Reducing Task Discrepancy of Text Encoders for Zero-Shot Composed Image Retrieval

0
Sign in to get full access
Overview
- This paper explores how to reduce the task discrepancy between text encoders and image encoders for zero-shot composed image retrieval.
- Zero-shot composed image retrieval involves finding images that match a description that combines multiple concepts, without having seen those exact combinations during training.
- The authors propose a novel training approach to align the text and image encoders, which helps them perform better on this task.
Plain English Explanation
The paper focuses on a problem called "zero-shot composed image retrieval." This means trying to find images that match a description that combines multiple concepts, even if you've never seen those exact combinations before during training. For example, you might want to find an image of "a blue car with a red stripe," even if you've only ever seen images of blue cars and red cars separately.
The key challenge is that text encoders (models that understand language) and image encoders (models that understand visual information) are often trained separately, so they don't always "speak the same language." The authors propose a new training approach to better align these two types of models, so they can work together more effectively for this zero-shot composed image retrieval task.
The core idea is to find a way to make the text encoder and image encoder learn complementary representations, so they can more accurately match text descriptions to the corresponding images, even when the descriptions involve novel combinations of concepts. This allows the system to perform well on this challenging zero-shot task.
Technical Explanation
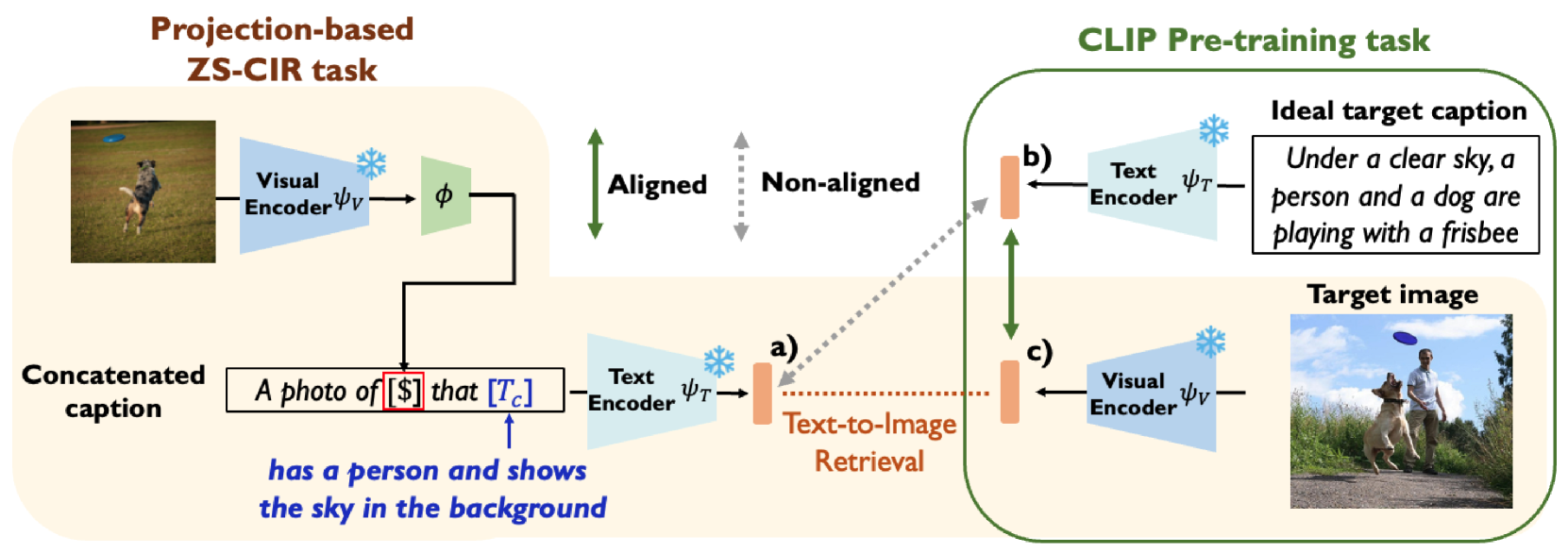
The paper tackles the problem of zero-shot composed image retrieval, where the goal is to retrieve relevant images given a textual description that combines multiple concepts, without having seen those exact combinations during training.
To address this challenge, the authors propose a novel training approach called "Reducing Task Discrepancy" (RTD). The key insight is that text encoders and image encoders are often trained separately, leading to a "task discrepancy" where they don't fully align in their representations.
The RTD method aims to reduce this discrepancy by introducing a new training objective that encourages the text encoder and image encoder to learn complementary representations. Specifically, they introduce an auxiliary loss that pushes the encoders to match not just individual concepts, but also the relationships between them.
This is evaluated on several zero-shot composed image retrieval benchmarks, including COVR and ComCLIP. The results show that the RTD method outperforms previous approaches, demonstrating its effectiveness at reducing the task discrepancy and enabling better zero-shot performance.
Critical Analysis
The paper makes a valuable contribution by addressing the important challenge of zero-shot composed image retrieval. By focusing on reducing the task discrepancy between text and image encoders, the authors develop a practical solution that can be applied to existing models.
One potential limitation is that the RTD method relies on additional training of the encoders, which may not always be feasible or desirable, especially for large pre-trained models. The authors acknowledge this and suggest that future work could explore more efficient ways to align the encoders.
Additionally, the paper does not extensively explore the generalization capabilities of the RTD method. It would be interesting to see how it performs on more diverse or complex composition tasks, or how it scales to larger datasets and model sizes.
Finally, the paper could benefit from a deeper discussion of the underlying reasons for the task discrepancy between text and image encoders. A more comprehensive understanding of the factors contributing to this issue could lead to even more effective solutions in the future.
Conclusion
This paper presents a novel training approach called "Reducing Task Discrepancy" (RTD) to address the challenge of zero-shot composed image retrieval. By better aligning the representations of text encoders and image encoders, the RTD method demonstrates improved performance on several benchmark tasks.
The key contribution of this work is the recognition that the task discrepancy between these two types of models is a fundamental challenge that must be addressed for effective zero-shot reasoning. The RTD approach provides a practical solution that can be applied to existing models, with the potential to drive further advancements in this important area of artificial intelligence research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reducing Task Discrepancy of Text Encoders for Zero-Shot Composed Image Retrieval
Jaeseok Byun, Seokhyeon Jeong, Wonjae Kim, Sanghyuk Chun, Taesup Moon
Composed Image Retrieval (CIR) aims to retrieve a target image based on a reference image and conditioning text, enabling controllable searches. Due to the expensive dataset construction cost for CIR triplets, a zero-shot (ZS) CIR setting has been actively studied to eliminate the need for human-collected triplet datasets. The mainstream of ZS-CIR employs an efficient projection module that projects a CLIP image embedding to the CLIP text token embedding space, while fixing the CLIP encoders. Using the projected image embedding, these methods generate image-text composed features by using the pre-trained text encoder. However, their CLIP image and text encoders suffer from the task discrepancy between the pre-training task (text $leftrightarrow$ image) and the target CIR task (image + text $leftrightarrow$ image). Conceptually, we need expensive triplet samples to reduce the discrepancy, but we use cheap text triplets instead and update the text encoder. To that end, we introduce the Reducing Task Discrepancy of text encoders for Composed Image Retrieval (RTD), a plug-and-play training scheme for the text encoder that enhances its capability using a novel target-anchored text contrastive learning. We also propose two additional techniques to improve the proposed learning scheme: a hard negatives-based refined batch sampling strategy and a sophisticated concatenation scheme. Integrating RTD into the state-of-the-art projection-based ZS-CIR methods significantly improves performance across various datasets and backbones, demonstrating its efficiency and generalizability.
Read more6/14/2024

0
Zero-shot Composed Image Retrieval Considering Query-target Relationship Leveraging Masked Image-text Pairs
Huaying Zhang, Rintaro Yanagi, Ren Togo, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel zero-shot composed image retrieval (CIR) method considering the query-target relationship by masked image-text pairs. The objective of CIR is to retrieve the target image using a query image and a query text. Existing methods use a textual inversion network to convert the query image into a pseudo word to compose the image and text and use a pre-trained visual-language model to realize the retrieval. However, they do not consider the query-target relationship to train the textual inversion network to acquire information for retrieval. In this paper, we propose a novel zero-shot CIR method that is trained end-to-end using masked image-text pairs. By exploiting the abundant image-text pairs that are convenient to obtain with a masking strategy for learning the query-target relationship, it is expected that accurate zero-shot CIR using a retrieval-focused textual inversion network can be realized. Experimental results show the effectiveness of the proposed method.
Read more6/28/2024
0
iSEARLE: Improving Textual Inversion for Zero-Shot Composed Image Retrieval
Lorenzo Agnolucci, Alberto Baldrati, Marco Bertini, Alberto Del Bimbo
Given a query consisting of a reference image and a relative caption, Composed Image Retrieval (CIR) aims to retrieve target images visually similar to the reference one while incorporating the changes specified in the relative caption. The reliance of supervised methods on labor-intensive manually labeled datasets hinders their broad applicability. In this work, we introduce a new task, Zero-Shot CIR (ZS-CIR), that addresses CIR without the need for a labeled training dataset. We propose an approach named iSEARLE (improved zero-Shot composEd imAge Retrieval with textuaL invErsion) that involves mapping the visual information of the reference image into a pseudo-word token in CLIP token embedding space and combining it with the relative caption. To foster research on ZS-CIR, we present an open-domain benchmarking dataset named CIRCO (Composed Image Retrieval on Common Objects in context), the first CIR dataset where each query is labeled with multiple ground truths and a semantic categorization. The experimental results illustrate that iSEARLE obtains state-of-the-art performance on three different CIR datasets -- FashionIQ, CIRR, and the proposed CIRCO -- and two additional evaluation settings, namely domain conversion and object composition. The dataset, the code, and the model are publicly available at https://github.com/miccunifi/SEARLE.
Read more5/7/2024
🖼️
0
HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Yingying Jiang, Hanchao Jia, Xiaobing Wang, Peng Hao
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.
Read more7/10/2024