InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
2404.06512
2
0

Abstract
The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper introduces InternLM-XComposer2-4KHD, a pioneering large vision-language model that can handle a wide range of image resolutions, from 336 pixels to 4K HD. • The model is designed to work effectively across a diverse set of image resolutions, enabling applications that require processing high-quality visual inputs. • The paper highlights the model's ability to handle complex visual information at different scales, a key capability for real-world vision-language tasks.
Plain English Explanation
The researchers have developed a new large-scale vision-language model called InternLM-XComposer2-4KHD that can work with a wide range of image resolutions, from relatively low-quality 336-pixel images all the way up to high-definition 4K video. This is an important advancement because many real-world applications, such as autonomous vehicles or satellite imagery analysis, require the ability to process high-quality visual inputs. Previous models may have struggled with this, but InternLM-XComposer2-4KHD is designed to handle complex images at different scales effectively. This means the model could be useful for a wide range of real-world applications that need to work with diverse and high-quality visual data.
Technical Explanation
The core innovation of this paper is the development of InternLM-XComposer2-4KHD, a large-scale vision-language model that can effectively process images ranging from 336 pixels up to 4K HD resolution. This is an important advancement over prior models, which may have been limited in the types of visual inputs they could handle.
The key technical details are:
- The model architecture is based on an iterative learning approach, allowing it to learn robust representations from diverse visual inputs.
- The training data includes a wide range of image resolutions, from low-quality 336p to high-quality 4K, enabling the model to generalize across scales.
- Experiments demonstrate that InternLM-XComposer2-4KHD outperforms previous vision-language models on a variety of tasks, especially those requiring processing of high-resolution imagery.
Critical Analysis
The researchers do a thorough job of evaluating InternLM-XComposer2-4KHD across a range of tasks and settings. However, a few potential limitations are worth noting:
- The model was trained on a limited set of image domains, so its performance may not generalize as well to completely novel visual inputs.
- The scalability of the approach to even higher resolutions beyond 4K, such as 8K, is not explored in this work.
- There may be computational or memory constraints that limit the practical deployment of such a large vision-language model in real-world applications.
Overall, this research represents an important step forward in developing large vision-language models capable of handling diverse and high-quality visual inputs. Further research is needed to address the potential limitations and expand the model's capabilities.
Conclusion
The InternLM-XComposer2-4KHD model introduced in this paper is a significant advancement in the field of large-scale vision-language AI. By being able to effectively process images across a wide range of resolutions, from low-quality 336p to high-definition 4K, the model opens up new possibilities for real-world applications that require working with diverse and high-quality visual data. This could have important implications for areas like autonomous vehicles, satellite imagery analysis, and other domains that rely on advanced computer vision capabilities. As the field of large vision-language models continues to evolve, this work represents an important step forward in developing more versatile and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, Wenhai Wang
0
0
In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
5/1/2024
New!Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
Wanting Xu, Yang Liu, Langping He, Xucheng Huang, Ling Jiang
0
0
We introduce Xmodel-VLM, a cutting-edge multimodal vision language model. It is designed for efficient deployment on consumer GPU servers. Our work directly confronts a pivotal industry issue by grappling with the prohibitive service costs that hinder the broad adoption of large-scale multimodal systems. Through rigorous training, we have developed a 1B-scale language model from the ground up, employing the LLaVA paradigm for modal alignment. The result, which we call Xmodel-VLM, is a lightweight yet powerful multimodal vision language model. Extensive testing across numerous classic multimodal benchmarks has revealed that despite its smaller size and faster execution, Xmodel-VLM delivers performance comparable to that of larger models. Our model checkpoints and code are publicly available on GitHub at https://github.com/XiaoduoAILab/XmodelVLM.
5/16/2024
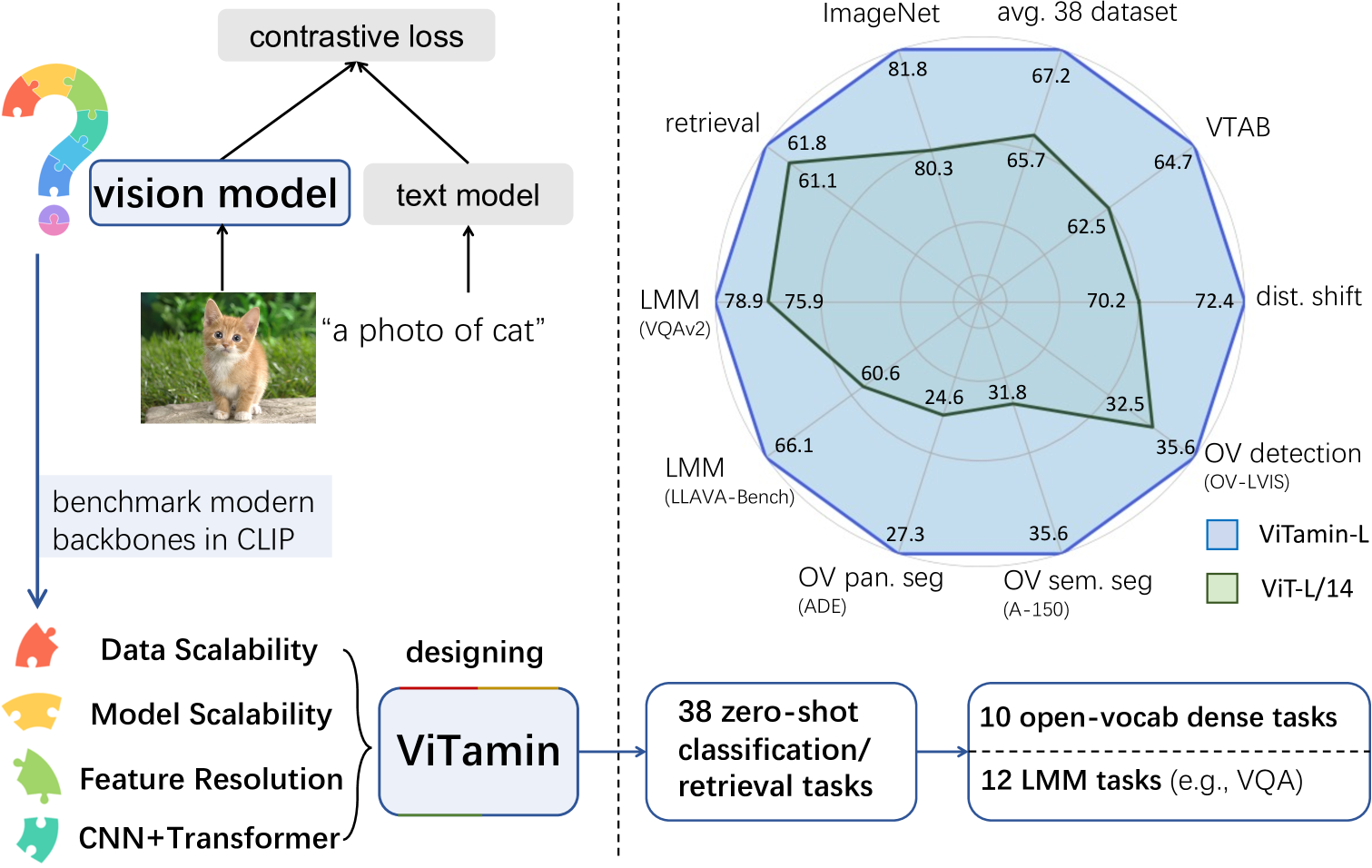
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
0
0
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
4/5/2024
💬
CoLLaVO: Crayon Large Language and Vision mOdel
Byung-Kwan Lee, Beomchan Park, Chae Won Kim, Yong Man Ro
0
0
The remarkable success of Large Language Models (LLMs) and instruction tuning drives the evolution of Vision Language Models (VLMs) towards a versatile general-purpose model. Yet, it remains unexplored whether current VLMs genuinely possess quality object-level image understanding capabilities determined from `what objects are in the image?' or `which object corresponds to a specified bounding box?'. Our findings reveal that the image understanding capabilities of current VLMs are strongly correlated with their zero-shot performance on vision language (VL) tasks. This suggests that prioritizing basic image understanding is crucial for VLMs to excel at VL tasks. To enhance object-level image understanding, we propose Crayon Large Language and Vision mOdel (CoLLaVO), which incorporates instruction tuning with Crayon Prompt as a new visual prompt tuning scheme based on panoptic color maps. Furthermore, we present a learning strategy of Dual QLoRA to preserve object-level image understanding without forgetting it during visual instruction tuning, thereby achieving a significant leap in numerous VL benchmarks in a zero-shot setting.
4/16/2024