To Code, or Not To Code? Exploring Impact of Code in Pre-training

430
Sign in to get full access
Overview
- This paper explores the impact of including code in the pre-training data of language models.
- The researchers investigate whether including code during pre-training can improve a model's performance on tasks involving code.
- They compare models pre-trained on a mix of natural language and code to those pre-trained on natural language alone.
Plain English Explanation
When training large language models like GPT-3, the data used during the initial "pre-training" phase is crucial. Most pre-training is done on a broad corpus of natural language text, such as books, websites, and social media.
The researchers in this paper wanted to see if including programming code alongside the natural language data could make the model better at working with and understanding code. This could be useful for applications like code generation, code summarization, or code-related question answering.
They trained two versions of a language model - one using just natural language data, and one using a mix of natural language and programming code. Then they tested both models on a variety of tasks related to code, like predicting the next line of code or explaining the purpose of a code snippet.
The results showed that the model pre-trained on the mix of natural language and code performed significantly better on the code-related tasks compared to the model trained only on natural language. This suggests that exposing the model to real-world code during pre-training can improve its ability to understand and work with code.
Technical Explanation
The core of the paper is an experiment where the researchers train two versions of a large language model:
- Natural Language Model: Pre-trained on a corpus of natural language text only
- Code-Mixed Model: Pre-trained on a corpus that includes both natural language text and real programming code
They then evaluate the two models on a suite of code-related tasks, including:
- Code Summarization: Generating natural language descriptions of code snippets
- Next Line Prediction: Predicting the next line of code given a partial program
- Code Retrieval: Finding relevant code examples given a natural language description
The results show that the Code-Mixed Model significantly outperforms the Natural Language Model on all the code-related tasks. This suggests that pre-training on a mix of natural language and code can boost a model's understanding and generation of code.
The authors hypothesize this is because the Code-Mixed Model is able to learn patterns and associations between natural language and code that the Natural Language Model cannot. This allows the Code-Mixed Model to better apply its language understanding capabilities to code-based tasks.
Critical Analysis
The paper provides compelling evidence that incorporating code into language model pre-training can be beneficial. However, there are a few important caveats to consider:
-
Dataset Quality and Diversity: The researchers use a specific dataset of code and natural language text. The generalizability of the results may depend on the characteristics of this dataset, such as the programming languages represented, the quality of the code, and the breadth of the natural language.
-
Downstream Task Selection: The evaluation is limited to a relatively narrow set of code-related tasks. It's unclear how the models would perform on a wider range of code understanding and generation tasks.
-
Computational Cost: Pre-training large language models on a mix of natural language and code may be computationally more expensive and time-consuming. The benefits would need to be weighed against the increased training requirements.
-
Potential Biases: Incorporating code data could potentially introduce new biases into the model, such as favoring certain programming paradigms or languages. Further analysis of the model's behavior would be needed to understand these effects.
Overall, this is an interesting and promising line of research, but more work is needed to fully understand the implications and tradeoffs of incorporating code into language model pre-training.
Conclusion
This paper demonstrates that pre-training language models on a mix of natural language and programming code can significantly improve their performance on code-related tasks, compared to models trained on natural language alone.
The findings suggest that exposing language models to real-world code during pre-training allows them to learn valuable associations and patterns that can be leveraged for a variety of code understanding and generation applications. This could have important implications for the development of more capable AI systems that can seamlessly integrate natural language and code.
While further research is needed to fully understand the tradeoffs, this work represents an important step towards bridging the gap between natural language and programming, and creating AI systems that are more adept at working with both.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
430
To Code, or Not To Code? Exploring Impact of Code in Pre-training
Viraat Aryabumi, Yixuan Su, Raymond Ma, Adrien Morisot, Ivan Zhang, Acyr Locatelli, Marzieh Fadaee, Ahmet Ustun, Sara Hooker
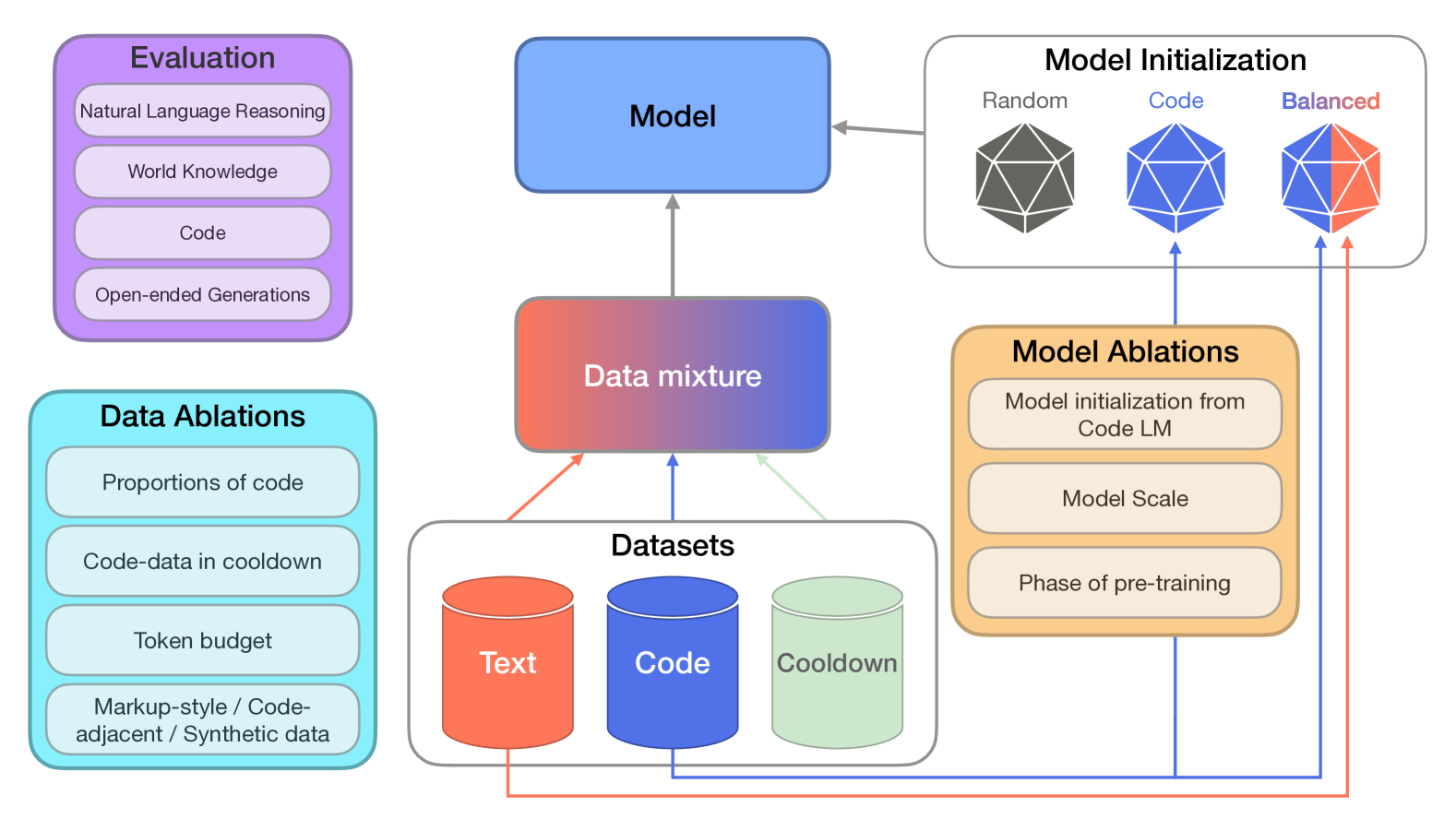
Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been anecdotal consensus among practitioners that code data plays a vital role in general LLMs' performance, there is only limited work analyzing the precise impact of code on non-code tasks. In this work, we systematically investigate the impact of code data on general performance. We ask what is the impact of code data used in pre-training on a large variety of downstream tasks beyond code generation. We conduct extensive ablations and evaluate across a broad range of natural language reasoning tasks, world knowledge tasks, code benchmarks, and LLM-as-a-judge win-rates for models with sizes ranging from 470M to 2.8B parameters. Across settings, we find a consistent results that code is a critical building block for generalization far beyond coding tasks and improvements to code quality have an outsized impact across all tasks. In particular, compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively. Our work suggests investments in code quality and preserving code during pre-training have positive impacts.
Read more8/21/2024
0
How Does Code Pretraining Affect Language Model Task Performance?
Jackson Petty, Sjoerd van Steenkiste, Tal Linzen
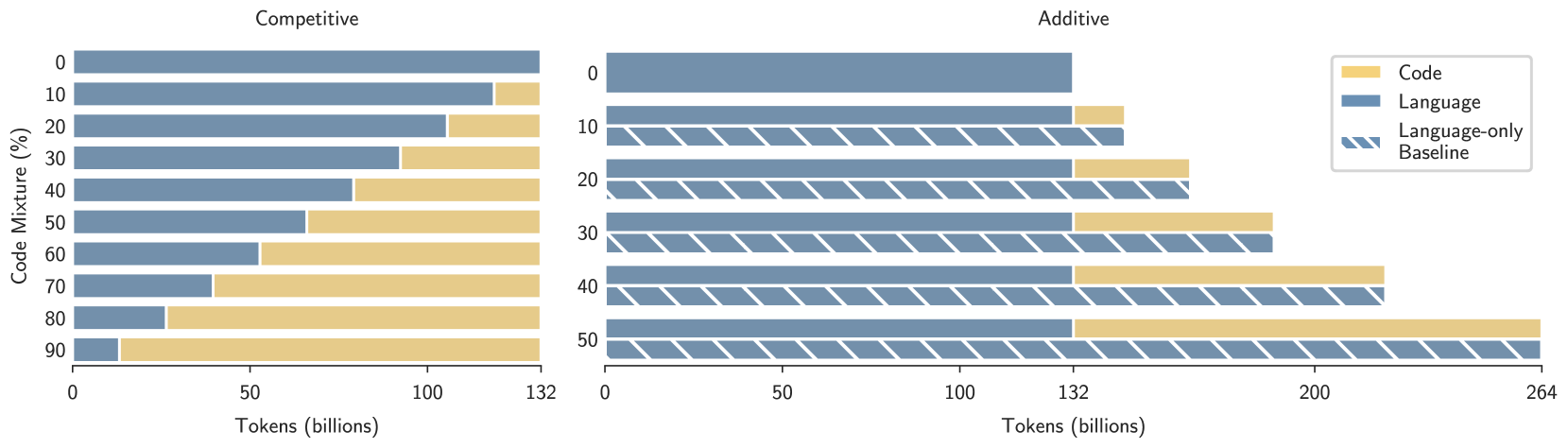
Large language models are increasingly trained on corpora containing both natural language and non-linguistic data like source code. Aside from aiding programming-related tasks, anecdotal evidence suggests that including code in pretraining corpora may improve performance on other, unrelated tasks, yet to date no work has been able to establish a causal connection by controlling between language and code data. Here we do just this. We pretrain language models on datasets which interleave natural language and code in two different settings: additive, in which the total volume of data seen during pretraining is held constant; and competitive, in which the volume of language data is held constant. We study how the pretraining mixture affects performance on (a) a diverse collection of tasks included in the BigBench benchmark, and (b) compositionality, measured by generalization accuracy on semantic parsing and syntactic transformations. We find that pretraining on higher proportions of code improves performance on compositional tasks involving structured output (like semantic parsing), and mathematics. Conversely, increase code mixture can harm performance on other tasks, including on tasks that requires sensitivity to linguistic structure such as syntax or morphology, and tasks measuring real-world knowledge.
Read more9/10/2024

0
Code Pretraining Improves Entity Tracking Abilities of Language Models
Najoung Kim, Sebastian Schuster, Shubham Toshniwal
Recent work has provided indirect evidence that pretraining language models on code improves the ability of models to track state changes of discourse entities expressed in natural language. In this work, we systematically test this claim by comparing pairs of language models on their entity tracking performance. Critically, the pairs consist of base models and models trained on top of these base models with additional code data. We extend this analysis to additionally examine the effect of math training, another highly structured data type, and alignment tuning, an important step for enhancing the usability of models. We find clear evidence that models additionally trained on large amounts of code outperform the base models. On the other hand, we find no consistent benefit of additional math training or alignment tuning across various model families.
Read more6/3/2024

0
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
Xinlu Zhang, Zhiyu Zoey Chen, Xi Ye, Xianjun Yang, Lichang Chen, William Yang Wang, Linda Ruth Petzold
Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost reasoning abilities during LLM pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during the IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights in each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, the effect of coding data varies among different domains but shows consistent trends across model families and scales within each domain. Additionally, coding data generally yields comparable task-specific benefits across different model families, with the optimal coding data proportions in IFT datasets being task-specific.
Read more6/3/2024