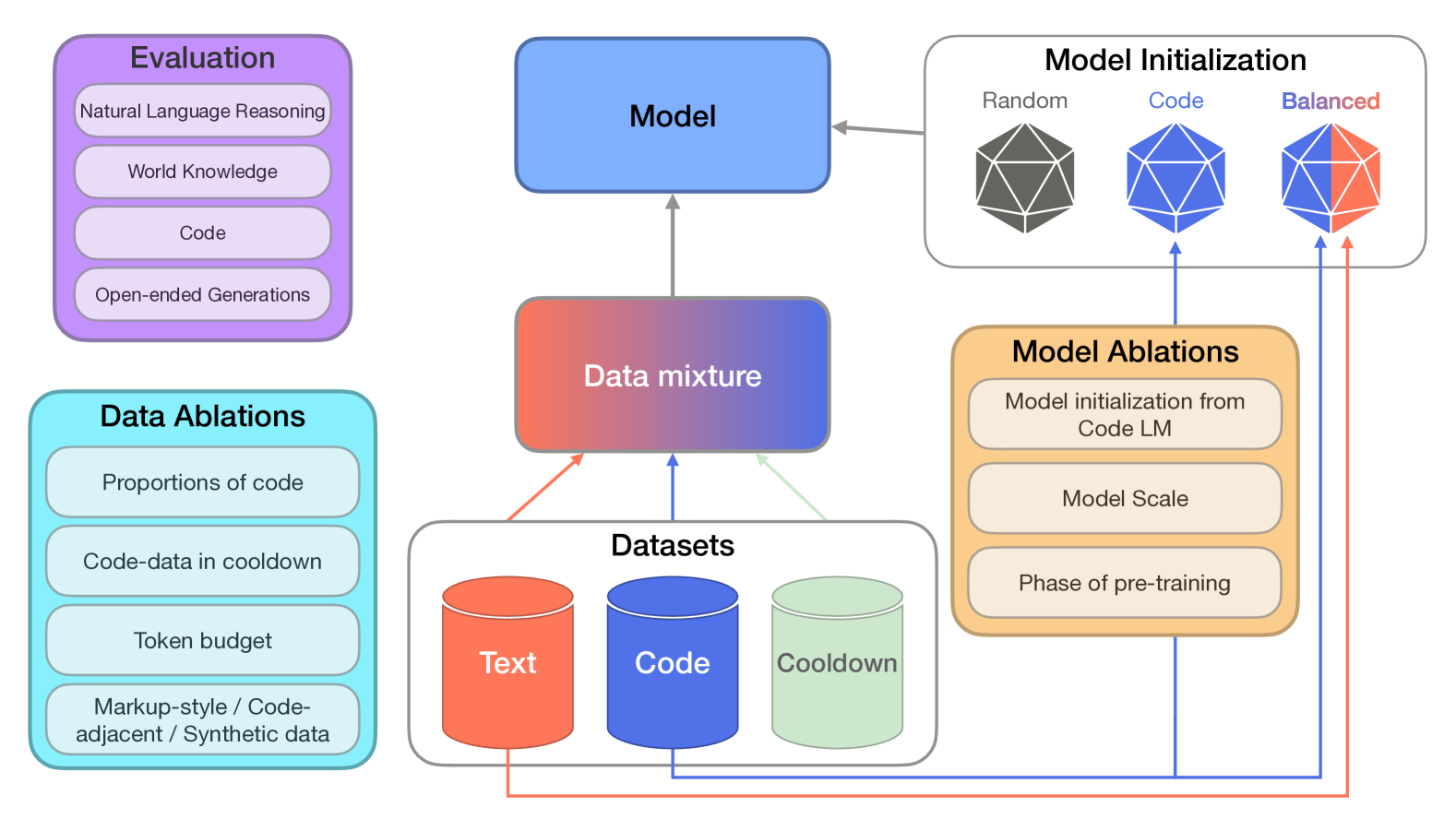
Large language models are increasingly trained on corpora containing both natural language and non-linguistic data like source code. Aside from aiding programming-related tasks, anecdotal evidence suggests that including code in pretraining corpora may improve performance on other, unrelated tasks, yet to date no work has been able to establish a causal connection by controlling between language and code data. Here we do just this. We pretrain language models on datasets which interleave natural language and code in two different settings: additive, in which the total volume of data seen during pretraining is held constant; and competitive, in which the volume of language data is held constant. We study how the pretraining mixture affects performance on (a) a diverse collection of tasks included in the BigBench benchmark, and (b) compositionality, measured by generalization accuracy on semantic parsing and syntactic transformations. We find that pretraining on higher proportions of code improves performance on compositional tasks involving structured output (like semantic parsing), and mathematics. Conversely, increase code mixture can harm performance on other tasks, including on tasks that requires sensitivity to linguistic structure such as syntax or morphology, and tasks measuring real-world knowledge.
Read more9/10/2024
430
To Code, or Not To Code? Exploring Impact of Code in Pre-training
Viraat Aryabumi, Yixuan Su, Raymond Ma, Adrien Morisot, Ivan Zhang, Acyr Locatelli, Marzieh Fadaee, Ahmet Ustun, Sara Hooker
Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been anecdotal consensus among practitioners that code data plays a vital role in general LLMs' performance, there is only limited work analyzing the precise impact of code on non-code tasks. In this work, we systematically investigate the impact of code data on general performance. We ask what is the impact of code data used in pre-training on a large variety of downstream tasks beyond code generation. We conduct extensive ablations and evaluate across a broad range of natural language reasoning tasks, world knowledge tasks, code benchmarks, and LLM-as-a-judge win-rates for models with sizes ranging from 470M to 2.8B parameters. Across settings, we find a consistent results that code is a critical building block for generalization far beyond coding tasks and improvements to code quality have an outsized impact across all tasks. In particular, compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively. Our work suggests investments in code quality and preserving code during pre-training have positive impacts.
Read more8/21/2024

0
Code Pretraining Improves Entity Tracking Abilities of Language Models
Najoung Kim, Sebastian Schuster, Shubham Toshniwal
Recent work has provided indirect evidence that pretraining language models on code improves the ability of models to track state changes of discourse entities expressed in natural language. In this work, we systematically test this claim by comparing pairs of language models on their entity tracking performance. Critically, the pairs consist of base models and models trained on top of these base models with additional code data. We extend this analysis to additionally examine the effect of math training, another highly structured data type, and alignment tuning, an important step for enhancing the usability of models. We find clear evidence that models additionally trained on large amounts of code outperform the base models. On the other hand, we find no consistent benefit of additional math training or alignment tuning across various model families.
Read more6/3/2024
📊
0
Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning
Yang Zhao, Li Du, Xiao Ding, Kai Xiong, Zhouhao Sun, Jun Shi, Ting Liu, Bing Qin
Through pretraining on a corpus with various sources, Large Language Models (LLMs) have gained impressive performance. However, the impact of each component of the pretraining corpus remains opaque. As a result, the organization of the pretraining corpus is still empirical and may deviate from the optimal. To address this issue, we systematically analyze the impact of 48 datasets from 5 major categories of pretraining data of LLMs and measure their impacts on LLMs using benchmarks about nine major categories of model capabilities. Our analyses provide empirical results about the contribution of multiple corpora on the performances of LLMs, along with their joint impact patterns, including complementary, orthogonal, and correlational relationships. We also identify a set of ``high-impact data'' such as Books that is significantly related to a set of model capabilities. These findings provide insights into the organization of data to support more efficient pretraining of LLMs.
Read more8/29/2024