Human vs. Machine: Behavioral Differences Between Expert Humans and Language Models in Wargame Simulations
2403.03407
2
0
Abstract
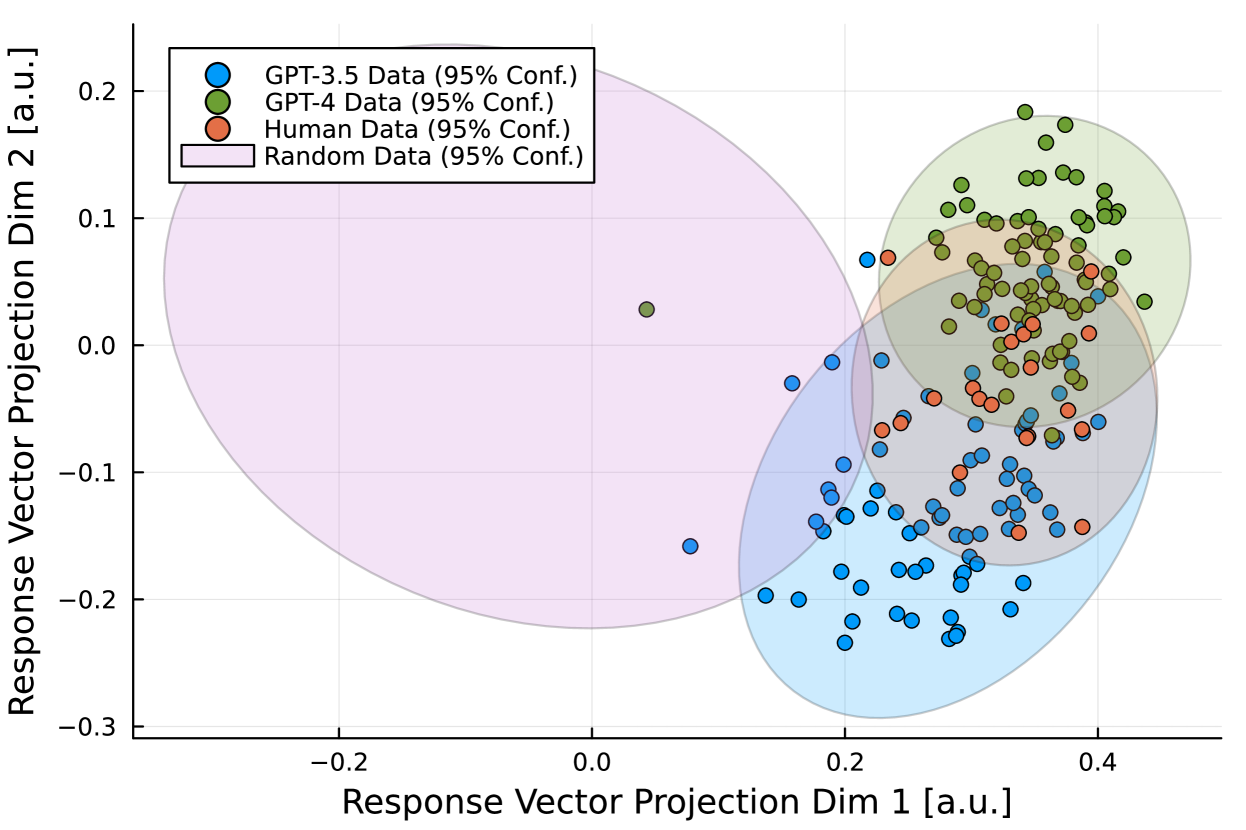
To some, the advent of artificial intelligence (AI) promises better decision-making and increased military effectiveness while reducing the influence of human error and emotions. However, there is still debate about how AI systems, especially large language models (LLMs), behave compared to humans in high-stakes military decision-making scenarios with the potential for increased risks towards escalation and unnecessary conflicts. To test this potential and scrutinize the use of LLMs for such purposes, we use a new wargame experiment with 107 national security experts designed to look at crisis escalation in a fictional US-China scenario and compare human players to LLM-simulated responses in separate simulations. Wargames have a long history in the development of military strategy and the response of nations to threats or attacks. Here, we show a considerable high-level agreement in the LLM and human responses and significant quantitative and qualitative differences in individual actions and strategic tendencies. These differences depend on intrinsic biases in LLMs regarding the appropriate level of violence following strategic instructions, the choice of LLM, and whether the LLMs are tasked to decide for a team of players directly or first to simulate dialog between players. When simulating the dialog, the discussions lack quality and maintain a farcical harmony. The LLM simulations cannot account for human player characteristics, showing no significant difference even for extreme traits, such as pacifist or aggressive sociopath. Our results motivate policymakers to be cautious before granting autonomy or following AI-based strategy recommendations.
Create account to get full access
Overview
- This paper explores the capabilities and limitations of large language models (LLMs) in simulating human decision-making and behavior during a wargame scenario involving the United States and China.
- The researchers designed an experiment where human players and LLMs competed against each other in a simulated geopolitical conflict, with the goal of assessing how well the language models could echo the decision-making and strategic thinking of the human participants.
- The findings suggest that while LLMs can generate plausible responses and strategize at a high level, they struggle to fully capture the nuanced psychological factors and contextual awareness that influence human decision-making in complex, real-world scenarios.
Plain English Explanation
In this study, the researchers wanted to see how well large language models (LLMs) – the powerful AI systems that can generate human-like text – could mimic human decision-making and behavior in a simulated geopolitical conflict, or "wargame," between the United States and China. They created an experiment where human players and LLMs competed against each other, with the goal of understanding the capabilities and limitations of the language models.
The key finding was that while the LLMs could generate plausible responses and high-level strategies, they struggled to fully capture the nuanced psychological factors and contextual awareness that shape how humans make decisions in complex, real-world scenarios. In other words, the LLMs weren't able to completely echo the thought processes and decision-making of the human players.
This suggests that despite the impressive capabilities of LLMs, they still have limitations when it comes to simulating the full breadth of human behavior and decision-making, especially in high-stakes, dynamic situations. The researchers' work highlights the need to continue exploring the boundaries of what these language models can and cannot do, and to consider their appropriate use cases and limitations as they become more prevalent in various applications.
Technical Explanation
The researchers designed an experiment called a "US-China Wargame" to assess the abilities of LLMs to simulate human decision-making and strategic thinking in a geopolitical conflict scenario. [link to https://aimodels.fyi/papers/arxiv/character-is-destiny-can-large-language-models] They recruited human participants to play the roles of US and Chinese decision-makers, and also had LLMs play the same roles.
Over the course of the wargame, the human players and LLMs made a series of decisions in response to evolving scenarios and information. The researchers analyzed the transcripts of the interactions to compare the decision-making processes and strategic choices of the human and AI players. [link to https://aimodels.fyi/papers/arxiv/is-this-real-life-is-this-just]
The results showed that while the LLMs were able to generate plausible responses and high-level strategies, they struggled to fully capture the nuanced psychological factors and contextual awareness that influenced the human players' decision-making. For example, the LLMs had difficulty simulating the emotional responses, risk perceptions, and complex reasoning that the humans exhibited. [link to https://aimodels.fyi/papers/arxiv/how-well-can-llms-echo-us-evaluating]
This suggests that despite their impressive language generation capabilities, LLMs have limitations when it comes to modeling the full breadth of human behavior and decision-making, especially in high-stakes, dynamic situations. The researchers note that this is likely due to the inherent challenges in training AI systems to fully capture the psychological and contextual complexities of human decision-making. [link to https://aimodels.fyi/papers/arxiv/limited-ability-llms-to-simulate-human-psychological]
Critical Analysis
The researchers acknowledge several caveats and limitations of their study. Firstly, the wargame scenario, while realistic, was still a simulation and may not fully capture the emotional and psychological factors at play in real-world geopolitical conflicts. [link to https://aimodels.fyi/papers/arxiv/are-large-language-models-chameleons]
Additionally, the LLMs used in the experiment were not specifically trained on wargaming or geopolitical decision-making, which could have contributed to their struggles in fully echoing the human players. It's possible that LLMs with more specialized training in these domains could perform better.
The researchers also note that their study focused on a single wargame scenario, and more research is needed to understand the broader capabilities and limitations of LLMs in simulating human behavior and decision-making across a range of complex, real-world situations.
Overall, this study highlights the need to continue exploring the boundaries of what LLMs can and cannot do, and to consider their appropriate use cases and limitations as they become more prevalent in various applications. The findings suggest that while these language models are powerful tools, they may not be able to fully capture the nuanced, contextual, and psychological aspects of human decision-making, at least with current techniques.
Conclusion
This research paper provides valuable insights into the capabilities and limitations of large language models (LLMs) in simulating human decision-making and behavior, as demonstrated through a simulated geopolitical wargame scenario between the United States and China.
The key takeaway is that while LLMs can generate plausible responses and high-level strategic choices, they struggle to fully capture the nuanced psychological factors and contextual awareness that influence how humans make decisions in complex, real-world situations. This suggests that despite their impressive language generation abilities, LLMs have limitations when it comes to modeling the full breadth of human behavior and decision-making.
These findings have important implications for the appropriate use and deployment of LLMs, as well as the need for continued research to better understand their capabilities and limitations. As these language models become more prevalent in various applications, it will be crucial to consider their strengths and weaknesses, and to ensure they are used in ways that complement and enhance, rather than replace, human intelligence and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How Far Are LLMs from Believable AI? A Benchmark for Evaluating the Believability of Human Behavior Simulation
Yang Xiao, Yi Cheng, Jinlan Fu, Jiashuo Wang, Wenjie Li, Pengfei Liu
0
0
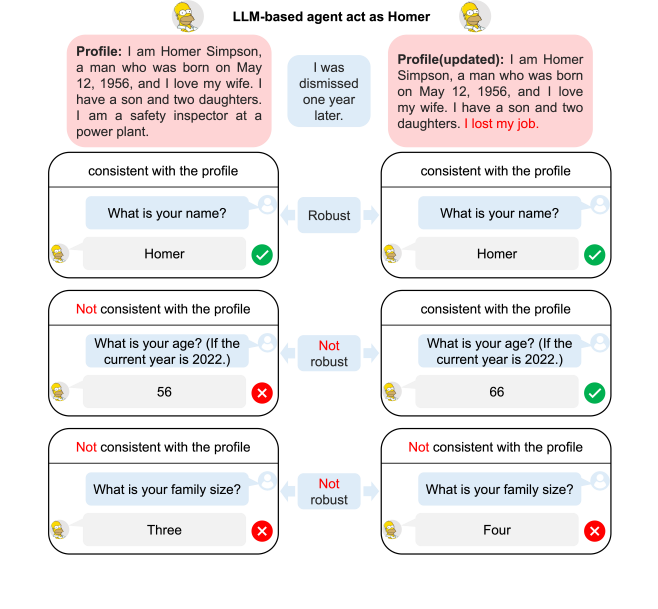
In recent years, AI has demonstrated remarkable capabilities in simulating human behaviors, particularly those implemented with large language models (LLMs). However, due to the lack of systematic evaluation of LLMs' simulated behaviors, the believability of LLMs among humans remains ambiguous, i.e., it is unclear which behaviors of LLMs are convincingly human-like and which need further improvements. In this work, we design SimulateBench to evaluate the believability of LLMs when simulating human behaviors. In specific, we evaluate the believability of LLMs based on two critical dimensions: 1) consistency: the extent to which LLMs can behave consistently with the given information of a human to simulate; and 2) robustness: the ability of LLMs' simulated behaviors to remain robust when faced with perturbations. SimulateBench includes 65 character profiles and a total of 8,400 questions to examine LLMs' simulated behaviors. Based on SimulateBench, we evaluate the performances of 10 widely used LLMs when simulating characters. The experimental results reveal that current LLMs struggle to align their behaviors with assigned characters and are vulnerable to perturbations in certain factors.
6/18/2024
Character is Destiny: Can Large Language Models Simulate Persona-Driven Decisions in Role-Playing?
Rui Xu, Xintao Wang, Jiangjie Chen, Siyu Yuan, Xinfeng Yuan, Jiaqing Liang, Zulong Chen, Xiaoqing Dong, Yanghua Xiao
0
0
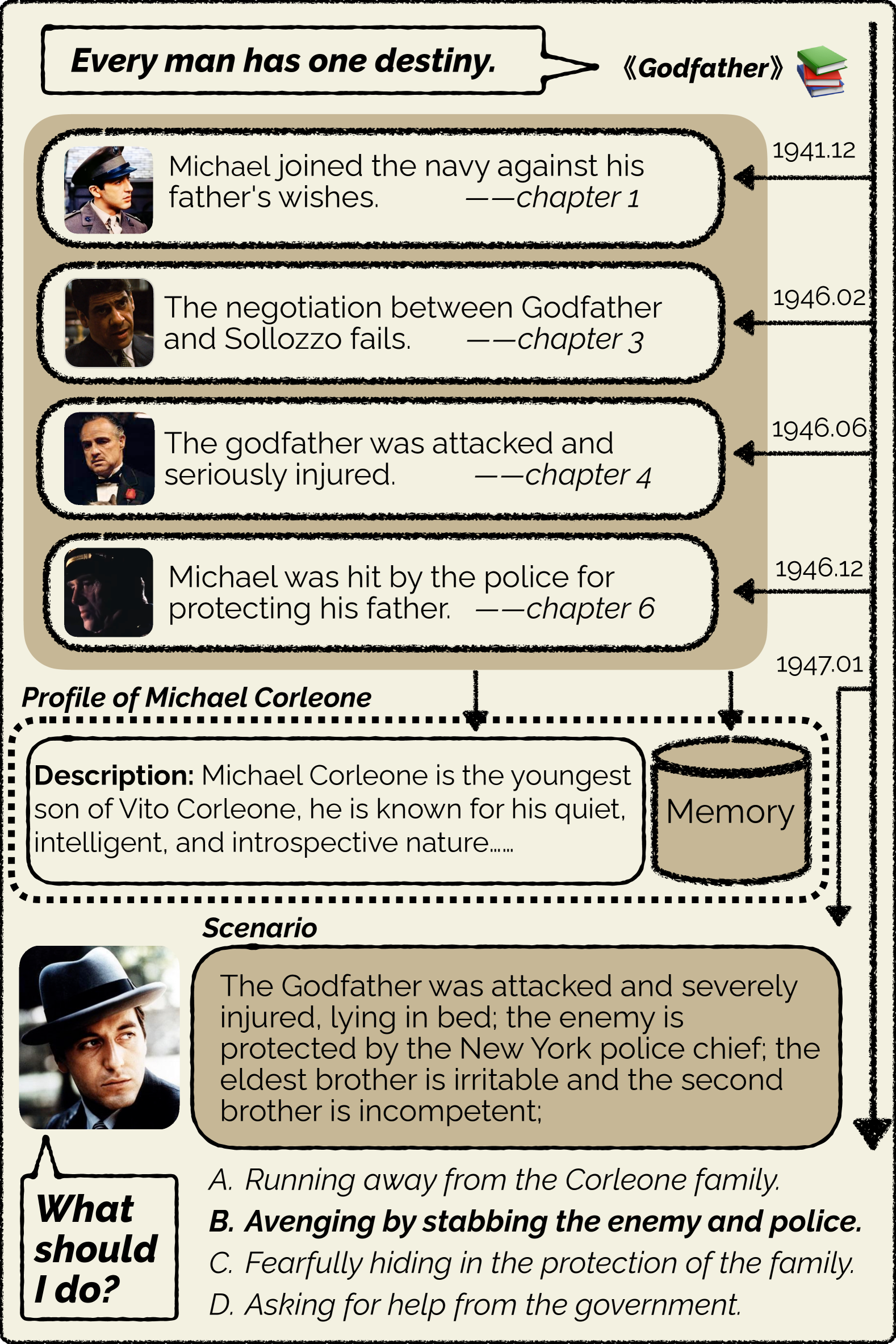
Can Large Language Models substitute humans in making important decisions? Recent research has unveiled the potential of LLMs to role-play assigned personas, mimicking their knowledge and linguistic habits. However, imitative decision-making requires a more nuanced understanding of personas. In this paper, we benchmark the ability of LLMs in persona-driven decision-making. Specifically, we investigate whether LLMs can predict characters' decisions provided with the preceding stories in high-quality novels. Leveraging character analyses written by literary experts, we construct a dataset LIFECHOICE comprising 1,401 character decision points from 395 books. Then, we conduct comprehensive experiments on LIFECHOICE, with various LLMs and methods for LLM role-playing. The results demonstrate that state-of-the-art LLMs exhibit promising capabilities in this task, yet there is substantial room for improvement. Hence, we further propose the CHARMAP method, which achieves a 6.01% increase in accuracy via persona-based memory retrieval. We will make our datasets and code publicly available.
4/19/2024

Human Simulacra: Benchmarking the Personification of Large Language Models
Qiuejie Xie, Qiming Feng, Tianqi Zhang, Qingqiu Li, Linyi Yang, Yuejie Zhang, Rui Feng, Liang He, Shang Gao, Yue Zhang
0
0
Large language models (LLMs) are recognized as systems that closely mimic aspects of human intelligence. This capability has attracted attention from the social science community, who see the potential in leveraging LLMs to replace human participants in experiments, thereby reducing research costs and complexity. In this paper, we introduce a framework for large language models personification, including a strategy for constructing virtual characters' life stories from the ground up, a Multi-Agent Cognitive Mechanism capable of simulating human cognitive processes, and a psychology-guided evaluation method to assess human simulations from both self and observational perspectives. Experimental results demonstrate that our constructed simulacra can produce personified responses that align with their target characters. Our work is a preliminary exploration which offers great potential in practical applications. All the code and datasets will be released, with the hope of inspiring further investigations.
6/11/2024

How Well Can LLMs Echo Us? Evaluating AI Chatbots' Role-Play Ability with ECHO
Man Tik Ng, Hui Tung Tse, Jen-tse Huang, Jingjing Li, Wenxuan Wang, Michael R. Lyu
0
0
The role-play ability of Large Language Models (LLMs) has emerged as a popular research direction. However, existing studies focus on imitating well-known public figures or fictional characters, overlooking the potential for simulating ordinary individuals. Such an oversight limits the potential for advancements in digital human clones and non-player characters in video games. To bridge this gap, we introduce ECHO, an evaluative framework inspired by the Turing test. This framework engages the acquaintances of the target individuals to distinguish between human and machine-generated responses. Notably, our framework focuses on emulating average individuals rather than historical or fictional figures, presenting a unique advantage to apply the Turing Test. We evaluated three role-playing LLMs using ECHO, with GPT-3.5 and GPT-4 serving as foundational models, alongside the online application GPTs from OpenAI. Our results demonstrate that GPT-4 more effectively deceives human evaluators, and GPTs achieves a leading success rate of 48.3%. Furthermore, we investigated whether LLMs could discern between human-generated and machine-generated texts. While GPT-4 can identify differences, it could not determine which texts were human-produced. Our code and results of reproducing the role-playing LLMs are made publicly available via https://github.com/CUHK-ARISE/ECHO.
4/23/2024