HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels

0
🖼️
Sign in to get full access
Overview
- This paper proposes a new method called Hybrid CIR (HyCIR) to improve zero-shot Composed Image Retrieval (ZS-CIR) performance.
- ZS-CIR aims to retrieve images based on a query image with text, without using expensive triplet-labeled training datasets.
- The authors introduce a new label Synthesis pipeline for CIR (SynCir) to generate synthetic CIR triplets, using only unlabeled images.
- HyCIR uses a hybrid training strategy that combines ZS-CIR supervision and synthetic CIR triplets to improve performance.
Plain English Explanation
The paper focuses on a task called Composed Image Retrieval (CIR), where the goal is to find relevant images based on a query that includes both an image and some text. Current zero-shot CIR (ZS-CIR) methods try to solve this problem without using expensive labeled training data, but they still lag behind methods that do use that data.
To address this, the authors propose a new approach called Hybrid CIR (HyCIR). The key idea is to use a technique called SynCir to automatically generate synthetic training data, in the form of image-text pairs. This synthetic data is then combined with the existing zero-shot supervision to train a more powerful CIR model.
The SynCir process works by first finding visually similar image pairs, then generating relevant text descriptions for those pairs using language models. This creates realistic-looking CIR training examples without the need for manual labeling.
By using both the synthetic data and the original zero-shot training, the HyCIR model is able to learn a better image-to-text mapping that is tailored for the CIR task. This allows it to outperform previous zero-shot CIR methods on common benchmarks, getting state-of-the-art results.
Technical Explanation
The paper introduces a new approach called Hybrid CIR (HyCIR) to improve the performance of zero-shot Composed Image Retrieval (ZS-CIR). ZS-CIR aims to retrieve relevant images given a query containing both an image and some text, without requiring expensive triplet-labeled training data.
The key innovation is the SynCir pipeline, which automatically generates synthetic CIR training triplets from unlabeled image data. First, visually similar image pairs are extracted. Then, relevant text descriptions are generated for each pair using a vision-language model and a large language model (LLM). Finally, the data is filtered based on semantic similarity to create high-quality synthetic triplets.
To leverage this synthetic data, HyCIR uses a hybrid training strategy. It combines the original ZS-CIR supervision, which uses only the query image and text, with additional training on the synthetic CIR triplets. Two forms of contrastive learning are used: one to learn a general image-to-text mapping from large-scale unlabeled data, and another to specialize that mapping for the CIR task using the synthetic triplets.
The authors evaluate HyCIR on common CIR benchmarks like CIRR and CIRCO, and show that it achieves state-of-the-art zero-shot performance, outperforming previous ZS-CIR methods. This demonstrates the value of automatically generating synthetic training data to bridge the gap between zero-shot and fully-supervised CIR approaches.
Critical Analysis
The paper presents a clever and effective approach to improving zero-shot Composed Image Retrieval (ZS-CIR) performance by leveraging automatically generated synthetic training data. The SynCir pipeline for creating these synthetic triplets is a key technical contribution, as it allows the authors to sidestep the need for expensive manual labeling.
That said, the authors acknowledge that there is still a gap between the performance of ZS-CIR and fully-supervised CIR methods. While HyCIR represents a significant step forward, further research may be needed to completely close this gap. Additionally, the synthetic data generation process, while effective, could potentially introduce biases or other issues that impact model performance.
It would also be interesting to see how HyCIR compares to other few-shot or semi-supervised techniques for CIR that aim to reduce reliance on fully-labeled training data. Exploring the trade-offs between different approaches in this space could yield additional insights.
Overall, the HyCIR method represents an important advance in zero-shot Composed Image Retrieval, and the authors' thoughtful approach to leveraging synthetic data is a model for future work in this area.
Conclusion
This paper proposes a new Hybrid CIR (HyCIR) method that uses automatically generated synthetic training data to boost the performance of zero-shot Composed Image Retrieval (ZS-CIR). By combining ZS-CIR supervision with synthetic CIR triplets created through the SynCir pipeline, HyCIR is able to achieve state-of-the-art zero-shot results on standard benchmarks.
The key innovation is the ability to sidestep the need for expensive manually-labeled training data, which has been a major limitation of previous CIR approaches. This work demonstrates the power of leveraging large language models and other recent advances in AI to automatically generate high-quality synthetic training data, paving the way for more efficient and effective Composed Image Retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Yingying Jiang, Hanchao Jia, Xiaobing Wang, Peng Hao
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.
Read more7/10/2024

0
Zero-shot Composed Image Retrieval Considering Query-target Relationship Leveraging Masked Image-text Pairs
Huaying Zhang, Rintaro Yanagi, Ren Togo, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel zero-shot composed image retrieval (CIR) method considering the query-target relationship by masked image-text pairs. The objective of CIR is to retrieve the target image using a query image and a query text. Existing methods use a textual inversion network to convert the query image into a pseudo word to compose the image and text and use a pre-trained visual-language model to realize the retrieval. However, they do not consider the query-target relationship to train the textual inversion network to acquire information for retrieval. In this paper, we propose a novel zero-shot CIR method that is trained end-to-end using masked image-text pairs. By exploiting the abundant image-text pairs that are convenient to obtain with a masking strategy for learning the query-target relationship, it is expected that accurate zero-shot CIR using a retrieval-focused textual inversion network can be realized. Experimental results show the effectiveness of the proposed method.
Read more6/28/2024

0
Pseudo-triplet Guided Few-shot Composed Image Retrieval
Bohan Hou, Haoqiang Lin, Haokun Wen, Meng Liu, Xuemeng Song
Composed Image Retrieval (CIR) is a challenging task that aims to retrieve the target image based on a multimodal query, i.e., a reference image and its corresponding modification text. While previous supervised or zero-shot learning paradigms all fail to strike a good trade-off between time-consuming annotation cost and retrieval performance, recent researchers introduced the task of few-shot CIR (FS-CIR) and proposed a textual inversion-based network based on pretrained CLIP model to realize it. Despite its promising performance, the approach suffers from two key limitations: insufficient multimodal query composition training and indiscriminative training triplet selection. To address these two limitations, in this work, we propose a novel two-stage pseudo triplet guided few-shot CIR scheme, dubbed PTG-FSCIR. In the first stage, we employ a masked training strategy and advanced image caption generator to construct pseudo triplets from pure image data to enable the model to acquire primary knowledge related to multimodal query composition. In the second stage, based on active learning, we design a pseudo modification text-based query-target distance metric to evaluate the challenging score for each unlabeled sample. Meanwhile, we propose a robust top range-based random sampling strategy according to the 3-$sigma$ rule in statistics, to sample the challenging samples for fine-tuning the pretrained model. Notably, our scheme is plug-and-play and compatible with any existing supervised CIR models. We tested our scheme across three backbones on three public datasets (i.e., FashionIQ, CIRR, and Birds-to-Words), achieving maximum improvements of 26.4%, 25.5% and 21.6% respectively, demonstrating our scheme's effectiveness.
Read more7/9/2024
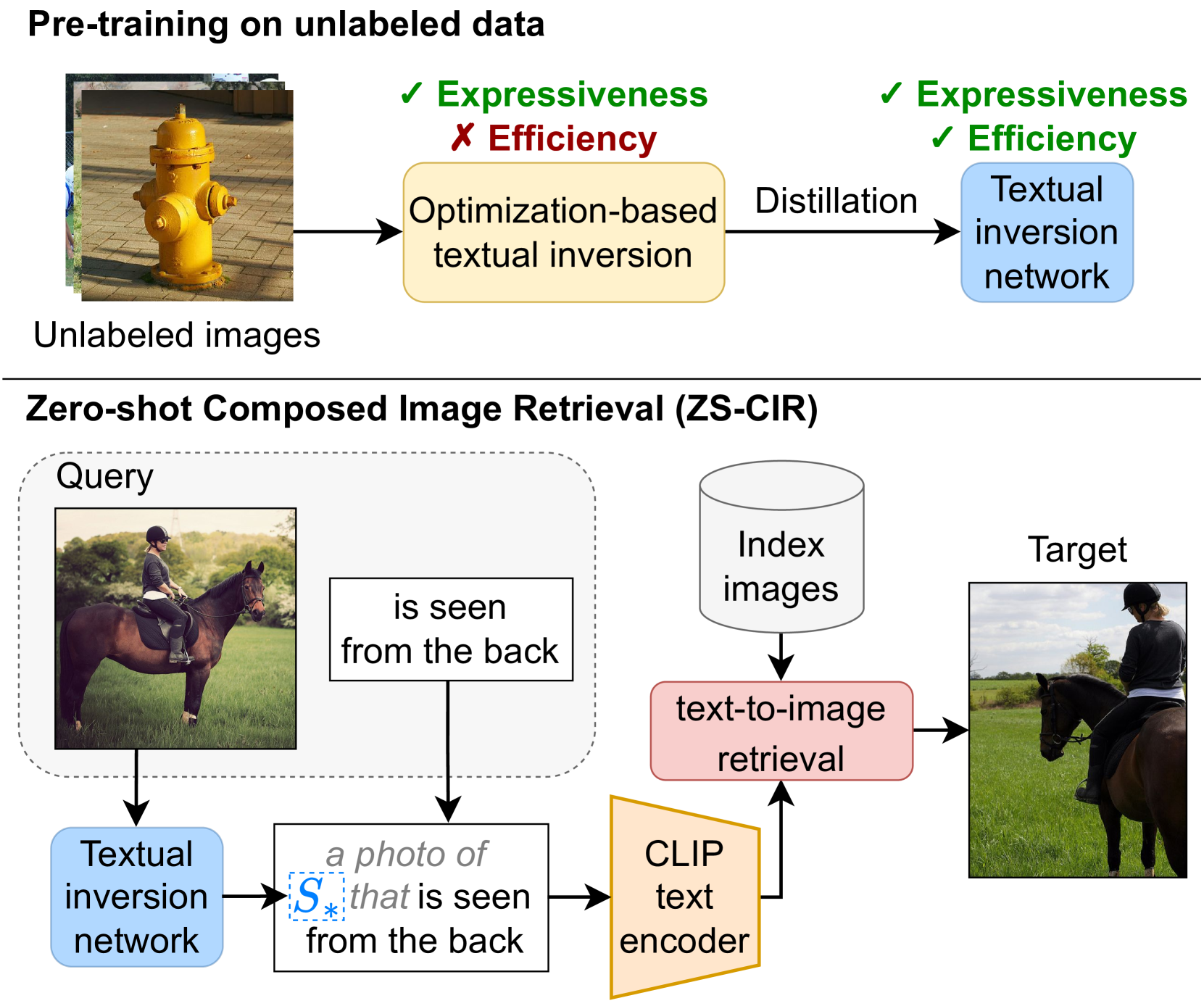
0
iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
Lorenzo Agnolucci, Alberto Baldrati, Marco Bertini, Alberto Del Bimbo
Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Read more5/7/2024