How Does the Textual Information Affect the Retrieval of Multimodal In-Context Learning?

0
Sign in to get full access
Overview
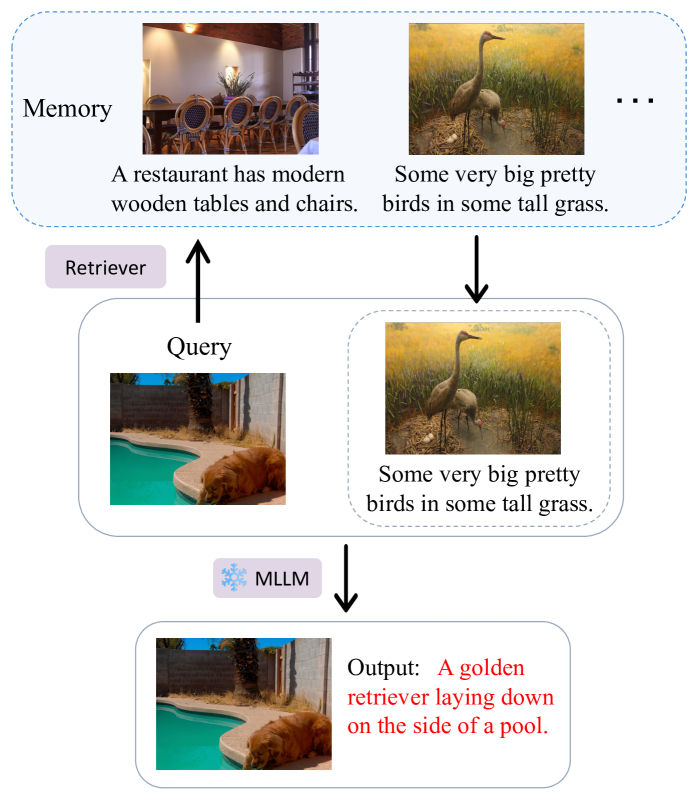
- This paper examines how the textual information in a multimodal learning task affects the retrieval of relevant information.
- The researchers investigate the impact of different types of textual cues on the performance of large language models (LLMs) in retrieving relevant visual and textual information.
- The study provides insights into the role of textual context in enabling LLMs to effectively leverage multimodal data for learning and retrieval.
Plain English Explanation
When we learn, we often use a combination of visual and textual information to understand a topic. For example, when learning about a new animal, we might look at pictures of the animal and read descriptions about its characteristics, habitat, and behavior. This combination of visual and textual information is known as "multimodal" learning.
The researchers in this study wanted to understand how the specific textual information we provide can affect how well a large language model (a type of AI system that can understand and generate human-like text) can retrieve relevant information, both visual and textual, to support our learning. They explored different ways of presenting textual cues, such as providing a brief description or a more detailed explanation, and examined how these cues impacted the model's ability to find and retrieve the information that would be most helpful for learning.
The findings of this study provide insights into how we can design effective multimodal learning experiences that leverage the strengths of both visual and textual information. By understanding the role of textual context, we can create learning materials that help large language models and other AI systems better understand and retrieve the most relevant information to support our learning.
Technical Explanation
The researchers conducted a series of experiments to investigate the impact of textual information on the retrieval of multimodal data by large language models. They used a dataset of images and associated textual descriptions, and trained various LLM-based retrieval models to find the most relevant visual and textual information given different types of textual cues.
The researchers explored several factors, including the length and specificity of the textual descriptions, as well as the inclusion of contextual information beyond just the target concept. They found that more detailed and specific textual cues generally led to better retrieval performance, as the models were able to leverage the additional information to better understand the context and identify the most relevant content.
However, the researchers also observed that the performance of these models was highly dependent on the specific prompts used. Subtle changes in the wording or framing of the textual cues could significantly impact the models' ability to retrieve the most relevant information.
These findings suggest that the way textual information is presented can have a significant impact on the effectiveness of multimodal learning systems, and that careful consideration of the textual context is crucial for [enabling these systems to interpret and detect the most relevant information to support learning.
Critical Analysis
The study provides valuable insights into the role of textual information in multimodal learning, but it also has some limitations that should be considered. The researchers used a relatively narrow dataset focused on a specific domain, which may limit the generalizability of the findings. It would be interesting to see how the results might differ with a more diverse set of multimodal data and learning tasks.
Additionally, the study does not delve deeply into the underlying mechanisms by which the language models process and utilize the textual cues. A more detailed examination of the neural-symbolic interplay in these models could provide further insights into the cognitive processes involved in multimodal learning.
Overall, this study represents an important step in understanding the complex interplay between textual and visual information in the context of machine learning and knowledge representation. The findings underscore the need for continued research in this area to unlock the full potential of multimodal learning systems.
Conclusion
This paper explores the crucial role of textual information in enabling large language models to effectively retrieve and leverage multimodal data for learning. The researchers demonstrate that the specificity and context of the textual cues can significantly impact the models' performance, highlighting the importance of carefully designing the textual components of multimodal learning experiences.
The insights from this study have important implications for the development of advanced AI systems that can seamlessly integrate and utilize multiple modalities of information to support human learning and knowledge acquisition. By understanding the interplay between text and visuals, we can create more effective and personalized learning tools that leverage the strengths of both to deliver optimal educational outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!