Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People

0
💬
Sign in to get full access
Overview
- The paper presents a new benchmark called Memory-Maze to evaluate Visual Language Navigation (VLN) models in the context of guiding blind people.
- The benchmark simulates a maze-like environment and uses natural language instructions obtained from human memory, which are more realistic for the blind navigation scenario compared to previous datasets.
- The authors also propose a new VLN model that uses Large Language Models (LLMs) to parse instructions and generate robot control code, and show it outperforms the existing state-of-the-art model on the Memory-Maze benchmark.
- The paper highlights the importance of evaluating VLN models in real-world scenarios, as they may have different characteristics than traditional datasets.
Plain English Explanation
The paper focuses on developing Visual Language Navigation (VLN) robots that can guide blind people by understanding and executing route instructions provided by sighted passersby. This is a challenging task, as the instructions may contain errors, stutters, and omitted details, unlike the well-structured instructions typically found in existing VLN datasets.
To address this, the researchers created a new benchmark called Memory-Maze, which simulates a maze-like virtual environment and uses natural language instructions collected from human memory, rather than instructions obtained through "thinking out loud" as in previous datasets. The authors conducted studies to collect these realistic instructions from both onsite and online participants, and found that the onsite instructions were more detailed and varied in wording.
The researchers also proposed a new VLN model that uses Large Language Models (LLMs) to parse the instructions and generate Python code to control the robot. This model outperformed the existing state-of-the-art VLN model on the Memory-Maze benchmark, suggesting it is better equipped to handle the challenges of real-world navigation guidance for blind people.
Technical Explanation
The paper presents a new benchmark called Memory-Maze to evaluate Visual Language Navigation (VLN) models in the context of guiding blind people. The benchmark simulates a maze-like virtual environment and uses natural language instructions obtained from human memory, which are more realistic for this scenario compared to previous datasets like Room-to-Room, where instructions were obtained through "thinking out loud."
To collect the natural language instructions, the authors conducted two studies: one with sighted passersby on-site and one with online annotators. The analysis showed that the on-site instructions were more lengthy and contained more varied wording compared to the online instructions.
The authors also propose a new VLN model that uses Large Language Models (LLMs) to parse the instructions and generate Python code to control the robot. This model is designed to better handle the challenges of the blind navigation scenario, where instructions may contain errors, stutters, and omitted details.
The authors show that the existing state-of-the-art VLN model performed suboptimally on the Memory-Maze benchmark, while their proposed method outperformed it by a fair margin. This suggests that the Memory-Maze benchmark presents a more realistic and challenging scenario for VLN models, and that the authors' proposed approach is better suited for guiding blind people in real-world environments.
Critical Analysis
The paper highlights the importance of evaluating VLN models in realistic scenarios, as the characteristics of instructions obtained in traditional datasets may differ from those encountered in practical applications, such as guiding blind people.
The Memory-Maze benchmark is a valuable contribution, as it simulates a more challenging environment and uses natural language instructions obtained from human memory, which are more representative of the types of instructions blind people might receive. However, the authors acknowledge that the virtual environment may still not fully capture the complexity of real-world navigation.
Additionally, while the proposed VLN model using LLMs outperformed the state-of-the-art on the Memory-Maze benchmark, it is unclear how it would perform in a real-world deployment, where factors like sensor noise, physical obstacles, and unexpected events may introduce additional challenges. Further research is needed to assess the robustness and scalability of this approach in realistic settings.
The authors also note that their data collection studies have limitations, such as the small sample size and potential biases in the instructions provided by participants. Expanding the dataset and exploring alternative data collection methods could improve the benchmark's representativeness.
Conclusion
The paper presents a new benchmark, Memory-Maze, and a VLN model using LLMs to address the challenge of guiding blind people through route instructions obtained from human memory. The authors demonstrate that their proposed model outperforms the existing state-of-the-art on the Memory-Maze benchmark, highlighting the importance of evaluating VLN systems in realistic scenarios that capture the complexities of real-world navigation.
The findings of this research suggest that while VLN technology has significant potential to assist blind people, there are still important practical challenges to overcome, such as handling imperfect instructions and adapting to dynamic environments. As the field of VLN and robot navigation continues to evolve, it will be crucial for researchers to carefully consider the real-world requirements and limitations of these systems to ensure they can be effectively deployed to assist people in need.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People
Masaki Kuribayashi, Kohei Uehara, Allan Wang, Daisuke Sato, Simon Chu, Shigeo Morishima
Visual Language Navigation (VLN) powered navigation robots have the potential to guide blind people by understanding and executing route instructions provided by sighted passersby. This capability allows robots to operate in environments that are often unknown a priori. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contain stutters, errors, and omission of details as opposed to those obtained by thinking out loud, such as in the Room-to-Room dataset. However, currently, there is no benchmark that simulates instructions that were obtained from human memory in environments where blind people navigate. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. To collect natural language instructions, we conducted two studies from sighted passersby onsite and annotators online. Our analysis demonstrates that instructions data collected onsite were more lengthy and contained more varied wording. Alongside our benchmark, we propose a VLN model better equipped to handle the scenario. Our proposed VLN model uses Large Language Models (LLM) to parse instructions and generate Python codes for robot control. We further show that the existing state-of-the-art model performed suboptimally on our benchmark. In contrast, our proposed method outperformed the state-of-the-art model by a fair margin. We found that future research should exercise caution when considering VLN technology for practical applications, as real-world scenarios have different characteristics than ones collected in traditional settings.
Read more5/14/2024

0
MC-GPT: Empowering Vision-and-Language Navigation with Memory Map and Reasoning Chains
Zhaohuan Zhan, Lisha Yu, Sijie Yu, Guang Tan
In the Vision-and-Language Navigation (VLN) task, the agent is required to navigate to a destination following a natural language instruction. While learning-based approaches have been a major solution to the task, they suffer from high training costs and lack of interpretability. Recently, Large Language Models (LLMs) have emerged as a promising tool for VLN due to their strong generalization capabilities. However, existing LLM-based methods face limitations in memory construction and diversity of navigation strategies. To address these challenges, we propose a suite of techniques. Firstly, we introduce a method to maintain a topological map that stores navigation history, retaining information about viewpoints, objects, and their spatial relationships. This map also serves as a global action space. Additionally, we present a Navigation Chain of Thoughts module, leveraging human navigation examples to enrich navigation strategy diversity. Finally, we establish a pipeline that integrates navigational memory and strategies with perception and action prediction modules. Experimental results on the REVERIE and R2R datasets show that our method effectively enhances the navigation ability of the LLM and improves the interpretability of navigation reasoning.
Read more8/13/2024

0
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
Read more5/28/2024
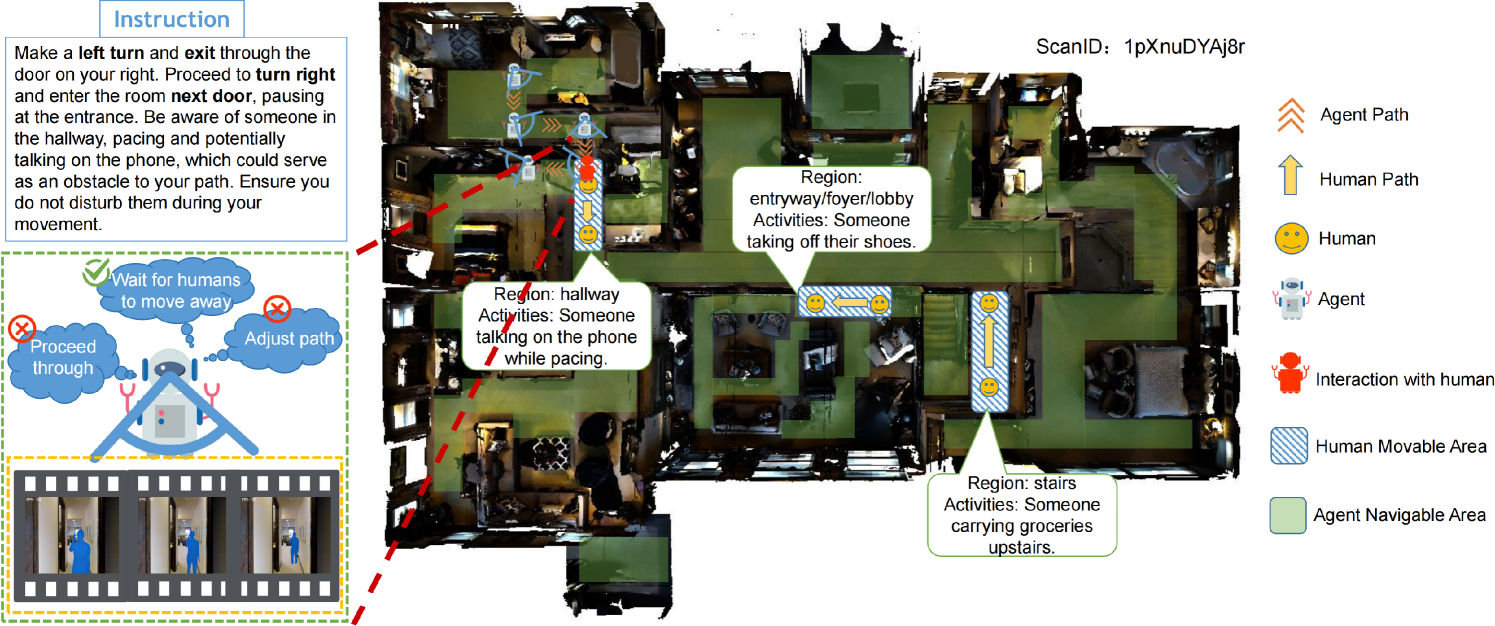
0
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Minghan Li, Heng Li, Zhi-Qi Cheng, Yifei Dong, Yuxuan Zhou, Jun-Yan He, Qi Dai, Teruko Mitamura, Alexander G. Hauptmann
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
Read more7/8/2024